2023年4月4日
Question 11: prepend是什么意思?
From GPT.
“prepend” 是一个英语单词,意思是在某个序列或列表的开头添加元素或字符串。在编程语言中,”prepend” 常用于在数组、列表或字符串的开头添加一个元素或字符串。例如,在Python中,可以使用列表的insert()方法或字符串的加号运算符来在开头添加元素或字符串。
From Olu.
prepend vt. 预先考虑;预谋
Question 10: Pytorch matmul是什么操作?
From https://pytorch.org/docs/stable/generated/torch.matmul.html
是矩阵乘法,支持batch矩阵乘法。一维输入时候是向量的点乘操作,逐个元素相乘并得到结果。
Question 9: Pytorch的hook是什么操作?
From pytorch中的钩子(Hook)有何作用? - 知乎用户的回答 - 知乎 https://www.zhihu.com/question/61044004/answer/183682138
用来保存中间变量的梯度。
From https://www.cnblogs.com/sddai/p/14412250.html
UserWarning: Using a non-full backward hook when the forward contains multiple autograd Nodes is deprecated and will be removed in future versions. This hook will be missing some grad_input. Please use register_full_backward_hook to get the documented behavior. warnings.warn(“Using a non-full backward hook when the forward contains multiple autograd Nodes “
关于文章中提到register_backward_hook只能输出fc2的input和output,目前(2023年4月4日)的版本里,已经有register_full_backward_hook,可以获得完整Module的输入输出。 修改后的代码为:
model = Model()
model.register_full_backward_hook(hook_fn_backward)
修改后的输出为:
In the hook_fn_backward
Model(
(fc1): Linear(in_features=3, out_features=4, bias=True)
(relu1): ReLU()
(fc2): Linear(in_features=4, out_features=1, bias=True)
)
grad_output (tensor([[1.]]),)
grad_input (tensor([[22., 26., 30.]]),)
==========Saved inputs and outputs==========
grad output: (tensor([[1.]]),)
grad input: (tensor([[22., 26., 30.]]),)
Question 8: weight_norm是什么意思?
weight_norm是arxiv: 1602.007868文章提出的将网络权重再次参数化的方法,分解为方向和幅值(范数),分别是weight_v和weight_g,dim指求取范数、幅值的维度,dim=k的维度不会发生变化,dim=None会在整体权值矩阵上求取范数。
Question 15: Softplus里面的beta是什么意思?
nn.Modules.activation.py
class Softplus(Module):
r"""Applies the element-wise function:
.. math::
\text{Softplus}(x) = \frac{1}{\beta} * \log(1 + \exp(\beta * x))
SoftPlus is a smooth approximation to the ReLU function and can be used
to constrain the output of a machine to always be positive.
For numerical stability the implementation reverts to the linear function
when :math:`input \times \beta > threshold`.
Args:
beta: the :math:`\beta` value for the Softplus formulation. Default: 1
threshold: values above this revert to a linear function. Default: 20
Shape:
- Input: :math:`(N, *)` where `*` means, any number of additional
dimensions
- Output: :math:`(N, *)`, same shape as the input
.. image:: ../scripts/activation_images/Softplus.png
Examples::
>>> m = nn.Softplus()
>>> input = torch.randn(2)
>>> output = m(input)
"""
__constants__ = ['beta', 'threshold']
beta: int
threshold: int
def __init__(self, beta: int = 1, threshold: int = 20) -> None:
super(Softplus, self).__init__()
self.beta = beta
self.threshold = threshold
def forward(self, input: Tensor) -> Tensor:
return F.softplus(input, self.beta, self.threshold)
def extra_repr(self) -> str:
return 'beta={}, threshold={}'.format(self.beta, self.threshold)
\(\text{Softplus}(x) = \frac{1}{\beta} * \log(1 + \exp(\beta * x))\) 我还是要说一句,GPT无敌。
From GPT.
