论文链接:Arxiv Link
发表时间(Arxiv):
[v1] Wed, 16 Oct 2024 05:59:33 UTC (29,447 KB) [v2] Thu, 19 Dec 2024 03:23:32 UTC (29,448 KB)
3D高斯溅射在机器人领域的应用综述
作者: Siting Zhu, Guangming Wang, Dezhi Kong, Hesheng Wang Senior Member, IEEE
摘要: 在机器人领域,环境的密集3D表示一直是长期追求的目标。虽然之前的神经辐射场(NeRF)表示因其隐式的、基于坐标的模型而流行,但最近出现的3D高斯溅射(3DGS)在其显式辐射场表示方面展示了显著的潜力。通过利用3D高斯基元进行显式场景表示并实现可微渲染,3DGS在实时渲染和照片级真实感性能方面表现出显著优势,这对机器人应用非常有益。在本综述中,我们全面探讨了3DGS在机器人领域的应用。我们将相关工作的讨论分为两个主要类别:3DGS的应用和3DGS技术的进展。在应用部分,我们探讨了3DGS如何在各种机器人任务中从场景理解和交互的角度进行应用。在3DGS进展部分,我们关注3DGS自身特性在适应性和效率方面的改进,旨在提升其在机器人中的性能。然后,我们总结了机器人领域最常用的数据集和评估指标。最后,我们指出了当前3DGS方法的挑战和局限性,并讨论了3DGS在机器人领域的未来发展。
关键词: 3D高斯溅射, 机器人, 场景理解与交互, 挑战与未来方向
1 引言
神经辐射场(NeRF)[1]的出现推动了机器人领域的发展,特别是在感知、场景重建和与环境交互的能力方面。然而,这种隐式表示由于其低效的逐像素光线投射渲染优化而存在局限性。3D高斯溅射(3DGS)[2]的出现通过其显式表示解决了这一低效问题,并通过溅射技术实现了高质量和实时的渲染。具体而言,3DGS使用一组具有可学习参数的高斯基元对环境进行建模,提供了场景的显式表示。在渲染过程中,3DGS采用溅射技术[3]将3D高斯投影到给定相机姿态的2D图像空间中,并应用基于瓦片的光栅化器进行加速,从而实现实时性能。因此,3DGS在提升机器人系统性能和扩展其能力方面具有更大的潜力。
随着3DGS在2023年的首次亮相,已有多篇综述论文[4][5][6][7][8][9]发表,展示了该领域的发展。Chen等人[4]提出了第一篇关于3DGS的综述,描述了3DGS方法的最新进展和关键贡献。Fei等人[5]提出了一个统一的框架,用于对现有3DGS工作进行分类。Wu等人[7]的综述涵盖了传统的溅射方法和近年来的基于神经网络的3DGS方法,展示了3DGS溅射技术的发展。Bao等人[9]基于3DGS技术提供了更详细的分类。此外,Dalal等人[6]专注于3DGS中的3D重建任务,而Bagdasarian等人[8]总结了基于3DGS的压缩方法,展示了3DGS在特定领域的优势和劣势。然而,现有的3DGS综述要么提供了广泛的3DGS工作分类,要么专注于3DGS的实时视图合成,缺乏对机器人领域的详细总结。
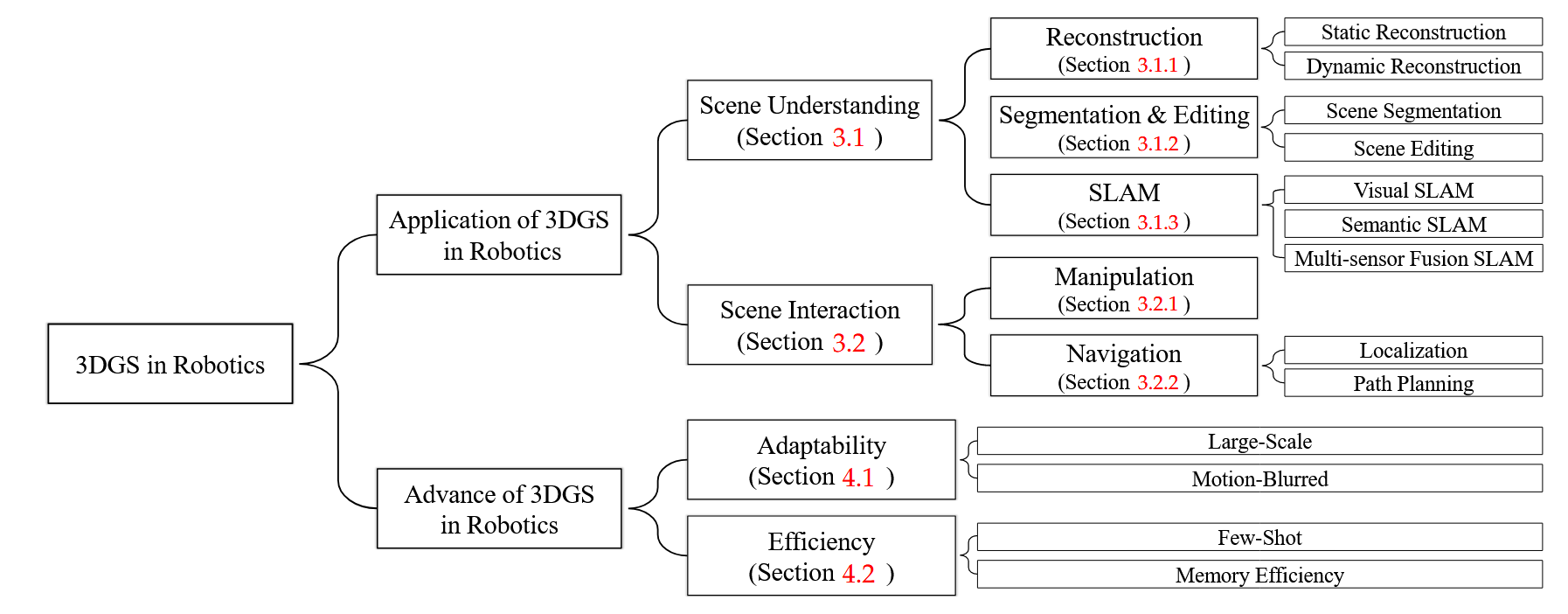
图1:3D高斯溅射(3DGS)在机器人领域的分类。
因此,在本文中,我们提供了3DGS在机器人领域的全面总结和详细分类。我们介绍了3DGS在机器人中的应用,并对基于3DGS的机器人应用相关工作进行了详细分类。此外,我们总结了增强3DGS表示以适用于机器人系统的潜在解决方案。最后,我们展示了基于3DGS的工作的性能评估,并讨论了3DGS在机器人领域的未来发展。本文的整体框架如图1所示。
第2节简要介绍了3DGS的核心概念和数学原理。第3节对3DGS在机器人中的各种应用方向进行了分类,并详细介绍了特定方向的相关工作。第4节讨论了改进3DGS表示的各种进展,旨在增强其在机器人任务中的能力。此外,第5节总结了在3DGS机器人应用中使用的数据集和评估指标,并对现有方法在不同机器人方向上的性能进行了比较。第6节讨论了3DGS在机器人中的挑战和未来方向。最后,第7节总结了本综述的结论。
2 背景
2.1 三维高斯场景表示(3DGS)理论
3DGS [2] 引入了一种显式辐射场表示方法,用于三维场景的实时高质量渲染。
该技术使用一组三维高斯基元对环境进行建模,表示为\(G = \{g_1, g_2, \ldots, g_n\}\)。每个三维高斯基元\(g_i\)由一组可学习的属性参数化,包括三维中心位置\(\mu_i \in \mathbb{R}^3\)、三维协方差矩阵\(\Sigma_i \in \mathbb{R}^{3\times3}\)、不透明度\(o_i \in [0, 1]\),以及由球谐函数(SH)系数表示的颜色\(c_i\) [10],用于实现与视角相关的外观。这些属性使得单个高斯基元可以进行空间紧凑表示,如下所示:
\[g_i(x) = e^{-\frac{1}{2}(x - \mu_i)^T\Sigma_i^{-1}(x - \mu_i)}. \tag{1}\]这里,三维高斯的协方差矩阵\(\Sigma\)类似于描述椭球体的构型,计算方式为\(\Sigma = RSS^TR^T\)。\(S\)是缩放矩阵,\(R\)表示旋转。
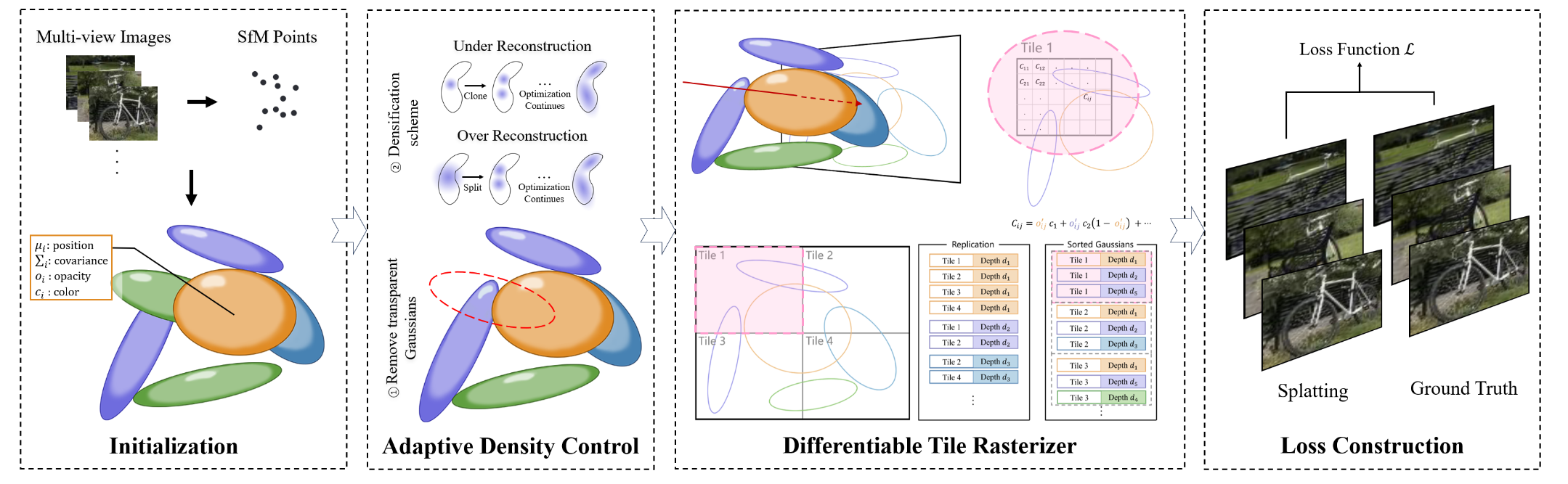
