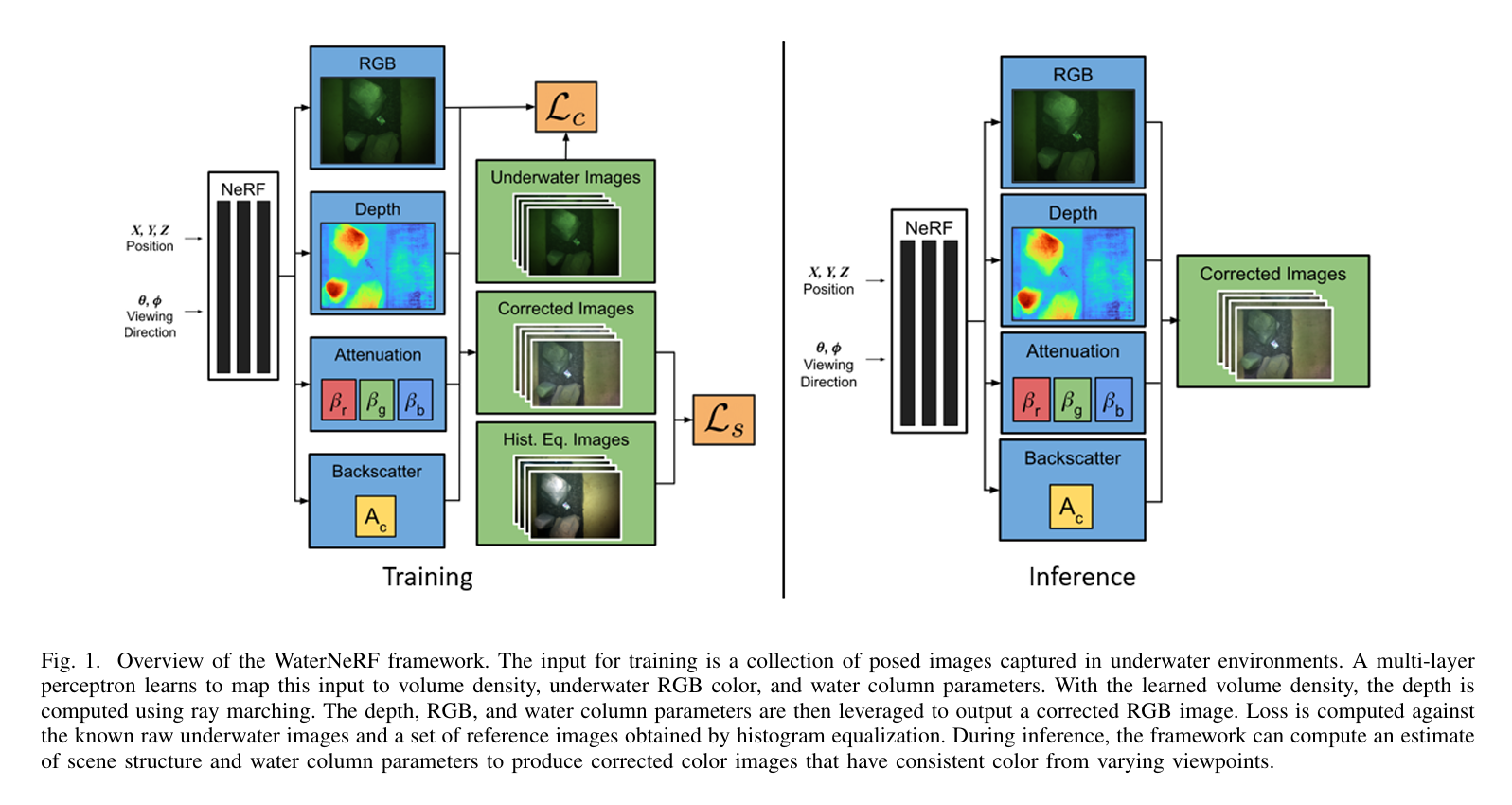
图1. WaterNeRF框架概述。训练的输入是在水下环境中拍摄的一组带姿态的图像。多层感知器学习将此输入映射到体密度、水下RGB颜色和水体参数。利用学习到的体密度,通过光线行进法计算深度。然后利用深度、RGB和水体参数输出校正后的RGB图像。根据已知的原始水下图像和通过直方图均衡化得到的一组参考图像计算损失。在推理过程中,该框架可以计算场景结构和水体参数的估计值,以生成从不同视角看颜色一致的校正彩色图像。
论文链接
论文重点难点讲解
论文重点
1. 研究背景与动机
-
水下成像的重要性:水下成像对于海洋机器人在水产养殖、海洋基础设施检查和环境监测等任务中至关重要。
-
水下成像的挑战:水柱效应(如吸收和散射)会严重改变水下图像的颜色和质量,导致图像退化,影响深度估计和3D重建等下游任务。
2. WaterNeRF方法
-
核心思想:利用神经辐射场(NeRF)技术,结合水下成像的物理模型,实现水下场景的新型视图合成、图像恢复和密集深度估计。
-
框架概述:WaterNeRF框架输入水下图像及其姿态信息,通过多层感知机(MLP)学习场景的体积密度、水下RGB颜色和水柱参数(包括衰减和散射参数),并利用这些参数恢复场景的空气外观。
-
主要贡献:
-
提出了一种基于隐式场景表示的水下颜色校正问题。
-
展示了新型视图合成和3D重建能力。
-
在控制实验室环境中对方法进行了评估。
3. 技术方法
-
NeRF与mip-NeRF:基于mip-NeRF实现,避免了传统NeRF中的锯齿问题,同时优化了图像质量和深度图质量。
-
颜色校正分支:利用水下光传输模型,通过估计衰减系数和幕光来校正水下图像的颜色。
-
最优传输问题:将颜色校正损失重新定义为最优传输问题,使用Sinkhorn算法求解,优化衰减参数以匹配直方图均衡化图像的分布。
4. 实验与结果
-
数据集:使用开源的UWBundle数据集,包含36张水下人工岩石平台的图像。
-
对比方法:与基于图像处理、基于物理模型和基于深度学习的方法进行对比。
-
定量评估:
-
颜色校正:使用平均角度误差($\bar{\psi}$)评估颜色校正精度,WaterNeRF在多个颜色通道上表现接近直方图均衡化。
-
图像质量:使用水下图像质量指标(UIQM)评估,WaterNeRF在图像质量上优于Haze Lines模型和FUnIE-GAN。
-
场景一致性:通过场景一致性度量(SCM)评估校正方法在不同视图间的一致性,WaterNeRF在红通道上表现最佳。
-
深度估计:WaterNeRF生成的点云与真实3D网格之间的均方根误差(RMSE)低于HENeRF,显示出更好的深度重建能力。
论文难点
1. 水下成像物理模型的复杂性
- 水下图像退化是由多种因素(如水体特性、场景结构和光照条件)共同作用的结果,这些因素的建模和参数估计是难点之一。
2. 最优传输问题的求解
- 将颜色校正损失定义为最优传输问题,虽然使用了Sinkhorn算法进行近似求解,但该问题的计算复杂度较高,且需要在物理约束下优化衰减参数。
3. 数据集的局限性
- 实验中使用的UWBundle数据集是控制实验室环境下的数据,可能无法完全反映实际水下场景的复杂性。此外,缺乏真实颜色和结构的地面真值数据,使得评估方法的泛化能力存在一定局限。
4. 深度估计与颜色校正的联合优化
- WaterNeRF需要同时优化场景的深度结构和颜色校正参数,这增加了模型训练的复杂性和难度。如何在训练过程中平衡这两部分的优化是一个关键问题。
论文详细讲解:WaterNeRF: Neural Radiance Fields for Underwater Scenes
1. 研究背景与动机
水下成像在海洋机器人任务中具有重要意义,例如水产养殖、海洋基础设施检查和环境监测等。然而,由于水柱效应(如吸收和散射),水下图像的颜色和质量会受到严重影响。这些效应导致图像颜色失真和类似雾的散射效果,对依赖准确颜色和密集结构信息的机器人系统来说是一个挑战。此外,水柱效应的复杂性还体现在其依赖于场景结构、水体特性、光照条件等多种因素,且缺乏水下场景的真实颜色和结构数据,使得水下图像恢复和密集场景重建成为一个病态问题。
2. WaterNeRF方法概述
本文提出了一种基于神经辐射场(NeRF)的方法——WaterNeRF,用于水下场景的新型视图合成、图像恢复和密集深度估计。WaterNeRF的核心思想是结合水下成像的物理模型,通过学习场景的体积密度、水下RGB颜色和水柱参数(包括衰减和散射参数),恢复场景的空气外观。