Beta参数的大小将直接影响Softplus函数的形状。较小的Beta值会产生更平滑的曲线,而较大的Beta值会导致曲线在原点处有更快的增长率。
具体来说,当Beta=1时,Softplus函数的曲线是一个类似于ReLU函数的“平滑化”版本,随着输入x的增加,输出值逐渐增加并最终趋近于无限大。
当Beta增加时,Softplus函数的曲线在原点处的增长率会变得更加陡峭,这意味着Softplus函数对小于零的输入值的响应更加敏感。这种形状在某些神经网络中很有用,可以使模型对负输入有更大的响应,从而提高其表现力。
这将绘制Softplus函数及其导数的图形。可以看出,导数在x<0时是较小的正值,在x>0时则接近于1,这与Softplus函数的形状有关。
# 这段代码由GPT编写。
# 以下是绘制左图和右图,分别展示beta=1、20时的Softplus函数及其导数的代码块:-GPT
import numpy as np
import matplotlib.pyplot as plt
def softplus(x, beta=1):
return 1/beta * np.log(1 + np.exp(beta*x))
def softplus_derivative(x, beta=1):
return 1/(1 + np.exp(-beta*x))
x = np.linspace(-10, 10, 100)
# Beta=1
beta_1 = 1
y_1 = softplus(x, beta_1)
y_prime_1 = softplus_derivative(x, beta_1)
plt.subplot(1, 2, 1)
plt.plot(x, y_1, label='Softplus(x)')
plt.plot(x, y_prime_1, label='Softplus\'(x)')
plt.title(f'Softplus Function and Its Derivative (Beta={beta_1})')
plt.xlabel('x')
plt.legend()
# Beta=20
beta_20 = 20
y_20 = softplus(x, beta_20)
y_prime_20 = softplus_derivative(x, beta_20)
plt.subplot(1, 2, 2)
plt.plot(x, y_20, label='Softplus(x)')
plt.plot(x, y_prime_20, label='Softplus\'(x)')
plt.title(f'Softplus Function and Its Derivative (Beta={beta_20})')
plt.xlabel('x')
plt.legend()
plt.show()
# 这个代码块将绘制两个图形,左图中展示Beta=1时的Softplus函数及其导数,右图中展示Beta=20时的Softplus函数及其导数。两个图形将同时出现在同一个窗口中以方便比较。-GPT

2023年4月5日
Question 22: 什么是finite differences?
From gpt3.
有限差分(Finite Differences)是求解数值微积分问题的一种方法,通常用于计算函数的导数。它通过对函数在某个点进行一些有限的差分来近似计算导数。具体而言,给定一个函数$f(x)$和一个点$x_0$,我们可以通过计算函数在$x_0$附近的两个点$x_0 - h$和$x_0 + h$的函数值来估计$f(x)$在$x_0$处的导数。其中$h$是一个很小的数,通常称为差分步长。
虽然有限差分方法简单易懂,但是它存在一些缺点。首先,它需要进行多次函数计算,因此比较耗时。其次,由于计算误差和舍入误差的积累,有限差分的精度很容易受到影响。因此,对于需要高精度计算的场景,有限差分通常不是最优的选择。
Question 21: 什么是vector-Jacobian product?
From https://www.cs.toronto.edu/~rgrosse/courses/csc321_2018/slides/lec10.pdf
Jacobi是偏导数矩阵。 \(J = \dfrac{\part y}{\part x} = \left( \begin{matrix} &\dfrac{\part y_1}{\part x_1} &\cdots &\dfrac{\part y_1}{\part x_n}\\ &\vdots &\ddots &\vdots\\ &\dfrac{\part y_m}{\part x_1} &\cdots &\dfrac{\part y_m}{\part x_n} \end{matrix} \right)\) 反向传播等式可以写为Vector-Jacobian Product(VJP): \(\overline{x_j} = \sum_{i}\overline{y_i}\dfrac{\part y_i}{\part x_j}\)
\[\overline{x}^T = \overline{y}^T J\text{(行向量形式)}\\ \overline{x} = J^T\overline{y}\text{(列向量形式)}\]https://stats.stackexchange.com/questions/505742/vector-jacobian-product-in-automatic-differentiation
这里有个问题很有趣,讨论的是Jacobi矩阵在计算的时候不用确实全部都计算出来,只需要计算有必要的部分即可。这件事情不太好理解。留作以后思考。
Question 30: Markdown中矩阵、三个点如何表示?