图2:3DGS前向过程的示意图。
3DGS的输入是多视图图像,这些图像通过运动恢复结构(SfM)[11] 生成稀疏点云。然后利用该点云创建初始的三维高斯基元。接着,通过比较真实图像和渲染图像来更新三维高斯基元的属性,从而优化三维高斯表示。这里,渲染结果是通过点扩散(splatting)过程生成的,同时使用了设计的可微的基于图块的光栅化器来加速。此外,3DGS采用自适应密度控制来管理用于场景表示的三维高斯基元的数量。图2展示了3DGS的正向过程。接下来,首先描述3DGS中的点扩散过程,该过程能够实现快速渲染。随后,详细介绍三维高斯优化中使用的损失函数。此外,还会介绍3DGS中采用的自适应密度控制技术。该技术能够从初始稀疏的高斯集合中获得更密集的高斯集合,从而改进场景表示。
点扩散(Splatting):在这个过程中,将三维高斯基元投影到二维图像空间进行渲染。给定视图变换\(W\),相机坐标中的投影二维协方差矩阵计算为\(\Sigma' = JW\Sigma W^TJ^T\),其中\(J\)是投影变换的仿射近似的雅可比矩阵。因此,最终像素颜色\(C\)可以通过对在给定像素处重叠的三维高斯点扩散进行\(\alpha\)混合来计算,高斯基元按深度顺序排序:
\[C = \sum_{i\in N} c_i\alpha_i \prod_{j = 1}^{i - 1}(1 - \alpha_j), \tag{2}\]其中最终不透明度\(\alpha_i\)的计算公式为:
\[\alpha_i = o_i \exp\left(-\frac{1}{2}(x' - \mu_i')^T\Sigma_i'^{-1}(x' - \mu_i')\right), \tag{3}\]其中\(x'\)和\(\mu_i'\)是投影空间中的坐标。
损失函数:为了优化三维高斯属性,损失定义为点扩散图像与真实图像之间的差异。具体而言,损失函数是\(L_1\)损失和D - SSIM(差分结构相似性)项的组合:
\[\mathcal{L} = (1 - \lambda)\mathcal{L}_1 + \lambda\mathcal{L}_{\text{D-SSIM}}, \tag{4}\]其中\(\lambda\)是权重系数,在3DGS中设置为0.2。
自适应密度控制:在高斯优化过程中,3DGS采用周期性自适应增密策略以实现细节重建。该策略聚焦于缺少几何特征的区域,或者高斯分布过度扩展的区域,这些区域在视图空间中的位置梯度都较大。对于重建不足的区域,会复制小的高斯模型并将其向位置梯度方向移动。在重建过度的区域,具有高方差的大高斯模型会被分割成两个较小的高斯模型。此外,3DGS会移除几乎透明的高斯模型,即不透明度低于特定阈值的模型。
总之,3DGS引入了一种使用三维高斯基元的新型显式辐射场表示方法,为三维场景建模提供了一种紧凑、高效且灵活的途径。三维高斯表示的应用,结合点扩散过程、可微优化和自适应密度控制,使得3DGS成为对复杂三维环境进行实时高质量渲染的强大工具。
3 3DGS在机器人中的应用
3DGS的优势,包括其显式辐射场表示和快速渲染能力,使其成为机器人应用中极具吸引力的表示选择。这些特性对于实现机器人中的全面场景理解以及通过与环境的交互执行特定任务至关重要。
3.1 场景理解
3.1.1 重建
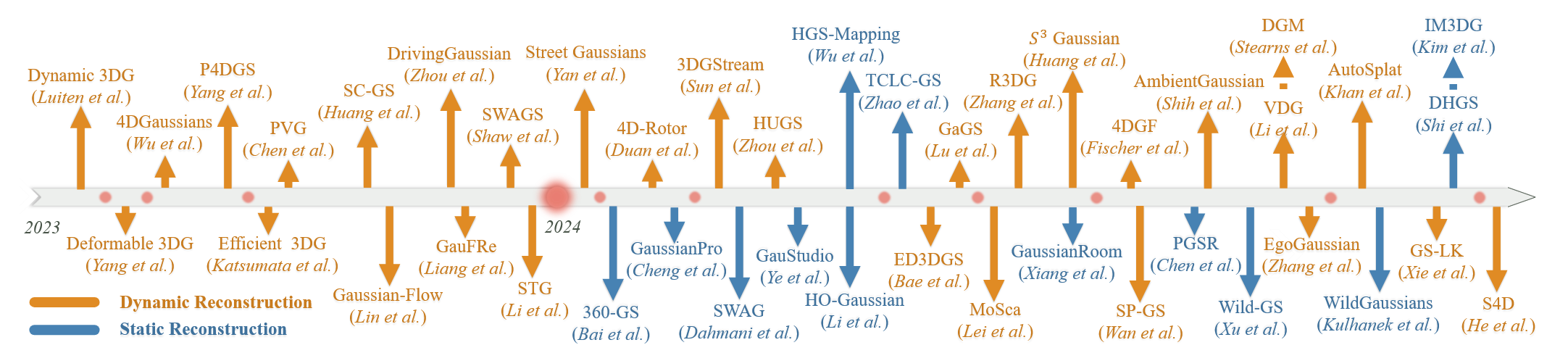
图3:按时间顺序:3DGS用于场景重建。图中的红点表示月份,这也适用于其他图。
机器人中的场景重建是指使用传感器数据构建环境的三维表示的过程。3DGS作为一种有前景的场景表示方法,能够精确建模环境的几何和外观信息,从而实现照片级真实感的场景重建。基于3DGS的重建可以根据是否对环境中的动态物体进行建模,分为静态重建和动态重建。我们在图3中展示了相关工作的时间线。
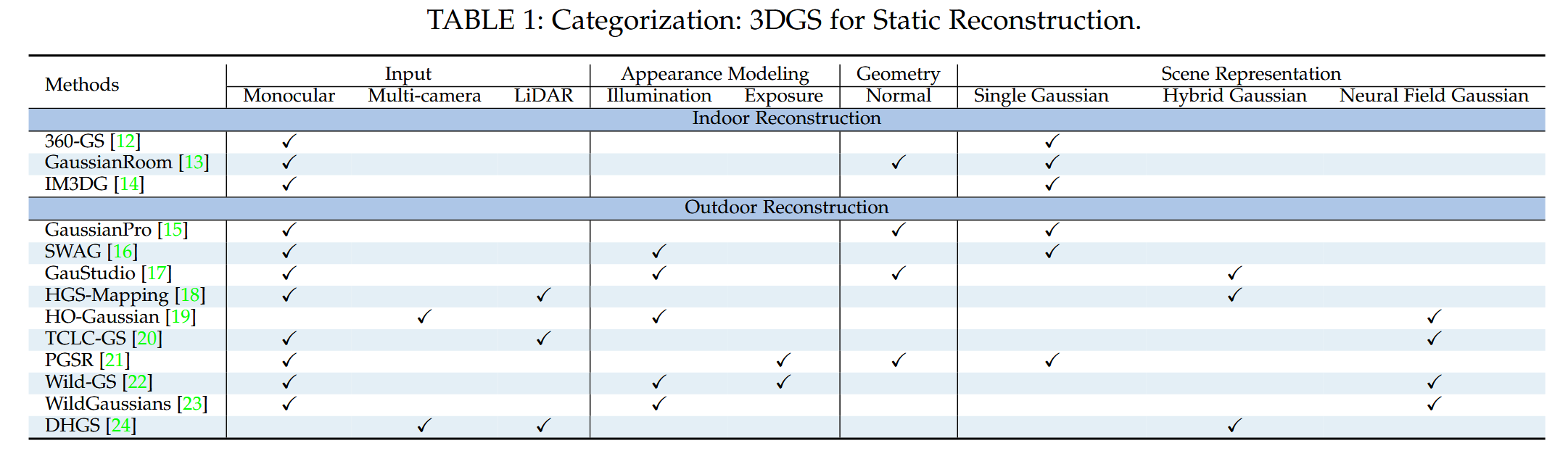
表1:分类:3DGS用于静态重建。
静态重建。静态场景重建专注于具有时间不变几何特性的环境。考虑到室内和室外环境在重建任务中由于尺度、结构复杂性和光照条件的差异而呈现不同的挑战,我们将讨论分为室内和室外场景重建。此外,静态重建方法的有效性在很大程度上依赖于输入传感器数据、场景的外观和几何建模以及所选的场景表示方法。这些因素在决定重建过程的准确性、细节水平和效率方面起着至关重要的作用。因此,我们基于以下四个标准对现有的静态重建方法进行分类:(i) 输入传感器的类型,(ii) 外观建模的方法,(iii) 几何法向约束的使用,(iv) 场景表示方法,如表1所示。特别地,外观建模包括光照和曝光,因为场景光照条件的变化和相机曝光问题会导致环境外观建模不准确。重建中的场景表示可以分为使用单一3D高斯表示(Single Gaussian)、结合多个高斯表示进行联合场景建模(Hybrid Gaussian)以及将3D高斯与神经网络结合(Neural Field Gaussian)。
室内场景具有明确的空间布局和丰富的纹理。360-GS [12] 引入了基于布局的3D高斯正则化,以减少由于未约束区域引起的漂浮物。为了对输入的全景图进行建模,它将3D高斯投影到单位球体的切平面上,然后将其映射到球面投影上。GaussianRoom [13] 结合了一个可学习的神经SDF场来指导高斯的密集化和修剪,从而实现精确的表面重建。Kim等人 [14] 采用混合表示进行室内场景重建,使用网格表示房间布局,并使用3D高斯重建其他物体。