3. 技术方法
3.1 NeRF与mip-NeRF
WaterNeRF基于mip-NeRF实现,mip-NeRF通过将射线替换为圆锥截锥来避免锯齿问题,同时优化了图像质量和深度图质量。mip-NeRF使用多层感知机(MLP)将查询位置和方向映射到颜色和密度:
\[\forall t_k \in t, [\sigma_k, c_k] = \text{MLP}(\gamma(r(t_k)), \theta, \phi; \Theta)\]其中,$\gamma(r(t))$是位置编码,$\sigma_k$是体积密度,$c_k$是颜色。通过数值积分估计射线的颜色:
\[C(r; \Theta, t) = \sum_k T_k (1 - e^{-\sigma_k (t_{k+1} - t_k)}) c_k\]深度可以通过类似的方式计算:
\[D(r; \Theta, t) = \sum_k T_k (1 - e^{-\sigma_k (t_{k+1} - t_k)}) t_{km}\]其中 $t_{km} = \frac{1}{2}(t_{k+1} + t_k)$。
3.2 颜色校正分支
WaterNeRF利用水下光传输模型进行颜色校正。根据模型:
\[I_c(x) = t_c(x) J_c(x) + (1 - t_c(x)) A_c\]其中,$I_c(x)$是水下图像,$t_c(x) = e^{-\beta_c D(x)}$是传输图,$J_c(x)$是物体的原始辐射,$A_c$是幕光,$\beta_c$是波长相关的衰减系数。颜色校正的输出为:
\[J(r; \Theta, t) = \frac{C(r; \Theta, t) - (1 - t_c(x)) A_c}{t_c(x)}\]由于缺乏真实校正图像,WaterNeRF通过最优传输问题优化衰减系数和幕光,以匹配直方图均衡化图像的分布。
3.3 最优传输问题
最优传输问题的目标是最小化两个分布之间的Wasserstein距离。WaterNeRF使用Sinkhorn算法近似求解最优传输问题,优化衰减系数和幕光:
\[\beta^*_c, A^*_c = \arg \min_{\beta_c, A_c} \tilde{S}_\lambda(\mu, \nu)\]其中,$\mu$是WaterNeRF输出的校正颜色分布,$\nu$是直方图均衡化图像的颜色分布。最终的目标函数为:
\[L = L_c + \alpha L_s\]其中,$L_c$是颜色损失,$L_s$是Sinkhorn损失,$\alpha$是权重。
4. 实验与结果
4.1 数据集
实验使用开源的UWBundle数据集,包含36张水下人工岩石平台的图像,场景中包含色卡,便于定量评估颜色校正效果。
4.2 对比方法
WaterNeRF与以下方法进行对比:
-
FUnIE-GAN:基于条件GAN的图像恢复方法。
-
Underwater Haze Lines Model:基于雾线先验的物理模型。
-
Histogram Equalization:直方图均衡化方法。
-
HENeRF:直接在直方图均衡化图像上训练的mip-NeRF。
-
WaterNeRF-No Sinkhorn:不使用Sinkhorn损失的WaterNeRF变体。
4.3 定量评估
-
颜色校正:使用平均角度误差($\bar{\psi}$)评估颜色校正精度。WaterNeRF在多个颜色通道上的表现接近直方图均衡化,优于其他方法。
-
图像质量:使用水下图像质量指标(UIQM)评估,WaterNeRF在图像质量上优于Haze Lines模型和FUnIE-GAN,但略低于直方图均衡化。
-
场景一致性:通过场景一致性度量(SCM)评估校正方法在不同视图间的一致性,WaterNeRF在红通道上表现最佳。
-
深度估计:WaterNeRF生成的点云与真实3D网格之间的均方根误差(RMSE)低于HENeRF,显示出更好的深度重建能力。
4.4 定性评估
WaterNeRF能够生成一致的颜色校正图像,并且在不同视图之间保持良好的一致性。与直方图均衡化和HENeRF相比,WaterNeRF生成的深度图更加完整且无明显断层。
5. 结论与未来工作
WaterNeRF是首个利用神经体积渲染技术实现水下场景新型视图合成、全场景恢复和密集深度估计的方法。实验结果表明,WaterNeRF在场景一致性和3D重建能力上表现出色,证明了学习衰减参数对于新型视图合成的重要性。未来的工作将探索如何利用WaterNeRF的3D对象信息和颜色信息,为海洋机器人的水下操作和探索任务提供支持。