From (28条消息) LaTeX输入单个点、横向多个点、竖向多个点、斜向多个点_latex 点_GarfieldEr007的博客-CSDN博客
J = \dfrac{\part y}{\part x} = \left( \begin{matrix}
&\dfrac{\part y_1}{\part x_1} &\cdots &\dfrac{\part y_1}{\part x_n}\\
&\vdots &\ddots &\vdots\\
&\dfrac{\part y_m}{\part x_1} &\cdots &\dfrac{\part y_m}{\part x_n}
\end{matrix}
\right)
显示为: \(J = \dfrac{\part y}{\part x} = \left( \begin{matrix} &\dfrac{\part y_1}{\part x_1} &\cdots &\dfrac{\part y_1}{\part x_n}\\ &\vdots &\ddots &\vdots\\ &\dfrac{\part y_m}{\part x_1} &\cdots &\dfrac{\part y_m}{\part x_n} \end{matrix} \right)\)
矩阵:\begin{matrix}, \end{matrix} 横着三个点:\cdots, \dots, $\cdots$ 竖着三个点:\vdots,$\vdots$ 斜着三个点:\ddots, $\ddots$
Question 31: Markdown中,在字符、公式上面加横线怎么表示?
From (28条消息) 【Latex 格式】Markdown或者LaTeX在单个字母上加一横、一点、两点、三角_markdown字母上面加一横_Better Bench的博客-CSDN博客
\overline{x}: $\overline{x}$
2023年4月9日
Question 91: 方位角的表示方法
From http://astronomy.nmsu.edu/nicole/teaching/ASTR505/lectures/lecture08/slide01.html
2023年4月10日
Question 110: 圆柱、圆锥的横截面为什么是椭圆?
From: https://www.guokr.com/article/441484/
Question 111: 偏航角、俯仰角、滚动角分别是什么?
From: https://simple.wikipedia.org/wiki/Pitch,_yaw,_and_roll
https://howthingsfly.si.edu/flight-dynamics/roll-pitch-and-yaw
(5条消息) 三维空间中视角位置和物体取向的确定_三维页面 视角 定位 设计_ConardLi的博客-CSDN博客
(5条消息) pitch、yaw、roll三个角的区别(yaw angle 偏航角,steering angle 航向角的解释)_yaw角_菜且凶残_2017的博客-CSDN博客
https://en.wikipedia.org/wiki/Euler_angles
https://zh.wikipedia.org/wiki/%E6%AC%A7%E6%8B%89%E8%A7%92
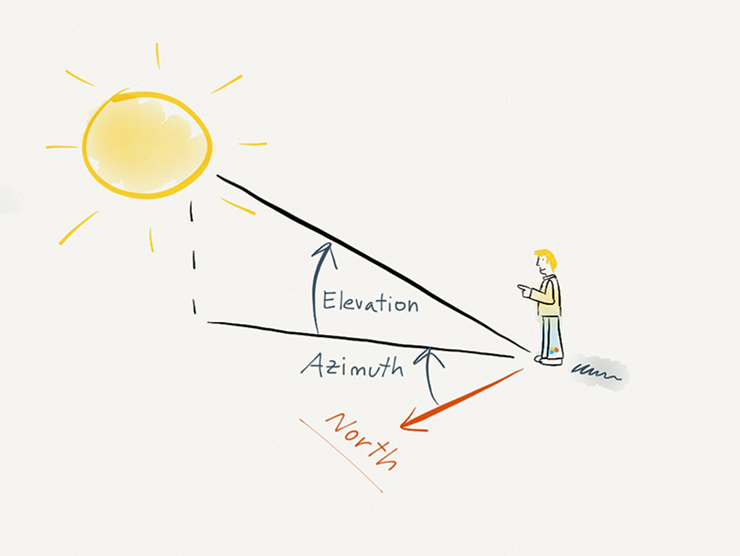
Question 115: 倾斜角、方位角的图应该怎么画?
From: https://www.photopills.com/articles/understanding-azimuth-and-elevation

From: https://en.wikipedia.org/wiki/Azimuth
Question 120: Spherical Triangle的性质?
From http://astronomy.nmsu.edu/nicole/teaching/ASTR505/lectures/lecture08/slide01.html
2023年4月11日
def imread(filename: str, flags: int = …) -> Mat:
‘imread(filename[, flags]) -> retval
. @brief Loads an image from a file.
.
. @anchor imread
.
. The function imread loads an image from the specified file and returns it. If the image cannot be
. read (because of missing file, improper permissions, unsupported or invalid format), the function
. returns an empty matrix ( Mat::data==NULL ).
.
. Currently, the following file formats are supported:
.