室外场景面临额外的挑战,例如变化的光照和尺度变化。SWAG [16] 使用可学习的多层感知器(MLP)网络对场景外观进行建模,以应对室外环境中变化的光照条件。Wild-GS [22] 通过提取高层次的2D外观信息并构建位置感知的局部外观嵌入,利用分层外观建模来处理不同视图之间的复杂外观变化。WildGaussians [23] 通过为每个高斯添加可训练的嵌入,并使用一个小型MLP集成图像和外观嵌入,增强了3DGS,以应对野外环境中的变化光照条件。PGSR [21] 提出了一个相机曝光补偿模型,以解决室外场景中光照变化大的问题。此外,场景的不同部分表现出不同的特征,需要专门的建模。例如,天空区域缺乏几何细节且位于图像的远处,无法通过世界坐标中的普通3DGS有效表示。此外,由于路面是平坦的,使用3D高斯进行路面建模会导致表示中的大量冗余。为了解决这一挑战,HGS-Mapping [18] 采用混合高斯表示,包括用于天空建模的球形高斯、用于路面建模的2D高斯平面以及用于路边景观建模的3D高斯。同样,GauStudio [17] 使用球形高斯图将天空与前景分开建模。DHGS [24] 采用2DGS [25] 进行路面表示,并应用基于SDF的表面约束进行路面优化。此外,HO-Gaussian [19] 将基于网格的体积与3DGS管道结合,以促进天空、远距离和低纹理区域几何信息的学习。TCLC-GS [20] 使用混合表示,结合彩色3D网格和分层八叉树特征,以丰富城市区域中3D高斯表示的特性。GaussianPro [15] 引入了平面损失来正则化室外场景中高斯的几何形状。由于现实场景复杂多变,静态重建需要具备准确建模环境中外观和几何信息的能力。对于静态场景表示,混合高斯相比单一高斯能够更准确地建模整个场景。这是因为混合高斯可以根据场景中不同区域的几何结构采用不同的建模方法,而单一高斯对整个场景采用统一的建模方法。此外,神经场高斯由于结合了MLP网络,在光照建模方面表现出优于单一高斯和混合高斯的优势,更有利于建模光照信息。
动态重建
在现实世界的机器人应用中,动态物体的存在是不可避免的。普通的3DGS表示主要设计用于静态建模,难以对动态物体的运动进行建模,因为它们不可避免地会干扰高斯参数的优化。因此,在动态场景中学习基于3DGS的模型至关重要。对于动态重建,关键问题是如何区分动态和静态组件,以及如何对动态物体进行建模。
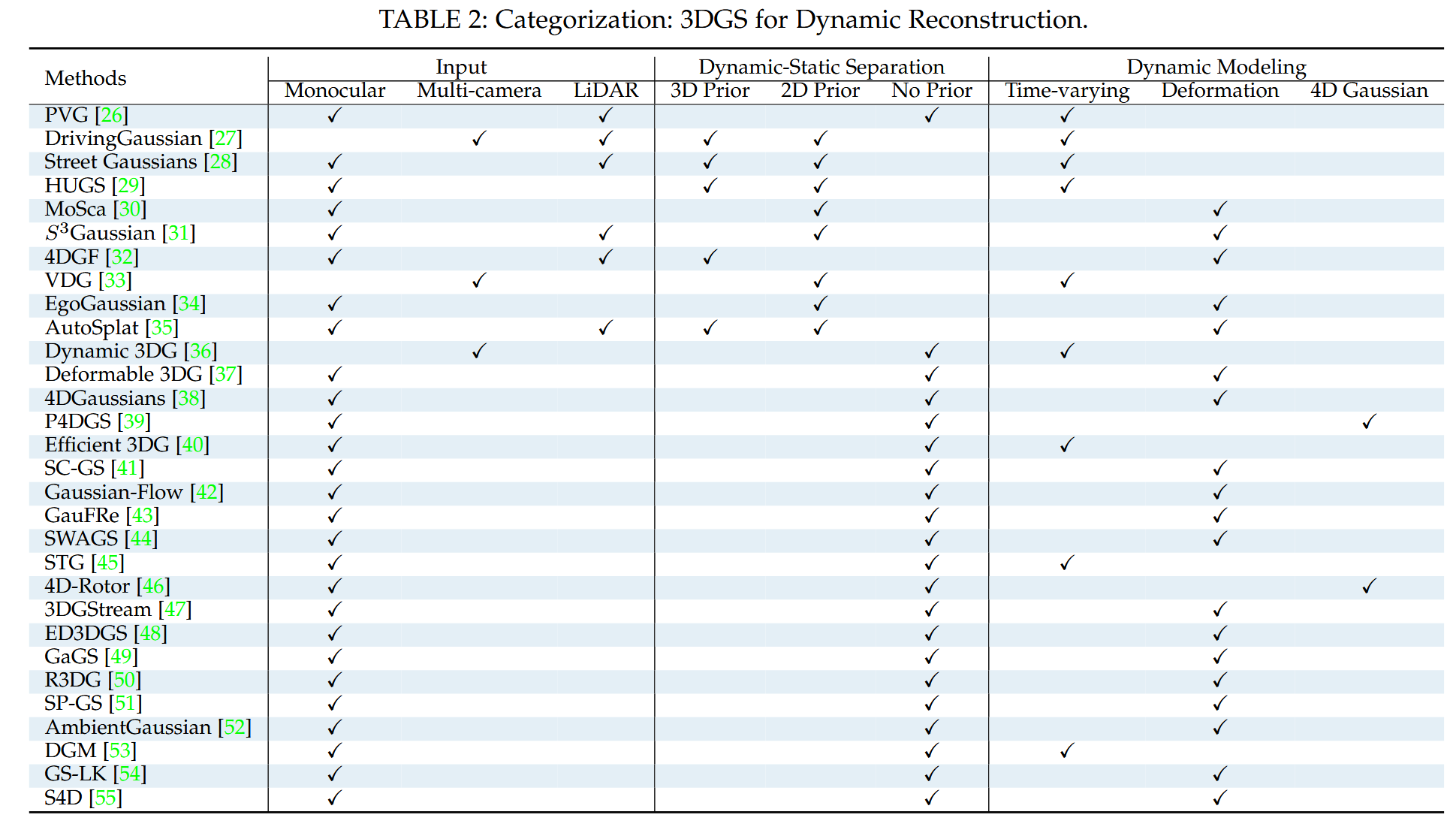
表2:分类:3DGS用于动态重建。
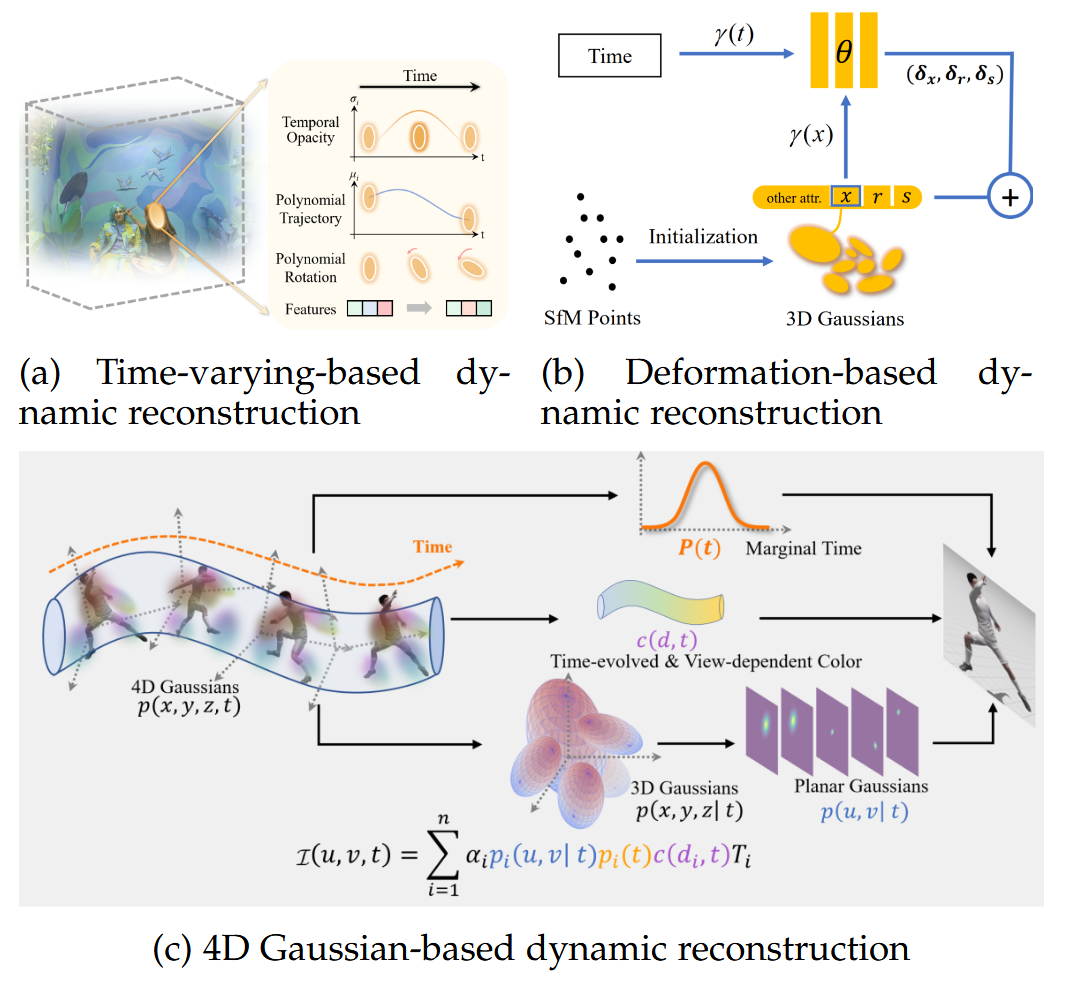
图4:3DGS用于动态重建的示意图。图4a、图4b和图4c分别源自 [45]、[37] 和 [39]。
因此,我们基于以下三个标准对现有的基于3DGS的动态重建方法进行分类:(i) 输入传感器的类型,(ii) 分离场景中静态和动态物体的方法,(iii) 动态建模方法,如表2所示。具体而言,场景中静态和动态组件的分离可以通过应用运动或语义掩码来检测图像中动态物体的位置(称为2D先验),使用3D边界框来识别动态物体(3D先验),或者同时建模静态和动态元素(无先验)。动态建模方法可以分为时变建模、基于变形的建模和4D高斯建模,如图4所示。
在时变建模方法中,每个3D高斯位置被表示为时间的函数,以建模位置的时间变化。Dynamic 3DG [36] 通过局部刚性约束正则化高斯的运动和旋转。PVG [26] 和 VDG [33] 通过将普通3DGS的均值和不透明度修改为以生命峰值为中心的时间相关函数,引入了基于周期性振动的时间动态。DrivingGaussian [27] 和 Street Gaussians [28] 利用复合动态高斯图来表示多个随时间移动的物体。HUGS [29] 扩展了3DGS以建模动态场景中的相机曝光,并利用光流预测进行动态分离。Efficient 3DG [40] 使用傅里叶近似建模位置动态的时间变化。STG [45] 在每个高斯中存储特征而不是SH系数,以准确编码与视图和时间相关的辐射。
基于变形的方法将运动建模为相对于先前观察的静态场的规范空间的变形。S3Gaussian [31] 和 4DGaussians [38] 采用多分辨率时空场网络来表示动态3D场景,并跟随Hexplane [56] 使用轻量级MLP解码变形。4DGF [32] 利用神经场来表示序列和物体特定的外观和几何变化。AutoSplat [35] 估计每个前景高斯的残差SH,以建模前景物体的动态外观。SC-GS [41] 引入稀疏控制点与MLP结合,用于建模场景运动。Gaussian-Flow [42] 通过在时域中多项式拟合和频域中傅里叶级数拟合,建模每个高斯属性的时间相关残差。SWAGS [44] 将序列划分为窗口,并为每个窗口训练一个单独的动态3DGS模型,允许规范表示发生变化。3DGStream [47] 使用神经变换缓存(NTC)来建模3DGS的平移和旋转。ED3DGS [48] 引入粗粒度和细粒度的时间嵌入来表示动态场景的慢速和快速状态。GaGS [49] 提取3D几何特征并将其集成到学习3D变形中。GS-LK [54] 通过推导Lucas-Kanade风格的速度场,引入对动态3DGS中规范场的解析正则化。S4D [55] 使用部分可学习的控制点进行局部6自由度运动表示。