论文方法部分详细讲解
1. WaterNeRF框架概述
WaterNeRF框架的核心是利用神经辐射场(NeRF)技术,结合水下成像的物理模型,实现水下场景的新型视图合成、图像恢复和密集深度估计。该框架输入一组已知姿态的水下图像,通过多层感知机(MLP)学习场景的体积密度、水下RGB颜色和水柱参数(包括衰减和散射参数),并利用这些参数恢复场景的空气外观。
2. 基于mip-NeRF的体积渲染
WaterNeRF基于mip-NeRF实现,mip-NeRF通过将射线替换为圆锥截锥来避免锯齿问题,同时优化了图像质量和深度图质量。
- 输入与输出:
MLP的输入包括场景点的3D位置 $(x, y, z)$ 和观察方向 $(\theta, \phi)$,输出为体积密度 $\sigma$ 和水下RGB颜色 $c$。
- 体积渲染公式:
对于每条射线 $r(t) = o + td$,其中 $t \in [t_n, t_f]$,$o$ 是射线起点,$d$ 是射线方向。通过MLP计算每个采样点的颜色和密度:
\[\forall t_k \in t, [\sigma_k, c_k] = \text{MLP}(\gamma(r(t_k)), \theta, \phi; \Theta)\]其中,$\gamma(r(t))$ 是位置编码,用于增强模型对空间信息的表达能力。
- 颜色积分:
射线的颜色通过数值积分计算:
\[C(r; \Theta, t) = \sum_k T_k (1 - e^{-\sigma_k (t_{k+1} - t_k)}) c_k\]其中,$T_k = \exp\left(-\sum_{k’<k} \sigma_{k’} (t_{k’+1} - t_{k’})\right)$ 是累积透明度。
- 深度计算:
深度通过类似的方式计算:
\[D(r; \Theta, t) = \sum_k T_k (1 - e^{-\sigma_k (t_{k+1} - t_k)}) t_{km}\]其中,$t_{km} = \frac{1}{2}(t_{k+1} + t_k)$ 是采样点的中点位置。
3. 颜色校正分支
WaterNeRF通过物理模型对水下图像进行颜色校正,以恢复场景的空气外观。
- 水下成像模型:
水下图像的形成模型为:
\[I_c(x) = t_c(x) J_c(x) + (1 - t_c(x)) A_c\]其中,$I_c(x)$ 是水下图像,$t_c(x) = e^{-\beta_c D(x)}$ 是传输图,$J_c(x)$ 是物体的原始辐射,$A_c$ 是幕光,$\beta_c$ 是波长相关的衰减系数。
- 颜色校正公式:
校正后的颜色输出为:
\[J(r; \Theta, t) = \frac{C(r; \Theta, t) - (1 - t_c(x)) A_c}{t_c(x)}\]4. 最优传输问题
由于缺乏真实校正图像,WaterNeRF通过最优传输问题优化衰减系数和幕光,以匹配直方图均衡化图像的分布。
- 最优传输目标:
最小化两个分布之间的Wasserstein距离:
\[\beta^*_c, A^*_c = \arg \min_{\beta_c, A_c} \tilde{S}_\lambda(\mu, \nu)\]其中,$\mu$ 是WaterNeRF输出的校正颜色分布,$\nu$ 是直方图均衡化图像的颜色分布。
- Sinkhorn算法:
使用Sinkhorn算法近似求解最优传输问题,优化目标为:
\[\tilde{S}_\lambda = \min_{T \in \Pi(a,b)} \langle T, M \rangle - \frac{1}{\lambda} h(T)\]其中,$M$ 是成本矩阵,$h(T)$ 是熵正则化项。
- 最终目标函数:
结合颜色损失和Sinkhorn损失:
\[L = L_c + \alpha L_s\]其中,$L_c$ 是颜色损失,$L_s$ 是Sinkhorn损失,$\alpha$ 是权重。
5. 训练与优化
- 训练细节:
使用JAX框架进行训练,初始学习率为 $5 \times 10^{-4}$,最终学习率为 $5 \times 10^{-6}$,采用Adam优化器,训练600,000次迭代,耗时约8小时(Nvidia GeForce RTX 3090 GPU)。
- 损失函数:
颜色损失 $L_c$ 由粗略和精细查询的均方误差组成:
\[L_c = \lambda \|C^*(r) - C(r; \Theta, t_c)\|_2^2 + \|C^*(r) - C(r; \Theta, t_f)\|_2^2\]其中,$C^*(r)$ 是原始水下图像的像素值。
通过上述方法,WaterNeRF能够学习水下场景的结构和辐射场,并利用这些信息恢复校正后的图像,同时生成高质量的深度图。
原文翻译
WaterNeRF:用于水下场景的神经辐射场
阿德维特·维卡特拉马南·塞图拉曼 马尼坎达西里拉姆·斯里尼瓦桑·拉马纳戈帕尔 凯瑟琳·A·斯金纳
密歇根大学机器人系
美国密歇根州安阿伯
advaiths@umich.edu
srimani@umich.edu
kskin@umich.edu
摘要
水下成像 是海洋机器人执行的一项关键任务,广泛应用于水产养殖、海洋基础设施检测和环境监测等领域。然而,水体效应,如光的衰减和后向散射,会极大地改变水下拍摄图像的颜色和质量。由于水体条件的变化以及这些效应与距离的相关性 ,恢复水下图像是一个具有挑战性的问题。这会影响包括深度估计和三维重建在内的下游感知任务。在本文中,我们利用最先进的神经辐射场(NeRFs),为水下场景实现基于物理原理的新视图合成,同时进行图像恢复和密集深度估计。我们提出的方法WaterNeRF,估计基于物理的水下成像模型的参数,并使用这些参数进行新视图合成。在学习场景结构和辐射场后,我们可以生成退化的以及校正后的水下图像的新视图。我们在真实的水下数据集上对所提出的方法进行了定性和定量评估。
关键词:水下成像;场景重建;神经辐射场;水下图像恢复
I. 引言
图1. WaterNeRF框架概述。训练的输入是在水下环境中拍摄的一组带姿态的图像。多层感知器学习将此输入映射到体密度、水下RGB颜色和水体参数。利用学习到的体密度,通过光线行进法计算深度。然后利用深度、RGB和水体参数输出校正后的RGB图像。根据已知的原始水下图像和通过直方图均衡化得到的一组参考图像计算损失。在推理过程中,该框架可以计算场景结构和水体参数的估计值,以生成从不同视角看颜色一致的校正彩色图像。
改善水下感知将提升水下载具的自主能力,使其任务复杂性得以增加。这将对海洋科学和工业产生影响[1],[2]。然而,与空气中不同,水下图像常因水柱对水下光传播的影响而严重退化。在水下环境中,吸收导致波长依赖性衰减,使图像产生颜色失真。后向散射在整个场景中造成雾状效果,类似于空气中的雾[3]。这对依赖准确一致的颜色和密集结构信息来实现高级感知任务的海洋机器人系统构成挑战。理想情况下,水下图像可以被恢复为如同在空气中拍摄的效果。然而,水柱效应取决于许多因素,包括场景结构、水特性和光特性。此外,水下场景的颜色和结构通常缺乏真实参考。这些因素使水下图像恢复和密集场景重建成为一个欠定问题。
在陆地上,神经场景表示取得了令人印象深刻的进展,可以学习体积场景函数以实现新视角的渲染。Mildenhall等人开发了神经辐射场(NeRF),可以通过一组稀疏输入图像进行训练,学习将位置和观察方向映射到视角依赖的辐射和体积密度的函数[4]。这些神经场景表示的进展展示了通过学习图像形成物理过程,基于一组输入图像学习场景属性的能力。我们提议将这些进展扩展到水下环境,考虑水下光传播的影响,同时学习场景的密集结构模型。
我们提出的方法WaterNeRF,是一种利用神经辐射场表示水下环境的方法。如图1所示,WaterNeRF框架以相应的单目水下和颜色校正图像集为输入,构建表示为NeRF的体积,然后推断恢复场景至空气中外观所需的特定波长衰减参数。值得注意的是,WaterNeRF利用NeRF编码场景的优势,并使用所得深度信息指导基于物理的、数据驱动的恢复方法。
我们的主要贡献如下:
-
制定利用通过神经辐射场学习的隐式场景表示的水下颜色校正问题。
-
展示我们提出方法的新视角合成和3D重建能力。
-
在控制实验室环境中收集的具有真实颜色参考的数据集上,评估我们的方法与先前工作的对比。
本文的其余部分组织如下:我们介绍相关工作概述、WaterNeRF的技术方法,最后是我们的实验和结果。
II. 相关工作
A. 水下图像的图像处理
直方图均衡化[5]和灰世界假设[6]等图像处理方法可用于水下图像增强。这些方法旨在拉伸水下图像的有效对比度,但不了解水下图像形成的基础物理过程。因此,它们无法校正各种与距离相关的效果。这可能导致从不同视角拍摄的同一场景图像的恢复结果不一致。
B. 水下图像形成的物理模型
从水下物体传输的光衰减取决于水况、场景结构和材料特性。许多基于物理的图像恢复方法首先使用暗通道先验[7]或雾线先验[3]等先验来估计图像中的后向散射。例如,Berman等人[8]首先从单一图像估计后向散射,然后生成透射图[9]。虽然该方法产生了令人满意的结果,但它需要立体相机设置和对特定水类型的了解。Akkaynak等人开发了水下图像形成和恢复的更新模型[10]-[12]。然而,该方法需要已知的场景密集深度图。