. - Windows bitmaps - \.bmp, \.dib (always supported)
. - JPEG files - \.jpeg, \.jpg, \.jpe (see the *Note section)
. - JPEG 2000 files - \.jp2 (see the *Note section)
. - Portable Network Graphics - \.png (see the *Note section)
. - WebP - \.webp (see the *Note section)
. - Portable image format - \.pbm, \.pgm, \.ppm \.pxm, \.pnm (always supported)
. - PFM files - \.pfm (see the Note section)
. - Sun rasters - \.sr, \.ras (always supported)
. - TIFF files - \.tiff, \.tif (see the Note section)
. - OpenEXR Image files - \.exr (see the *Note section)
. - Radiance HDR - \.hdr, \.pic (always supported)
. - Raster and Vector geospatial data supported by GDAL (see the Note section)
.
. @note
. - The function determines the type of an image by the content, not by the file extension.
. - In the case of color images, the decoded images will have the channels stored in B G R order.
. - When using IMREAD_GRAYSCALE, the codec's internal grayscale conversion will be used, if available.
. Results may differ to the output of cvtColor()
. - On Microsoft Windows\* OS and MacOSX\, the codecs shipped with an OpenCV image (libjpeg,
. libpng, libtiff, and libjasper) are used by default. So, OpenCV can always read JPEGs, PNGs,
. and TIFFs. On MacOSX, there is also an option to use native MacOSX image readers. But beware
. that currently these native image loaders give images with different pixel values because of
. the color management embedded into MacOSX.
. - On Linux\, BSD flavors and other Unix-like open-source operating systems, OpenCV looks for
. codecs supplied with an OS image. Install the relevant packages (do not forget the development
. files, for example, “libjpeg-dev”, in Debian\* and Ubuntu\) to get the codec support or turn
. on the OPENCV_BUILD_3RDPARTY_LIBS flag in CMake.
. - In the case you set *WITH_GDAL flag to true in CMake and @ref IMREAD_LOAD_GDAL to load the image,
. then the GDAL driver will be used in order to decode the image, supporting
. the following formats: Raster,
. Vector.
. - If EXIF information is embedded in the image file, the EXIF orientation will be taken into account
. and thus the image will be rotated accordingly except if the flags @ref IMREAD_IGNORE_ORIENTATION
. or @ref IMREAD_UNCHANGED are passed.
. - Use the IMREAD_UNCHANGED flag to keep the floating point values from PFM image.
. - By default number of pixels must be less than 2^30. Limit can be set using system
. variable OPENCV_IO_MAX_IMAGE_PIXELS
.
. @param filename Name of file to be loaded.
. @param flags Flag that can take values of cv::ImreadModes’
…
2023年4月16日
Quesion 222: 看到一篇不错的讲解相机内参的博客,读Dissecting the Camera Matrixx, part 3: the intrinsic matrix.
From: 讲解文章 https://ksimek.github.io/2013/08/13/intrinsic/
互动页面,可以看到透视相机中的各个参数是如何影响最终成像结果的。https://ksimek.github.io/perspective_camera_toy.html
2023年4月26日
341、
From GPT.