4D高斯方法将时空视为一个整体,并将时间维度纳入3D高斯基元中,形成用于动态建模的4D高斯基元。P4DGS [39] 采用由各向异性椭圆参数化的4D高斯,这些椭圆可以在空间和时间中任意旋转,以及由4D SH系数表示的与视图和时间相关的外观。与P4DGS [39] 中使用等斜四元数表示4D旋转不同,4D-Rotor [46] 引入4D转子来表征4D旋转,受 [57] 启发,实现了空间和时间旋转的解耦。
当前的3DGS动态建模方法已经展示了其在重建动态场景方面的能力。在小规模场景中,这些方法可以以统一的方式重建动态和静态组件。然而,在处理更大规模的自动驾驶场景时,统一重建的计算负担变得越来越高。为了解决这个问题,需要额外的先验信息来区分动态和静态区域,然后分别进行重建。这些方法的局限性在于它们依赖于额外的先验信息,例如3D边界框,这些信息并不容易获得。因此,未来动态重建的发展,除了提高动态建模的精度外,还要利用3DGS的几何建模,在最小先验知识的情况下进行更大规模的动态重建。
3.1.2 分割与编辑
图5:按时间顺序:3DGS用于场景分割与编辑。
场景分割和编辑的时间线如图5所示。
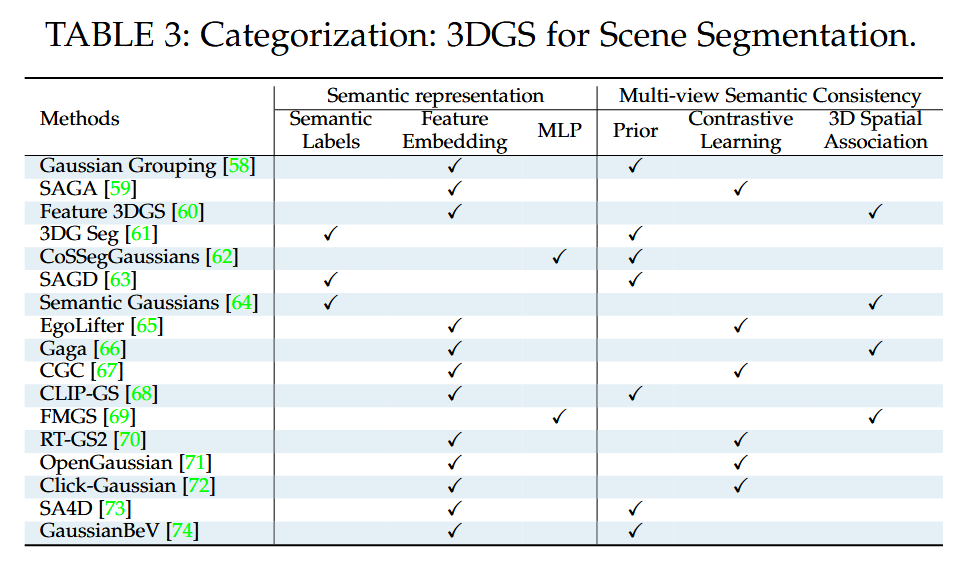
表3:分类:3DGS用于场景分割。
场景分割。场景分割是指将观察到的场景划分为不同的组件,每个组件代表不同的语义类别。与2D分割相比,3D分割更有效地满足机器人在现实环境中的操作和导航需求。3DGS提供了一种创新的场景表示方法,能够从2D图像中实现3D语义分割。我们基于以下两个标准对现有的3DGS分割方法进行分类:(i) 3DGS语义表示的建模方法,(ii) 在多个2D图像输入中保持语义标签一致的方法,如表3所示。具体而言,语义表示建模方法可以分为三种类型:语义标签、特征嵌入和MLP。前两种方法将语义标签和特征嵌入作为3D高斯基元的附加属性,而第三种方法使用MLP网络进行语义建模。此外,当前的3DGS分割方法依赖于SAM模型 [75] 为开放词汇分割提供2D语义标签。由于SAM模型只能确保单张图像内的语义一致性,不同图像中对应的语义区域可能无法一致地标记,这导致3D语义建模中的歧义。为了解决这个问题,现有的3DGS工作采用先验、对比学习或3D空间关联来实现多视图语义一致性,以进行3D语义分割。
基于先验的方法使用预训练的跟踪器 [76] 或输入多视图一致的2D掩码,以在视图之间传播和关联掩码。Gaussian Grouping [58] 利用2D身份损失和3D正则化损失进行高斯优化,利用跨视图的连贯分割。SAGD [63] 引入高斯分解模块来解决3D分割中的边界粗糙问题。CoSSegGaussians [62] 设计了一个多尺度空间和语义高斯特征融合模块,以实现紧凑的分割。CLIP-GS [68] 通过引入相邻视图的语义来消除同一对象内的语义歧义,从而实现连贯的语义正则化。SA4D [73] 引入时间身份特征场,以学习高斯在时间上的身份信息,用于4D分割。GaussianBeV [74] 将图像特征转换为鸟瞰图(BEV)高斯表示,以端到端的方式进行BEV分割。
对比学习工作通过在对齐嵌入空间中对应掩码的特征的同时分离不同掩码的特征,以实现跨视图语义一致性。对于语义高斯优化,SAGA [59] 引入了基于交并比(IoU)较高的像素应具有更相似特征的原则的对应损失。OpenGaussian [71] 提出了一个掩码内平滑损失和掩码间对比损失,以促进不同实例之间的特征多样性。CGC [67] 提出了一个空间相似性正则化损失,以强制特征向量的空间连续性,解决场景未被充分观察区域的误分类问题。此外,RT-GS2 [70] 将从图像中提取的视图相关特征与通过对比学习获得的视图无关的3D高斯特征融合,以增强不同视图之间的语义一致性。ClickGaussian [72] 将粗到细级别的特征融入高斯,并从跨视图的噪声2D片段中聚类全局特征,以增强全局语义一致性。
3D空间关联方法使用3D语义特征提取网络或在空间坐标中进行标签投票,以实现语义一致性。Semantic Gaussians [64] 构建从3D语义网络获得的3D特征与从2D特征投影映射的3D高斯特征之间的损失,以优化3DGS语义表示。Gaga [66] 采用3D感知的掩码关联过程,其中使用3D感知的记忆库根据每个掩码与记忆库中现有组之间的共享3D高斯重叠率为其分配一致的组ID。FMGS [69] 通过将基础模型CLIP [77] 和DINO [78] 的视觉语言特征蒸馏到3DGS中,集成了语义和语言表示以进行场景理解。此外,该工作通过利用DINO特征的像素对齐损失增强了空间精度。
总结来说,3DGS相比其他场景表示方法,能够更快、更准确地进行3D语义建模,以实现3D语义分割。这一改进归因于3DGS的高斯辐射场表示,使其能够进行详细的场景建模,以及3DGS的高效渲染能力,使其能够更快地优化。此外,通过利用高斯的显式结构和基于3DGS的语义分割结果,可以轻松地对场景表示中的语义对象进行编辑和操作。这种能力促进了3DGS在各种下游机器人任务中的应用,例如操作和自主导航,在这些任务中理解和与环境中的语义实体交互至关重要。