C. 用于水下图像恢复的深度学习
最近的工作集中于利用深度学习来学习水下图像形成模型,以展示水下图像渲染[13]-[15]。UGAN使用生成的数据训练GAN模型,以去除低质量水下图像中存在的退化[14]。WaterGAN是另一种对抗网络,考虑了逆问题:从空气中图像生成合成水下图像[15]。我们的工作将基于学习型图像恢复的进展,但会构建我们的解决方案以利用NeRF框架,除了校正颜色外,还能学习场景的密集结构模型。
D. 神经辐射场
与本工作最相关的是,神经反射场已被开发用于实现场景重光照的新视角渲染[16],[17]。在NeRF背景下也考虑了光在不同介质中传输的效果。具体来说,NeRF已被用于从卫星图像估计反照率和环境光[18]。最近,NeRF被用于模拟光在空气和水界面处的折射[19]。同样,我们问题的NeRF公式很方便,因为它提供了一个框架,可以将衰减参数作为校正颜色和光线终止距离的函数进行优化。
III. 技术方法
图1. WaterNeRF框架概述。训练的输入是在水下环境中拍摄的一组带姿态的图像。多层感知器学习将此输入映射到体密度、水下RGB颜色和水体参数。利用学习到的体密度,通过光线行进法计算深度。然后利用深度、RGB和水体参数输出校正后的RGB图像。根据已知的原始水下图像和通过直方图均衡化得到的一组参考图像计算损失。在推理过程中,该框架可以计算场景结构和水体参数的估计值,以生成从不同视角看颜色一致的校正彩色图像。
图1展示了WaterNeRF框架提出的管道概述。在训练过程中,网络以场景点的三维位置和观察方向作为输入,学习输出体积密度、水下RGB颜色和水柱参数,包括衰减和后向散射参数。深度、水下RGB和水柱参数被输入到基于物理的水下图像恢复模型中,该模型输出校正后的RGB图像。训练图像需要已知的姿态,这可以通过COLMAP[20]等运动恢复结构(SfM)管道获得。在推理阶段,我们能够从新视角渲染有水柱效应和无水柱效应的图像。
A. WaterNeRF公式
神经辐射场(NeRFs)将查询位置$x,y,z$和观察方向$\theta,\phi$作为输入,并输出颜色$r,g,b$和密度$\sigma$ [4]。
我们特别利用了mip - NeRF,它用圆锥台代替光线以避免混叠问题[21]。选择mip - NeRF是因为图像质量和深度图质量对于水下图像恢复都至关重要。
mip - NeRF使用由权重$\Theta$参数化的多层感知器(MLP)。光线定义为$r(t)=o + td$,其中$t\in[t_n,t_f]$位于近平面$t_n$和远平面$t_f$之间,$o$是光线起点,$d$是光线方向。在将查询位置传递给MLP之前,使用集成位置编码$\gamma(r(t))$对其进行编码[21]。
\[\forall t_k \in t,[\sigma_k,c_k]=MLP(\gamma(r(t_k)),\theta,\phi;\Theta) \tag{1}\]每个$\sigma_k$,$c_k$用于数值积分求和,以估计光线的颜色$C(r;\Theta,t)$。
\[C(r;\Theta,t)=\sum_{k}T_k(1 - exp(-\sigma_k(t_{k + 1}-t_k)))c_k \tag{2}\]给定光线的深度可以类似地求得:
\[D(r;\Theta,t)=\sum_{k}T_k(1 - exp(-\sigma_k(t_{k + 1}-t_k)))t_{km} \tag{3}\]其中$t_{km}=\frac{1}{2}(t_{k + 1}+t_k)$,并且
\[T_k = exp\left(-\sum_{k'<k}\sigma_{k'}(t_{k'+1}-t_{k'})\right) \tag{4}\]最后,在预测颜色$C(r;\Theta,t)$和从观察图像(在我们的例子中是原始水下图像)中得到的真实像素值$C^*(r)$之间计算颜色损失$\mathcal{L}_c$。该损失由对单个MLP网络的粗略查询$C(r;\Theta,t^c)$和精细查询$C(r;\Theta,t^f)$组成。
\[\mathcal{L}_c=\lambda\|C^*(r)-C(r;\Theta,t^c)\|_2^2+\|C^*(r)-C(r;\Theta,t^f)\|_2^2 \tag{5}\]B. 颜色校正分支