好的,我会尽力详细解释这些概念,并给出一些公式和矩阵。
首先,我们考虑两个相机的投影关系。假设我们有两个相机$P$和$P’$,它们的相机中心分别是$\mathbf{C}$和$\mathbf{C’}$,内参矩阵分别为$K$和$K’$。那么,对于从空间中的点$\mathbf{P}$到相机平面上的投影点$\mathbf{p}$,我们可以写成以下形式:
\[\mathbf{p}= K\begin{bmatrix}\mathbf{R} & \mathbf{t} \end{bmatrix} \mathbf{P}\]其中,$\mathbf{R}$和$\mathbf{t}$是描述相机的旋转和平移关系的矩阵,$K$是一个 $3\times3$ 的内参矩阵。类似地,对于另一个相机$P’$,我们可以得到:
\[\mathbf{p'}= K'\begin{bmatrix}\mathbf{R'} & \mathbf{t'} \end{bmatrix} \mathbf{P}\]接下来,我们考虑如何从这些投影点中计算出两个相机之间的运动关系。我们可以使用本质矩阵$E$来描述两个相机之间的几何约束,它定义了两个投影矩阵之间的关系:
\[\mathbf{p'}^\top E \mathbf{p} = 0\]其中,$E=\lbrack\mathbf{t}\rbrack_\times \mathbf{R}$,$\lbrack\mathbf{t}\rbrack_\times$表示$\mathbf{t}$的反对称矩阵,$\mathbf{R}$是旋转矩阵。本质矩阵$E$的秩为2,因此我们可以使用奇异值分解(SVD)或者特征值分解(EVD)对其进行分解,并从中恢复相机的运动关系。
在实际应用中,$E$通常通过相机图像中的SIFT特征匹配和鲁棒性本质矩阵估计(RANSAC)来计算。通过SIFT特征匹配,我们可以得到许多匹配点对$(\mathbf{p}_i,\mathbf{p’}_i)$,它们满足本质矩阵的约束条件。然后,我们使用RANSAC算法从这些点对中选择一组内点,将它们作为输入数据并使用最小二乘法或者其他优化方法来计算$E$矩阵。
最后,我们可以将$E$分解成旋转矩阵$\mathbf{R}$和平移向量$\mathbf{t}$,这样就可以得到两个相机之间的运动关系了:
\[E=\lbrack\mathbf{t}\rbrack_\times \mathbf{R}\]这个过程也被称为本质矩阵分解。在实际应用中,我们通常会假设我们已知相机内参矩阵$K$和$K’$,以简化计算。
总之,本质矩阵$E$是描述两个相机之间运动关系的基本矩阵,它由两个相机的旋转矩阵和平移向量组成。通过SIFT特征匹配和鲁棒性本质矩阵估计,我们可以从图像中计算出$E$,并进一步分解成旋转矩阵和平移向量,得到两个相机之间的运动关系。
409、
/*M///////////////////////////////////////////////////////////////////////////////////////
//
// IMPORTANT: READ BEFORE DOWNLOADING, COPYING, INSTALLING OR USING.
//
// By downloading, copying, installing or using the software you agree to this license.
// If you do not agree to this license, do not download, install,
// copy or use the software.
//
//
// License Agreement
// For Open Source Computer Vision Library
//
// Copyright (C) 2000-2008, Intel Corporation, all rights reserved.
// Copyright (C) 2009, Willow Garage Inc., all rights reserved.
// Third party copyrights are property of their respective owners.
//
// Redistribution and use in source and binary forms, with or without modification,
// are permitted provided that the following conditions are met:
//
// * Redistribution's of source code must retain the above copyright notice,
// this list of conditions and the following disclaimer.
//
// * Redistribution's in binary form must reproduce the above copyright notice,
// this list of conditions and the following disclaimer in the documentation
// and/or other materials provided with the distribution.
//
// * The name of the copyright holders may not be used to endorse or promote products
// derived from this software without specific prior written permission.
//
// This software is provided by the copyright holders and contributors "as is" and
// any express or implied warranties, including, but not limited to, the implied
// warranties of merchantability and fitness for a particular purpose are disclaimed.
// In no event shall the Intel Corporation or contributors be liable for any direct,
// indirect, incidental, special, exemplary, or consequential damages
// (including, but not limited to, procurement of substitute goods or services;
// loss of use, data, or profits; or business interruption) however caused
// and on any theory of liability, whether in contract, strict liability,
// or tort (including negligence or otherwise) arising in any way out of
// the use of this software, even if advised of the possibility of such damage.