场景编辑
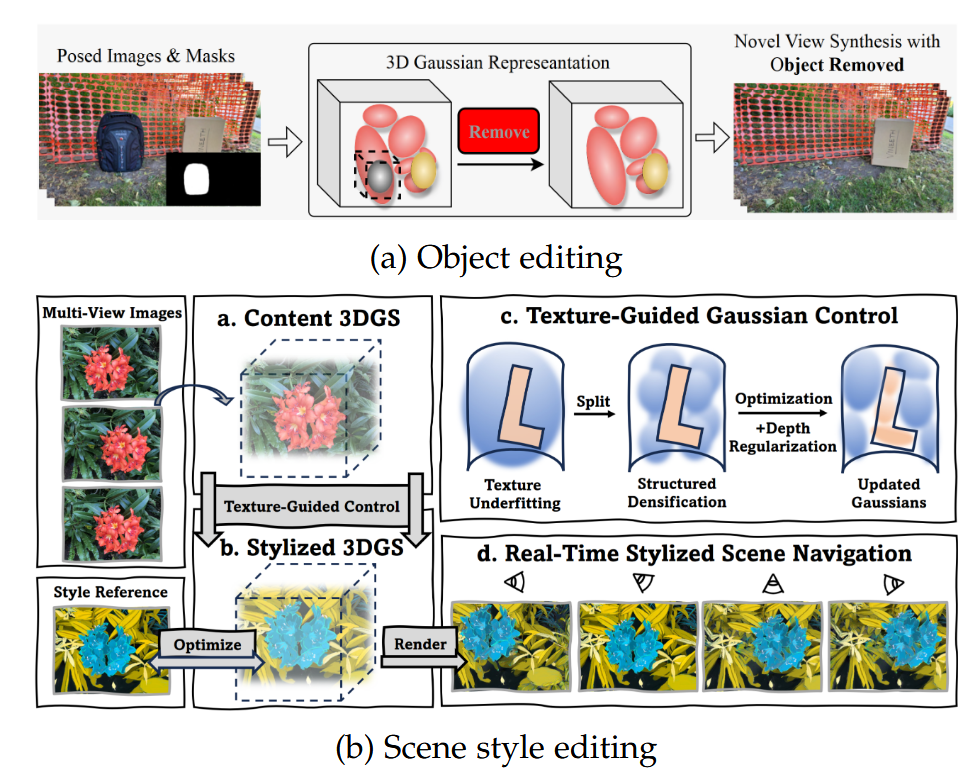
图6:3DGS用于场景编辑的示意图。图6a和图6b分别源自 [79] 和 [80]。
场景编辑是指根据用户提示修改场景元素,以达到预期效果。编辑后的场景为机器人提供了宝贵的训练资源,当现实世界的数据收集具有挑战性或耗时较长时,这是一种实用的替代方案。3DGS表示的使用通过利用高斯的显式结构简化了场景编辑过程,使得可以直接重新定位高斯元素以实现编辑。我们将相关工作分为对象编辑和场景风格编辑,如图6所示。
对象编辑方法包括对象插入和移除 [79][81][82][83] 以及外观和纹理编辑 [84]。对象插入和移除编辑的挑战在于保持几何一致性和纹理连贯性,这是由于高斯基元的离散特性。GScream [79] 采用交叉注意力特征正则化,将周围区域的准确纹理传播到修复区域,确保高斯表示的纹理连贯性。Feature Splatting [83] 将视觉语言嵌入到3D高斯中,以实现基于文本提示的编辑。对于外观和纹理编辑,Texture-GS [84] 建立了几何(3D高斯)和外观(2D纹理图)之间的连接,以促进外观编辑。
基于文本提示的对象编辑方法 [85][86][87][88][89][90][91][92][93][94][95] 都利用了预训练的扩散模型 [96],这使得能够高效地使用文本提示进行精确编辑,并结合丰富的先验知识以增强编辑对象的质量和连贯性。GaussCtrl [87] 使用从ControlNet [97] 获得的自一致深度图来引导几何一致性。此外,该工作引入了来自不同视图的潜在代码的自我和交叉视图注意力,以确保外观一致性。VcEdit [88] 和 TrAME [93] 采用跨扩散阶段获得的图的交叉注意力。
场景风格编辑方法 [80][98][99][100][101][102][103] 基于风格提示生成多样化的风格化场景数据,这可以缩短数据收集周期,并提高使用该数据训练的机器人系统的鲁棒性。
3.1.3 同时定位与地图构建(SLAM)
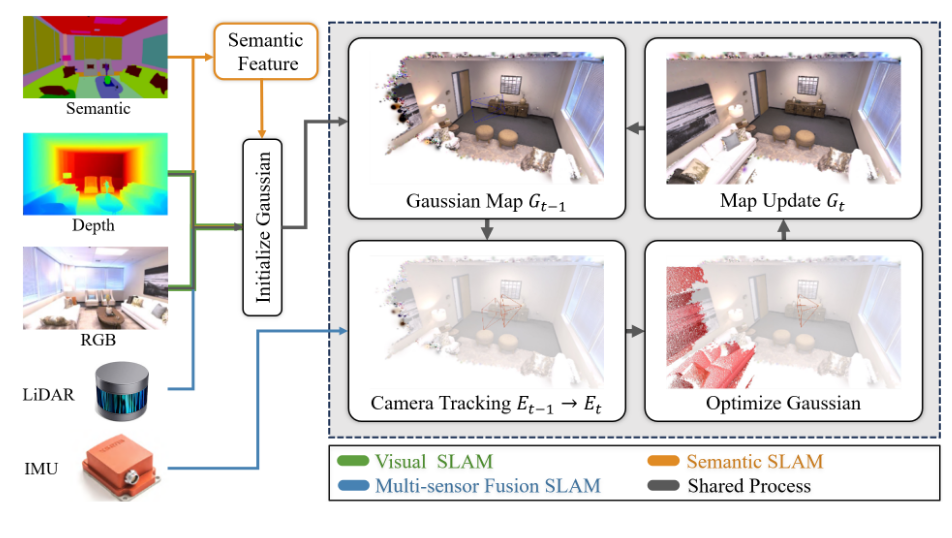
图8:3DGS用于SLAM的示意图。部分图像取自SplaTAM [104]。
图7:按时间顺序:3DGS用于SLAM。
我们根据所使用的传感器以及对环境的理解程度,将基于3DGS的SLAM分为视觉SLAM、多传感器融合SLAM和语义SLAM。基于3DGS的SLAM过程如图8所示。我们还在图7中展示了相关研究的时间线。与基于神经辐射场(NeRF)的SLAM相比,基于3DGS的SLAM方法利用三维高斯的显式表示来进行无边界且逼真的建图。
视觉SLAM:视觉SLAM是指同时进行相机的密集颜色建图和定位的过程。考虑到准确的深度信息对于在构建密集高斯地图时提供几何监督至关重要,我们根据输入的相机数据是否包含深度信息,将对视觉SLAM的讨论分为RGB - D SLAM和RGB SLAM。RGB - D SLAM方法[104]、[105]、[106]、[107]、[108]、[109]、[110]、[111]、[112]、[113]、[114]、[115]、[116]、[117]、[118]具有准确的深度输入,能够为密集建图和位姿估计提供良好的几何约束。对于SLAM过程而言,确定何时扩展地图以及如何实现精确的跟踪结果至关重要。SplaTAM[104]利用现有高斯地图的轮廓渲染来识别场景中的哪些部分是新内容,从而指导地图的扩展和相机位姿的优化。GaussianSLAM[105]和NGM - SLAM[106]专注于逐步构建高斯子地图,以实现局部地图优化。MG - SLAM[107]结合场景的结构先验来生成约束,以解决重建地图中的间隙和缺陷问题。此外,CGSLAM[109]提出了一种新颖的深度不确定性模型,用于构建一致且稳定的三维高斯地图。I2SLAM[116]将成像过程集成到SLAM中,以克服运动模糊和外观变化的问题。LoopSplat[117]在线检测回环闭合,并通过3DGS配准计算子地图之间的相对回环边约束,以保证全局地图的一致性。为了实现精确跟踪,GS - SLAM[110]采用从粗到细的方法,以避免因图像中的伪影导致相机跟踪漂移。GS - ICP SLAM[111]利用3DGS的三维显式表示进行跟踪,通过使用G - ICP[119]进行高斯地图匹配,直接回归估计相机位姿。TAMBRIDGE[112]联合优化稀疏重投影误差和密集渲染误差,从而减少跟踪中的累积误差。尽管这些进展提高了SLAM的准确性,但在SLAM过程中生成的详细三维高斯地图需要大量的内存资源。为了解决这个问题,CompactSLAM[113]提出了一种基于滑动窗口的在线掩码方法,以去除冗余的高斯椭球,实现紧凑表示。RTG - SLAM[114]使用单个不透明高斯而不是多个重叠高斯来拟合表面的局部区域,以减少建图中的内存消耗。