为了确定场景经过颜色校正后的外观,我们使用了文献[9]中提出的水中光传输模型。$I_c(x)$是在像素位置$x$处针对通道$c\in{R,G,B}$获取的图像,$t_c(x)$是透射图,$J_c(x)$是物体在衰减前的原始辐射,$A_c$是散射光或后向散射光。透射图$t_c(x)$与特定波长的衰减系数$\beta_c$以及像素处的深度$D(x)$相关。
\[I_c(x)=t_c(x)J_c(x)+(1 - t_c(x))A_c \tag{6}\] \[t_c(x)=exp(-\beta_cD(x)) \tag{7}\]利用这种关系,我们可以像图1所示那样定义网络的颜色校正输出$J(r;\Theta,t)$。
\[J(r;\Theta,t)=\frac{C(r;\Theta,t)-(1 - t_c(x))A_c}{t_c(x)} \tag{8}\]由于我们没有经过颜色校正的真实图像$I^*(r)$,所以不能像公式(5)中那样直接最小化$J(r;\Theta,t)$之间的损失。相反,我们可以依靠经过直方图均衡化的水下图像$H(r)$的辅助数据集来进行初始化。然而,直方图均衡化的图像既不符合公式(6),也不能在整个场景中生成一致的校正图像。为了解决这些问题,我们将颜色校正损失重新构建为一个最优传输问题,并尝试匹配直方图均衡化图像中像素的分布。我们希望估计衰减系数$\beta_c$和散射光$A_c$,以校正水下图像。
C. 最优传输入门
离散最优传输问题涉及分布,如$\mu,\nu\in\mathcal{P}(X)$,其中$\mu = \sum_{i = 1}^{n}a_i\delta_{x_i}$且$\nu = \sum_{j = 1}^{m}b_j\delta_{y_j}$,$\delta$是中心位于点${x_i\vert \forall i\in[1,n]}$和${y_j\vert \forall j\in[1,m]}$的狄拉克δ函数[22]。与这个离散分布相关的权重满足$a = (a_1,\ldots,a_n)^{\top}\in\Delta_n$且$b = (b_1,\ldots,b_m)^{\top}\in\Delta_m$,其中
\[\Delta_n=\{p\in\mathbb{R}_{+}^{n}\mid p^{\top}\mathbf{1}_n = 1\} \tag{9}\]$\mathbf{1}_n$是一个长度为$n$的全1向量。目标是计算一个传输计划$T$,使得以下形式的瓦瑟斯坦距离最小化:
\[W_p^{p}(\mu,\nu)=\min_{T\in\Pi(a,b)}\langle T,M\rangle \tag{10}\]$M$是一个成本矩阵$\mathbb{R}^{n\times m}$,其中$M_{ij}=d(x_i,y_j)$,是点$x_i$和$y_j$之间的有效距离。$\langle T,M\rangle$是矩阵之间的弗罗贝尼乌斯积$Tr(T^{\top}M)$。传输计划$T\in\Pi(a,b)$必须在集合内:
\[\Pi(a,b)=\{T\in\mathbb{R}_{+}^{n\times m}:T\mathbf{1}_m = a,T^{\top}\mathbf{1}_n = b\} \tag{11}\]这个复杂的优化问题可以通过一种称为辛克霍恩算法$\tilde{S}_{\lambda}$的可微过程进行正则化和求解。辛克霍恩算法被认为是对瓦瑟斯坦距离的有效近似[23],[24]。
\[\tilde{S}_{\lambda}=\min_{T\in\Pi(a,b)}\langle T,M\rangle-\frac{1}{\lambda}h(T) \tag{12}\] \[h(T)=-\sum_{i,j = 1}^{n,m}T_{i,j}(\log T_{ij}-1) \tag{13}\]在这项工作中,辛克霍恩损失用于概率分布$\mu$(表示WaterNeRF输出的校正颜色$J(r;\Theta,t)$的分布)和$\nu$(表示直方图均衡化图像中的颜色分布)之间。$\mu$和$\nu$都是RGB空间$\mathbb{R}^3$中的分布。形式上,优化问题变为:
\[\beta_c^*,A_c^*=\underset{\beta_c,A_c}{\arg\min}\tilde{S}_{\lambda}(\mu,\nu) \tag{14}\]其中$\mu=\frac{\nu-(1 - t_c(x))A_c}{t_c(x)}$