//
//M*/
#include "test_precomp.hpp"
namespace opencv_test { namespace {
class CV_DecomposeProjectionMatrixTest : public cvtest::BaseTest
{
public:
CV_DecomposeProjectionMatrixTest();
protected:
void run(int);
};
CV_DecomposeProjectionMatrixTest::CV_DecomposeProjectionMatrixTest()
{
test_case_count = 30;
}
void CV_DecomposeProjectionMatrixTest::run(int start_from)
{
ts->set_failed_test_info(cvtest::TS::OK);
cv::RNG& rng = ts->get_rng();
int progress = 0;
for (int iter = start_from; iter < test_case_count; ++iter)
{
ts->update_context(this, iter, true);
progress = update_progress(progress, iter, test_case_count, 0);
// Create the original (and random) camera matrix, rotation, and translation
cv::Vec2d f, c;
rng.fill(f, cv::RNG::UNIFORM, 300, 1000);
rng.fill(c, cv::RNG::UNIFORM, 150, 600);
double alpha = 0.01*rng.gaussian(1);
cv::Matx33d origK(f(0), alpha*f(0), c(0),
0, f(1), c(1),
0, 0, 1);
cv::Vec3d rVec;
rng.fill(rVec, cv::RNG::UNIFORM, -CV_PI, CV_PI);
cv::Matx33d origR;
cv::Rodrigues(rVec, origR); // TODO cvtest
cv::Vec3d origT;
rng.fill(origT, cv::RNG::NORMAL, 0, 1);
// Compose the projection matrix
cv::Matx34d P(3,4);
hconcat(origK*origR, origK*origT, P);
// Decompose
cv::Matx33d K, R;
cv::Vec4d homogCameraCenter;
decomposeProjectionMatrix(P, K, R, homogCameraCenter);
// Recover translation from the camera center
cv::Vec3d cameraCenter(homogCameraCenter(0), homogCameraCenter(1), homogCameraCenter(2));
cameraCenter /= homogCameraCenter(3);
cv::Vec3d t = -R*cameraCenter;
const double thresh = 1e-6;
if (cv::norm(origK, K, cv::NORM_INF) > thresh)
{
ts->set_failed_test_info(cvtest::TS::FAIL_BAD_ACCURACY);
break;
}
if (cv::norm(origR, R, cv::NORM_INF) > thresh)
{
ts->set_failed_test_info(cvtest::TS::FAIL_BAD_ACCURACY);
break;
}
if (cv::norm(origT, t, cv::NORM_INF) > thresh)
{
ts->set_failed_test_info(cvtest::TS::FAIL_BAD_ACCURACY);
break;
}
}
}
TEST(Calib3d_DecomposeProjectionMatrix, accuracy)
{
CV_DecomposeProjectionMatrixTest test;
test.safe_run();
}
}} // namespace
521
/data1/zwn21/anaconda3/envs/NeuS/lib/python3.8/site-packages/torch/cuda/__init__.py:104: UserWarning:
NVIDIA A100-SXM4-80GB with CUDA capability sm_80 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70.
If you want to use the NVIDIA A100-SXM4-80GB GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
warnings.warn(incompatible_device_warn.format(device_name, capability, " ".join(arch_list), device_name))
Load data: Begin
Traceback (most recent call last):
File "exp_runner.py", line 398, in <module>
runner = Runner(args.conf, args.mode, args.case, args.is_continue)
File "exp_runner.py", line 36, in __init__
self.dataset = Dataset(self.conf['dataset'])
File "/data1/zwn21/github/transneus/v230508/transneus/models/dataset.py", line 90, in __init__
self.intrinsics_all_inv = torch.inverse(self.intrinsics_all) # [n_images, 4, 4]
RuntimeError: CUDA error: no kernel image is available for execution on the device
525
写一段代码,为学习遇到的问题设置索引
import math
max_num = 600
hundred = int(math.ceil(max_num / 100))
for i in range(hundred):
print('|' * 11)
print('|:---:'*10+'|')
for j in range(10):
for k in range(1, 11):
num = i * 100 + j * 10 + k
print('|', '[{}](##{})'.format(num, num), end='')
print('|')
# print('|'*11)
print('')
import datetime
start = datetime.date(year=2023, month=4, day=4)
end = datetime.date(year=2023, month=10, day=31)
def judge(a, b):
if a > b:
return True
else:
return False
day = start
print('|星期一|星期二|星期三|星期四|星期五|星期六|星期日|')
print('|:---:'*7+'|')
print('|', end='')
for i in range(1, 8):
if i != day.isoweekday():
print('|', end='')
else:
break
while not judge(day, end):
day_str = '{}年{}月{}日'.format(day.year, day.month, day.day)
print('[{}](#{})|'.format(day_str, day_str), end='')
# print('[{}]|'.format(day_str), end='')
if day.isoweekday() == 7:
print('')
print('|', end='')
if day.month != (day + datetime.timedelta(days=1)).month:
if day.isoweekday() == 7:
print('|'*7)
print('|', end='')
else:
for j in range(day.isoweekday()+1, 8):
print('|', end='')
print('')
print('|'*8)
print('|', end='')
for j in range(1, day.isoweekday()+1):
print('|', end='')
day = day + datetime.timedelta(days=1)
for i in range(day.isoweekday(), 8):
print('|', end='')
print('')
评论