RGB SLAM方法[120]、[121]、[122]、[123]、[124]、[125]、[126]缺乏准确的深度输入,因此需要多视图约束或深度估计等额外信息来恢复场景的三维几何结构。MonoGS[120]和MotionGS[121]采用正则化项和多视图优化,在深度未知的场景中约束场景几何信息。Photo - SLAM[122]最小化帧中匹配的二维几何关键点与相应三维点之间的重投影误差,以实现几何一致性。此外,MGS - SLAM[123]利用深度估计和DPVO[127]来恢复场景的三维几何结构。MonoGSLAM[124]采用基于DPVO[127]的面片图和基于CLIP[77]的回环闭合优化来指导场景几何结构的估计。Splat - SLAM[125]引入密集光流估计和DSPO(视差、尺度和位姿优化)来实现准确的深度恢复。
现有的基于3DGS的视觉SLAM的准确性高度依赖于精确的深度信息。RGB SLAM方法由于缺乏准确的深度信息,在3DGS几何重建中经常出现误差。尽管深度估计技术可以为RGB SLAM提供深度信息,但其有限的准确性会导致SLAM性能下降。此外,当前基于3DGS的视觉SLAM系统大多在室内环境中进行测试和评估,因为在室外场景中深度测量不可靠。因此,视觉SLAM尚未解决的关键问题是在深度信息不准确的情况下提高几何重建精度,从而在各种环境中实现高精度的SLAM。
多传感器融合SLAM
多传感器融合SLAM在SLAM系统中整合来自不同传感器的数据,以实现精确的建图和稳健的跟踪。根据用于3DGS几何重建的主要传感器类型,我们将多传感器融合SLAM方法分为基于激光雷达(LiDAR)的和基于图像深度估计的两类。
基于激光雷达的方法将从激光雷达获取的精确点云作为三维高斯几何表示的初始输入。LIV - GaussMap[128]利用从基于迭代扩展卡尔曼滤波(IESKF)的激光雷达 - 惯性系统中获取的点云,为场景提供初始的高斯结构。Gaussian - LIC[129]进行激光雷达 - 惯性 - 相机里程计来实现跟踪。激光雷达点被投影到相应的图像上,通过查询像素值进行着色,然后用于初始化三维高斯。MMGaussian[130]使用点云配准算法[131]进行跟踪,并在跟踪模块失效时利用多帧相机约束进行重定位。
基于图像深度估计的方法将单目密集深度估计结果用作构建高斯地图的几何监督。MM3DGS SLAM[132]利用惯性测量单元(IMU)预积分进行初始位姿估计,并在渲染结果和观测值之间构建损失函数以优化位姿。由于深度估计输出的是相对深度,因此使用皮尔逊相关系数,结合实际尺度信息来计算估计深度图和渲染深度图之间的深度损失。
语义SLAM
语义SLAM将对环境的语义理解融入地图构建中,同时估计相机位姿。与视觉SLAM和多传感器融合SLAM相比,语义SLAM能够对场景进行密集的语义建图,这对于导航和操作等下游任务至关重要。由于原始的3DGS表示缺乏语义信息,在基于3DGS的语义SLAM中已开发出两种融入语义的方法:基于颜色的方法和基于特征的方法。
对于基于颜色的方法,SGS - SLAM[133]利用与高斯相关联的语义颜色进行语义表示。然而,这种基于颜色的语义建模方法忽略了语义中固有的更高级信息。对于基于特征的语义融合方法,SemGauss - SLAM[134]将语义嵌入融入三维高斯中进行语义表示,并使用多视图约束执行语义引导的光束平差,以实现高精度的语义SLAM。NEDS - SLAM[135]受[136]的启发,提出了一个融合模块,将语义特征与外观特征相结合,以解决语义特征的空间不一致问题。GS3LAM[137]引入深度自适应尺度正则化,以减少语义高斯中不规则高斯尺度导致的几何表面模糊问题。
3.2 场景交互
图9:按时间顺序:3DGS用于场景交互。
导航和操作是机器人与环境交互的基本方面。相关工作的时间线如图9所示。
3.2.1 操作
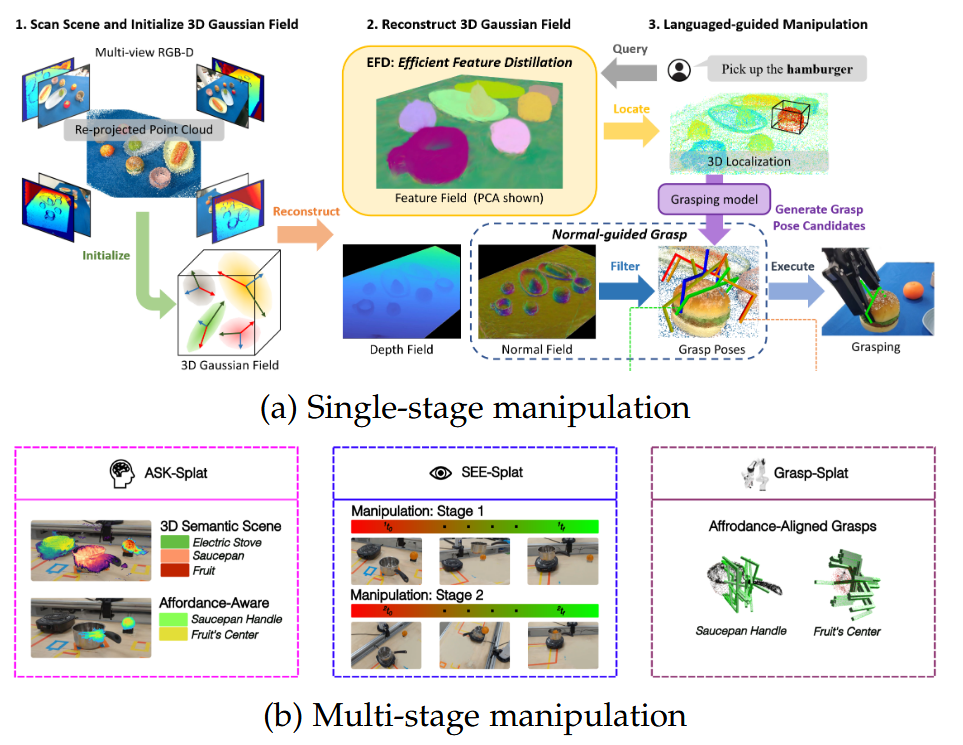
图10:3DGS用于操作的示意图。图10a和图10b分别源自 [138] 和 [139]。
操作是指使用机械臂或夹爪执行各种任务,以替代人类的手。与基于NeRF的操作方法不同,3DGS采用显式辐射场表示,构建场景并提供对场景中物体位置信息的直接访问。因此,在基于3DGS的操作中,无需额外的物体姿态估计。根据任务是否需要考虑环境的动态变化,操作任务可以分为单阶段和多阶段。这些变化是由操作本身引起的物体移动所导致的,如图10所示。
在单阶段操作中,抓取任务通过单一的连续动作完成,因此在此过程中环境被视为静态。GaussianGrasper [138] 通过高效的特征蒸馏重建3D高斯特征场,以支持语言引导的操作任务,并使用渲染的法线过滤不可行的抓取姿态。
对于多阶段操作,任务通过一系列动作完成,每个阶段中物体的移动导致环境的动态变化。ManiGaussian [140] 提出了动态3DGS框架,以建模场景级时空动态,并构建高斯世界模型来参数化动态3DGS模型中的分布,以实现多任务机器人操作。Object-Aware GS [141] 将高斯表示建模为时间变量,并采用以物体为中心的动态更新来进行多阶段操作的动态建模。
与建模动态变化不同,Splat-MOVER [139] 使用3D语义掩码和填充的场景编辑模块来可视化机器人与环境交互导致的物体运动。此外,该工作引入了GSplat表示,将语言语义和抓取可行性的潜在代码蒸馏到3D场景中,以实现场景理解。
3.2.2 导航