该框架必须优化参数$\beta_c$,以最小化两种颜色分布之间的辛克霍恩损失。由于优化受到物理约束,最优点$\beta_c^\star$将提供将水下图像映射到直方图均衡化图像所需的衰减参数,同时遵循公式(6)中成像模型的几何(深度图)和物理(衰减)特性。这种公式允许模型推断出产生颜色校正图像的参数$\beta_c^\star,A_c^\star$。在这项工作中使用的辛克霍恩损失如下:
\[\mathcal{L}_s=\tilde{S}_{\lambda}(J(r;\Theta,t),H(r)) \tag{15}\]最终目标是:
\[\mathcal{L}=\mathcal{L}_c+\alpha\mathcal{L}_s \tag{16}\]IV. 实验与结果
A. 训练细节
网络在JAX中训练,修改自mipNeRF仓库[21][25]。使用初始学习率5e-4和最终学习率5e-6,并采用学习率衰减。使用Adam优化器[26]。网络训练600,000次迭代,在Nvidia GeForce RTX 3090 GPU上大约需要8小时。我们使用$\alpha = 0.5$来加权Sinkhorn损失。
B. 数据集
我们在开源UWBundle数据集上评估了我们的系统,该数据集包含36张在实验室控制水箱环境中浸没的人工岩石平台图像[27]。使用水下相机以割草机模式(水下测量常用模式)捕获了场景的多个视角。岩石平台在场景中包含一个色板,这使其非常适合进行颜色校正的定量评估。使用KinectFusion[28]制作了空气中的真实3D重建。
C. 与基准方法比较
我们将WaterNeRF的性能与图像处理、基于物理的水下图像恢复和基于深度学习的方法等先前工作进行比较。
FUnIE-GAN – 这是一个基于条件GAN的模型,学习退化水下图像和恢复图像之间的映射[29]。
水下雾线模型 – 使用雾线先验,该模型估计后向散射光和透射图。然后,根据灰世界假设下的性能,从Jerlov的水类型分类中选择衰减系数[8],[30]。
直方图均衡化 – 我们使用直方图均衡化图像为优化算法提供初始化点,并将这些图像作为基准进行比较。每个颜色通道分别进行直方图均衡化。
HENeRF – 这是直接在直方图均衡化图像上训练的mipNeRF。它没有颜色校正模块,并使用直方图均衡化像素值的MSE损失。
WaterNeRF-No Sinkhorn – 这是对Sinkhorn损失的消融实验。WaterNeRF使用校正颜色预测$J(r; \Theta, t)$和直方图均衡化颜色$H(r)$之间的MSE损失进行训练。
D. 定性评估
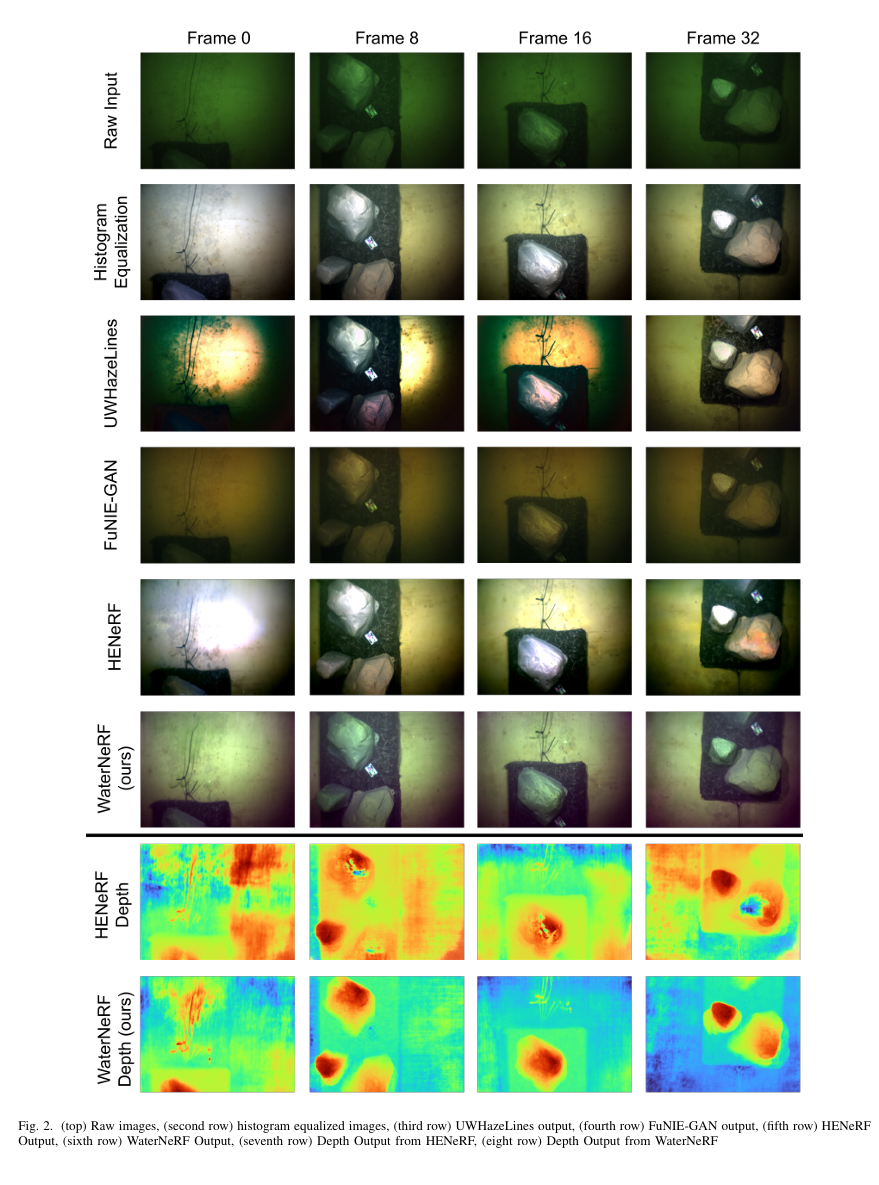
图2.(顶部)原始图像,(第二行)直方图均衡化后的图像,(第三行)UWHazeLines输出,(第四行)FUnIE - GAN输出,(第五行)HENeRF输出,(第六行)WaterNeRF输出,(第七行)HENeRF的深度输出,(第八行)WaterNeRF的深度输出。
图2显示了在UWBundle数据集上与基准方法的定性性能比较。直方图均衡化和HENeRF产生视觉上吸引人的图像,但校正后的图像在多个视角之间不一致。雾线模型存在晕影伪影。WaterNeRF和FUnIE-GAN在多个图像中都产生一致的颜色校正图像,但FUnIE-GAN不执行深度估计。HENeRF和WaterNerF都产生场景的密集图。由于直方图均衡化图像不一致,HENeRF产生有孔洞的较差深度结构。WaterNeRF产生没有明显不连续性的密集深度图。
E. 颜色校正评估
我们用于颜色校正的主要评估指标是像素空间中的平均角度误差$\bar{\psi}$[8]。$I(x_i)$是像素位置$x_i$处的颜色,$\langle R_g, G_g, B_g\rangle$是真实像素位置处的颜色。先对颜色进行归一化处理,然后通过以下公式计算两个单位向量之间的角度(以度为单位):
\[\bar{\psi}=\cos^{-1}\left(\frac{I(x_i)\cdot\langle R_g, G_g, B_g\rangle}{\|I(x_i)\|\cdot\|\langle R_g, G_g, B_g\rangle\|}\right) \tag{17}\]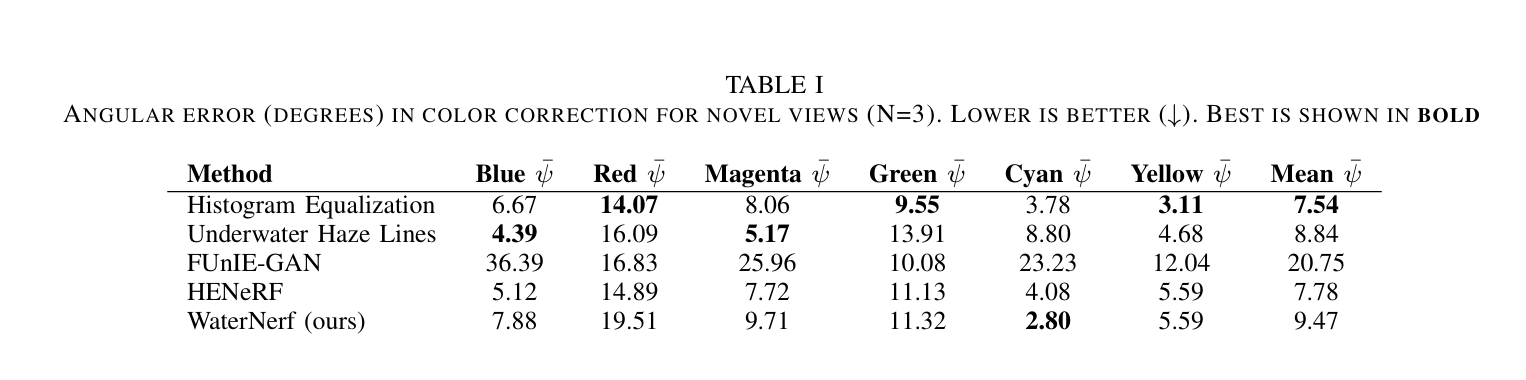
表I. 新视图颜色校正中的角度误差(度)($N = 3$)。数值越低越好($\downarrow$)。最佳结果以粗体显示。