机器人导航涉及两个重要且相互关联的组成部分:定位和路径规划。定位解决的是在环境中确定机器人自身位置的挑战。基于定位结果,机器人执行路径规划,即确定到达目的地的最优路径的过程。3DGS作为详细的场景表示,适用于高精度导航任务。
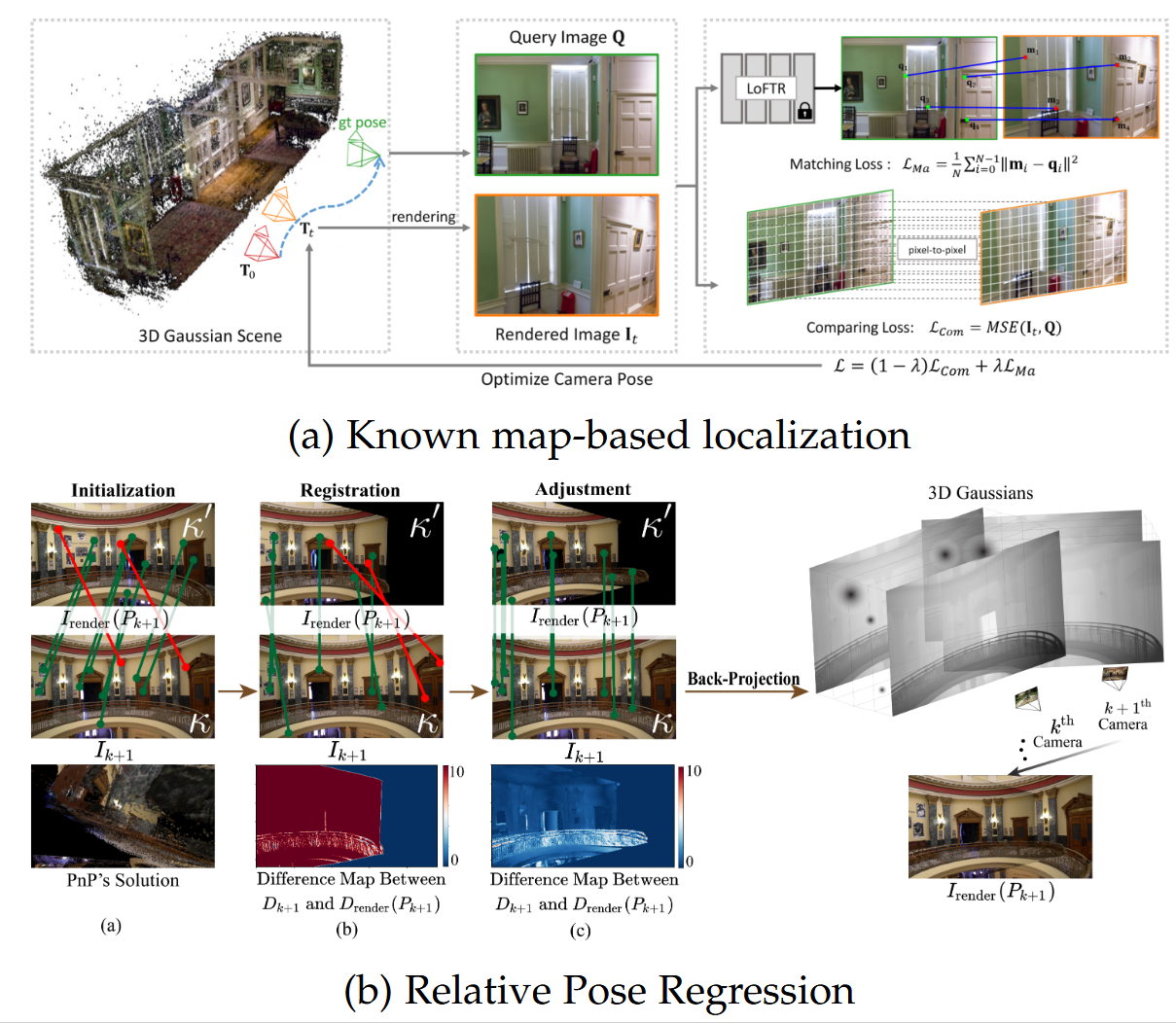
图12:3DGS用于定位的示意图。图12a和图12b分别源自 [142] 和 [143]。
定位。定位是指通过处理传感器数据估计6自由度(DoF)姿态(位置和方向)。我们根据是否具备先验全局地图,将基于3DGS的定位分为基于已知地图的定位和相对姿态回归,如图12所示。
对于基于已知地图的定位,iComMa [142] 计算查询图像与从预建高斯地图中获取的渲染图像之间的残差,以优化相机姿态。3DGS-ReLoc [144] 将3DGS地图存储为带有KD树的2D体素图,以实现高效的空间查询,并通过暴力搜索在全局地图中匹配查询图像来实现重定位。Liu等人 [145] 从3DGS生成伪场景坐标,以初始化和增强场景坐标回归。6DGS [146] 通过选择从高斯地图椭球表面投影的一束光线并学习注意力图以输出光线像素对应关系,来估计相机位置以进行姿态优化。
在相对姿态回归方面,CF-3DG [147] 估计相对相机姿态,该姿态可以将上一帧的局部3D高斯地图转换为与当前帧对齐的像素渲染。GGRt [148] 设计了一个联合学习框架,包括一个迭代姿态优化网络(用于估计相对姿态)和一个可泛化的3D高斯模型(用于预测高斯)。COGS [143] 检测训练视图与相应渲染图像之间的2D对应关系,以回归相对姿态。GaussReg [149] 探索使用3DGS表示进行3D场景配准,以估计场景的相对姿态。GSLoc [150] 将曝光自适应模块集成到3DGS模型中,以提高在域偏移下两幅图像匹配的鲁棒性,从而实现图像的精确姿态回归。
路径规划。我们根据机器人是否主动探索环境进行重建和规划,将路径规划分为主动规划和非主动规划。
在主动规划方面,GS-Planner [151] 维护一个体素图来表示未观测到的体积。该体素图被集成到溅射过程中,从而实现对未观测空间的探索。此外,该工作利用不透明度的物理概念制定了一个机会约束,用于在3DGS地图中进行安全的主动规划。
对于非主动规划,GaussNav [152] 构建语义高斯地图,并将该地图转换为2D BEV网格用于导航。此外,通过从多个视角渲染对象生成一组描述性图像,这些图像用于匹配和识别目标位置以进行路径规划。Splat-Nav [153] 通过在高斯地图上离散化自由空间生成安全路径,以实现安全导航。这种离散化是通过高斯椭球之间的交集测试实现的。Beyond Uncertainty [154] 利用3DGS地图动态评估每个路径点的碰撞风险,并引导风险感知的下一个最佳视图选择,以实现高效且安全的机器人导航。
4 三维高斯场景表示(3DGS)在机器人领域的进展
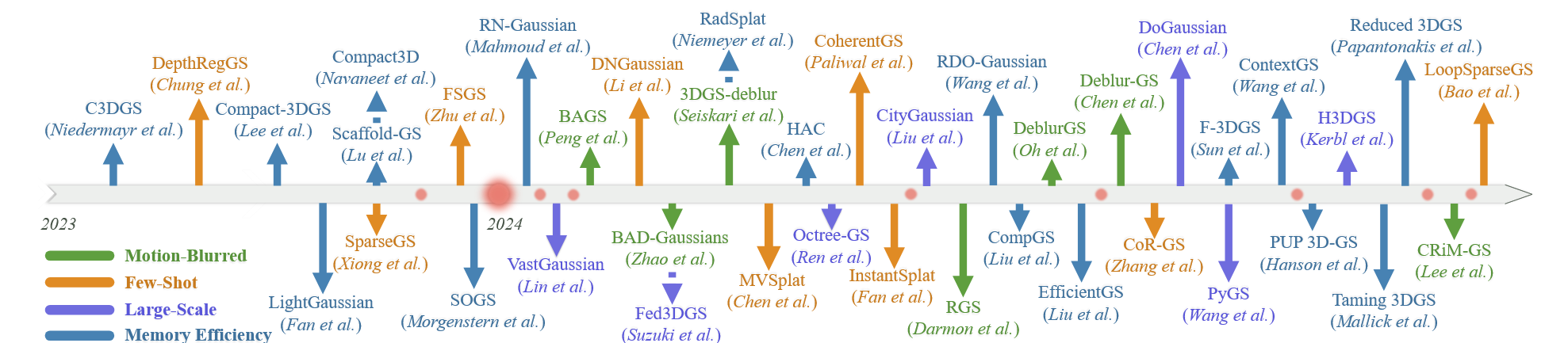
图11:按时间顺序:3DGS的进展。
由于原始的3DGS [2] 存在局限性,各种新颖的变体模型对3DGS表示进行了适应性修改,提高了其在机器人应用中的有效性。图11展示了专注于增强3DGS在机器人应用方面特性的相关研究时间线。
4.1 适应性
增强原始3DGS的适应性包括提升其在大规模环境中的性能,以及对运动模糊的抗性,使其在各种不可预测的场景中更有效和可靠。
4.1.1 运动模糊
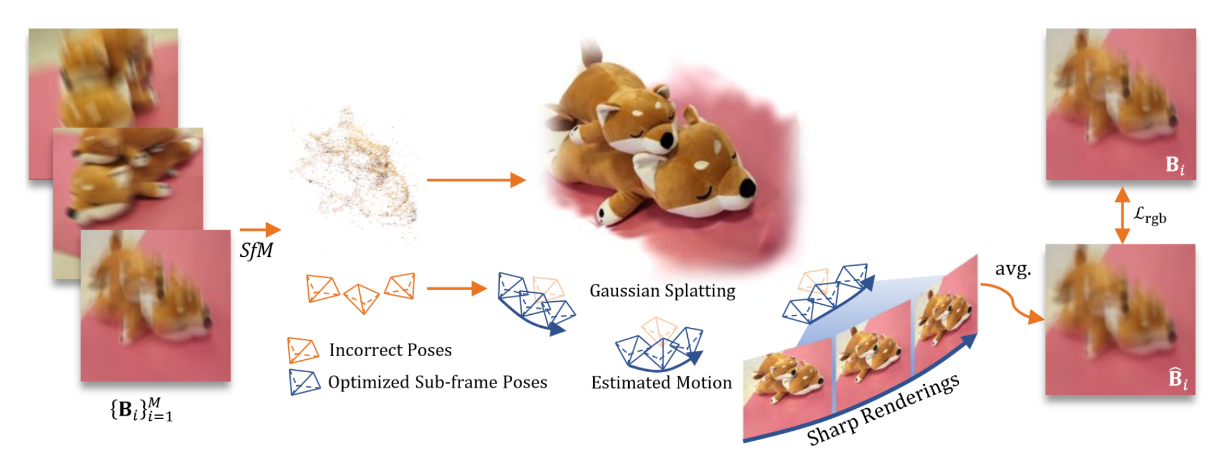
图13:3DGS用于去运动模糊的示意图。图源自 [155]。
在机器人领域,捕获图像的运动模糊是一个常见的挑战,主要由机器人的高速运动和较慢的快门速度引起,会导致图像质量下降。因此,去模糊对于恢复图像质量和增强机器人系统的视觉感知至关重要。去模糊方法可分为两类:物理建模和隐式建模。物理建模侧重于基于运动模糊的形成来理解和模拟模糊过程;隐式建模则利用多层感知器(MLP)网络直接学习模糊图像和清晰图像之间的映射,而无需对底层物理过程进行显式建模,如图13所示。
物理建模方法[155]、[156]、[157]通过对相机曝光时间内捕获的虚拟清晰图像进行平均来模拟运动模糊图像。然后,这些方法在模拟的模糊图像和实际观测到的模糊图像之间构建损失函数,以优化高斯表示和相机位姿,确保构建的场景清晰且无运动模糊。RGS [158] 将运动模糊建模为相机位姿上的高斯分布,以在给定噪声下获得用于优化的期望图像。3DGSdeblur [159] 通过在像素坐标中近似运动并调整高斯均值以反映该运动,简化了运动模糊建模。CRiM - GS [160] 应用神经常微分方程(neural ODEs)[161] 对曝光时间内相机的连续运动轨迹进行建模,并通过渲染和平均沿该轨迹采样的多个位姿的图像来获得去模糊图像。
在隐式建模方面,BAGS [162] 引入了一个模糊提议网络来对图像模糊进行建模,并生成一个质量评估掩码,用于指示出现模糊的区域。
4.1.2 大规模场景
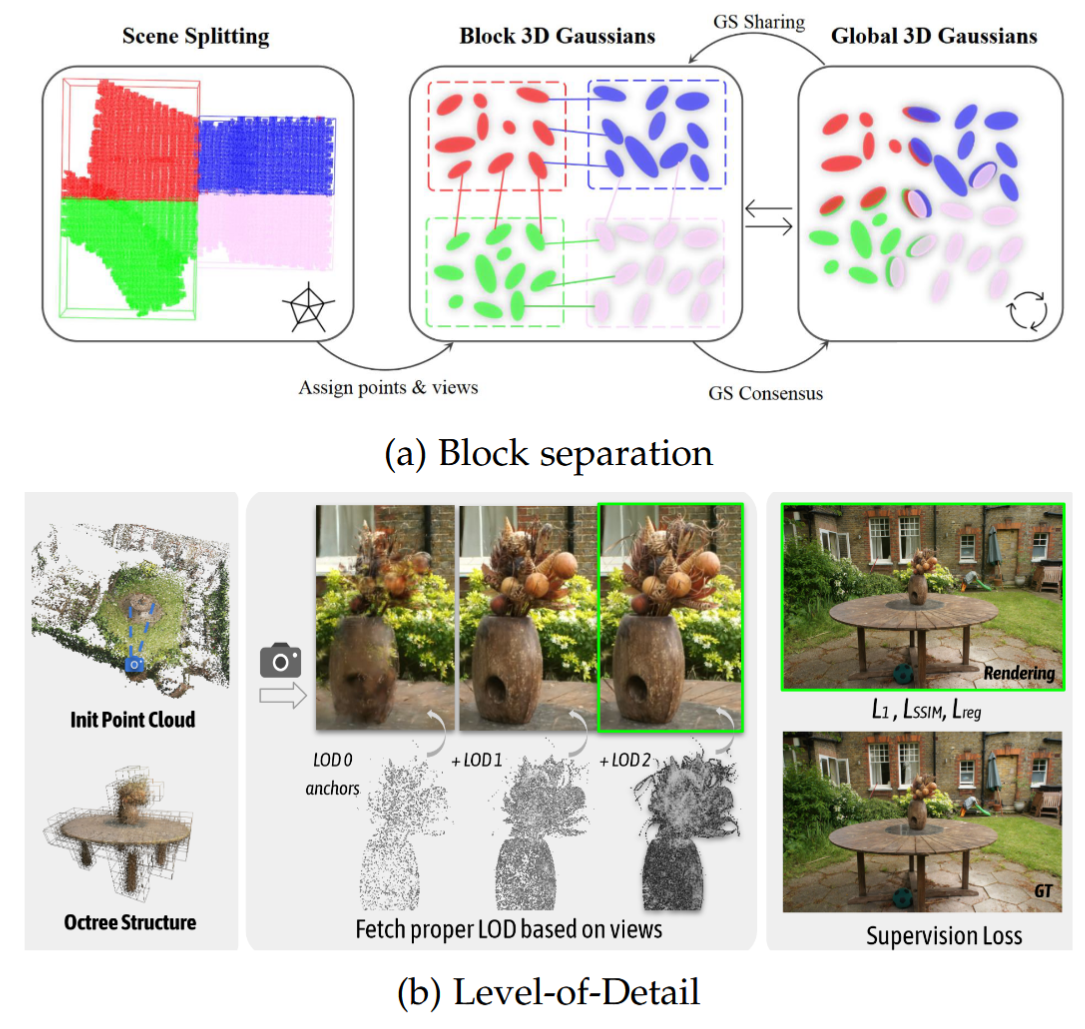
图14:3DGS用于大规模重建的示意图。图14a和图14b分别源自 [163] 和 [164]。