表I展示了从三张包含色卡的保留测试图像的校正图像中,色卡块的平均角度误差。该误差是在空气中拍摄的色卡块与水下校正图像中的色卡块之间计算得出的。对于每种颜色,从色块中选取一个矩形区域并求平均值。这个平均颜色用于计算$\bar{\psi}$。直方图均衡化在颜色准确性方面表现最佳。然而,需要注意的是,对于包含色卡的图像,直方图均衡化过程会有偏差。与其他方法相比,FUnIE - GAN在颜色准确性方面存在不足。WaterNeRF能够以与直方图均衡化和雾线模型相当的准确性校正图像。
F. 水下图像质量
接下来,我们使用水下图像质量指标(UIQM)[31]评估恢复图像的质量。UIQM考虑了水下图像色彩丰富度度量(UICM)、水下图像对比度度量(UIConM)和水下图像清晰度度量(UISM):
\[UIQM = c_1\times UICM + c_2\times UISM + c_3\times UIConM \tag{18}\]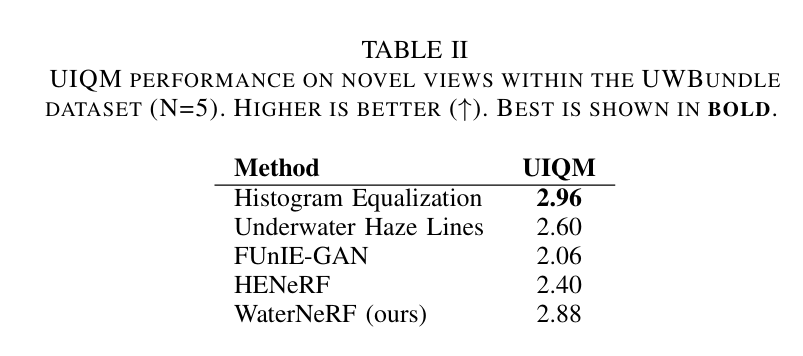
表II. 在UWBundle数据集内新视图上的UIQM性能($N = 5$)。数值越高越好($\uparrow$)。最佳结果以粗体显示。
我们使用文献[31]中的系数:$c_1 = 0.282$,$c_2 = 0.2953$,$c_3 = 3.5753$。表II报告了在UWBundle数据集上,基线方法和WaterNeRF生成的校正图像的UIQM值。有5张保留测试图像,其中3张包含色卡,2张不包含色卡。WaterNeRF生成的水下图像质量高于雾线模型和FUnIE - GAN,但低于直方图均衡化处理的图像质量。
G. 场景一致性评估
为了量化颜色校正的一致性,我们计算在场景中跟踪的像素经过强度归一化后的RGB值的平均标准差。我们将此称为场景一致性指标(SCM)。首先,我们在水下图像的帧之间找到一组SURF特征$\mathcal{P}$,其中$N = \vert \mathcal{P}\vert $ [32]。然后,我们在$N_x$张校正图像中跟踪与特征$x\in\mathcal{P}$相对应的像素$x_i\in\mathbb{R}^3$,$i\in[1,N_x]$。最后,我们计算这些像素的RGB值的标准差。该指标提供了一种量化同一场景中不同视图下校正方法一致性的方式。
\[SCM=\frac{1}{N}\sum_{x\in\mathcal{P}}\sqrt{\frac{\sum_{x_i\in x}(x_i - \mu_x)^2}{N_x}} \tag{19}\]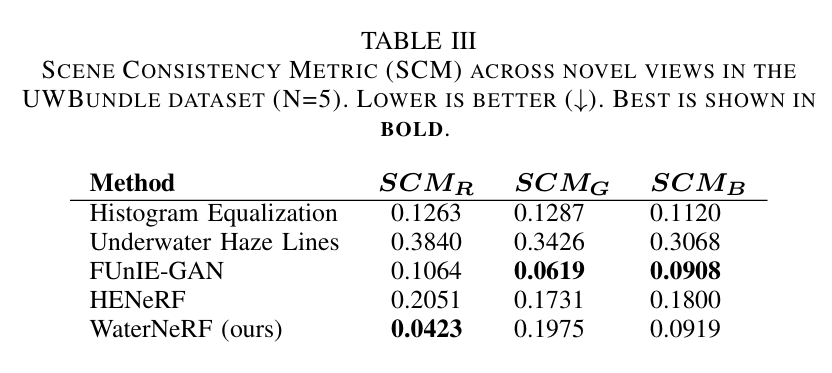
表III. UWBundle数据集中新视图的场景一致性指标(SCM)($N = 5$)。数值越低越好($\downarrow$)。最佳结果以粗体显示。
表III报告了场景一致性指标(SCM)。每个颜色通道分别进行报告。FUnIE - GAN在SCM指标上表现良好。WaterNeRF在跨场景图像上也表现出一致性,其红色通道的SCM最低,蓝色通道的SCM第二低。
H. 深度图评估

图3.(左)WaterNeRF的三维重建。颜色校正后的RGB点被投影到由密集深度图提供的点云中。(右)真实的空中三维扫描。
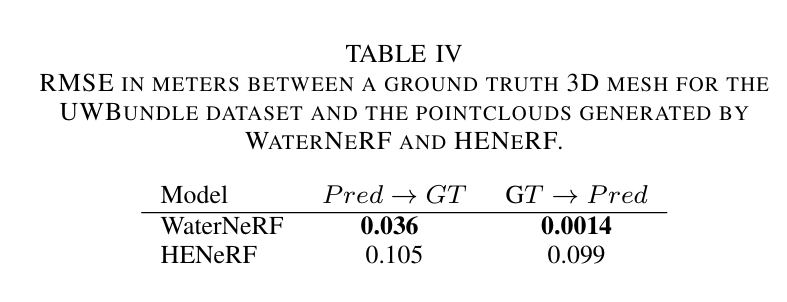
表IV. UWBundle数据集的真实三维网格与WaterNeRF和HENeRF生成的点云之间以米为单位的均方根误差(RMSE)。
除了水下和校正后的彩色图像外,WaterNeRF还为生成的每个新视角提供密集深度图。为评估这种重建的质量,我们使用相机的内参矩阵将2D像素投影到3D点。最后,我们使用CloudCompare[33]计算点云与UWBundle数据集的真实网格之间的距离。表IV报告了由WaterNeRF生成的场景点云与真实网格之间的评估。WaterNeRF在深度重建方面表现出比HENeRF更高的准确性。图3显示了从WaterNerf的密集深度估计和颜色校正图像投影的样本点云。
I. 消融实验:WaterNeRF-无Sinkhorn损失

图4. WaterNeRF在没有辛克霍恩损失的情况下生成的两个视图,导致恢复结果不一致。
我们进行了无Sinkhorn损失的消融研究,以证明对直方图均衡化图像的直接MSE损失可能产生不一致的视图(图4)。
V. 结论与未来工作
本工作是首次利用神经体积渲染技术处理水下场景,实现水下场景的新视角合成,同时进行完整场景恢复和密集深度估计。值得注意的是,WaterNeRF改进的场景一致性和3D重建能力证明了学习衰减参数对新视角合成的重要性。未来工作包括使用WaterNeRF的3D物体信息和颜色来指导海洋机器人平台的水下操作和探索任务。
评论