原始的3DGS表示在大规模重建时需要数百万个三维高斯模型,这导致训练时对GPU内存需求很高,同时训练和渲染时间也很长。为了解决大规模重建问题,现有方法[163]、[164]、[165]、[166]、[167]、[168]、[169]将场景划分为独立的块进行单独训练(块分离),并使用分层分辨率级别(细节层次)对场景进行建模,如图14所示。
DoGaussian[163]、H3DGS[166]和CityGS[165]采用分而治之的策略,将场景划分为空间上相邻的块,这些块可以独立并行地进行优化。Fed3DGS[167]利用数百万客户端对大规模数据进行分散处理,以减轻中央服务器的计算负担。Octree - GS[164]引入八叉树结构来进行多层次的场景表示,并采用细节层次分解以实现高效渲染。PyGS[168]采用将三维高斯模型组织成金字塔层次的分层结构,以便在不同的细节层次上表示大规模场景。VastGaussian[169]引入了渐进式分区策略,将大场景划分为多个单元进行并行优化。
4.2 效率
原始的3DGS由于其显式表示方式,存在着巨大的存储需求,并且在进行场景建模时需要大量的多视图信息。然而,在现实世界的机器人应用中,如此巨大的存储需求对于存储全局地图来说是低效的。此外,为了进行重建而获取大量多视图数据的需求也导致了数据利用效率低下。因此,提高3DGS在机器人领域的效率主要集中在两个方面:内存效率,旨在降低巨大的存储需求;少样本学习,通过从最少的多视图信息中实现有效的重建来提高数据利用率。
4.2.1 内存效率
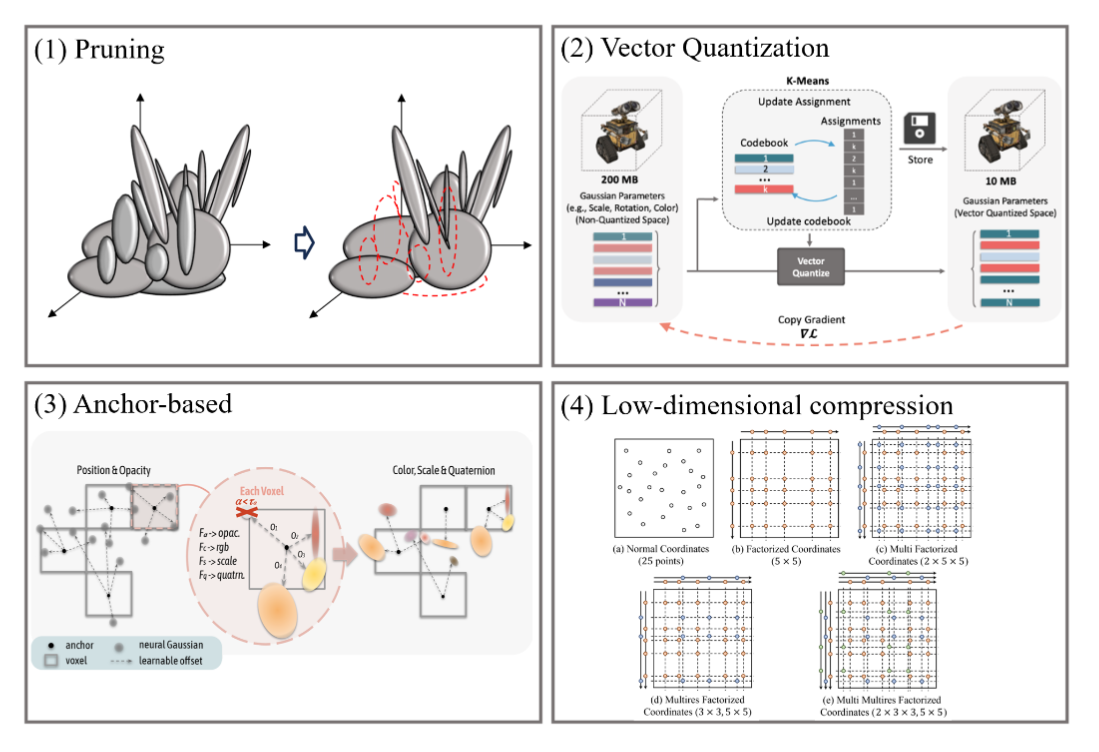
图15:3DGS用于内存效率的示意图。子图(1)到子图(4)分别取自 [170]、[171]、[172] 和 [173]。
三维高斯模型的显式表示需要大量的存储空间。为了解决这个问题,现有方法主要采用四种途径:剪枝、矢量量化、基于锚点和低维压缩,以减少机器人应用中三维高斯场景表示所需的存储空间,如图15所示。直观地说,减少对场景贡献较小的三维高斯基元的数量可以降低总体存储需求,这就是所谓的剪枝[170]、[174]、[175]、[176]、[177]、[178]、[179]、[180]、[181]。Compact3DGS[170]和RDO - Gaussian[174]去除了尺度较小和不透明度较低的高斯模型。LightGaussian[175]、RadSplat[176]和EfficientGS[177]对在所有训练视图中对像素光线贡献较低的高斯模型进行剪枝。PUP 3D - GS[178]采用了从重建误差的海森矩阵得出的敏感度分数,对空间不确定性较高且对重建质量贡献较小的高斯模型进行剪枝。Reduced 3DGS[179]识别出高斯基元密集的区域,并对与其他高斯模型显著重叠的高斯模型进行剪枝。RN - Gaussian[180]和Taming 3DGS[181]根据位置以及与现有高斯模型的相关性来限制高斯模型的克隆和分裂,以减少高斯模型的数量。
此外,矢量量化方法[170]、[171]、[179]、[182]将高斯参数转换为码本,以紧凑地表示高斯属性。基于锚点的方法[172]、[183]、[184]、[185]使用一组锚点基元对附近相关的三维高斯模型进行聚类,并根据锚点的属性预测它们的属性,从而实现高效内存的三维场景表示。HAC[183]利用无组织的锚点和结构化哈希网格之间的关系来对锚点属性进行上下文建模。ContextGS[185]将锚点划分为多个级别以实现紧凑表示。
而且,低维压缩方法[173]、[186]在一维或二维空间中表示三维高斯模型以实现紧凑存储。SOGS[186]将原本无结构的三维高斯模型映射到二维网格上以减少内存占用。F - 3DGS[173]提出了一种分解坐标方案,在每个轴或平面上保持一维或二维坐标,并通过张量积生成三维坐标。
4.2.2 少样本学习
由于可用信息稀疏,从少样本重建中进行新视图渲染是具有挑战性的。在只有有限观测数据的场景中,原始的3DGS面临两个挑战:(1)从少样本图像中得到的稀疏运动恢复结构(SfM)点无法为高斯初始化表示全局几何结构。(2)利用少量图像进行优化可能会导致过拟合。
为了解决这些挑战,少样本方法[187]、[188]、[189]、[190]、[191]、[192]、[193]、[194]、[195]在SfM初始化和高斯优化中加入了额外的约束和先验信息。FSGS[187]根据现有高斯模型的接近程度在其附近插入新的高斯模型,以处理稀疏的初始点集,并生成未见过的视点用于训练以解决过拟合问题。DepthRegGS[188]采用深度引导的优化来减轻过拟合。CoherentGS[189]提出基于深度的初始化以获得密集的SfM点。MVSplat[190]提取多视图图像特征以构建每个视图的代价体,并预测每个视图的深度图用于少样本重建。SparseGS[191]将深度先验与生成性和显式约束相结合,以增强从未见过的视点的一致性。LoopSparseGS[192]将迭代渲染的图像与训练图像纳入SfM中,以使初始化的点云更加密集。此外,这项工作利用基于窗口的密集单目深度信息为高斯优化提供精确的几何监督。
5 数据集与性能评估
在本节中,我们详细总结了机器人领域常用的数据集。此外,我们提供了机器人关键模块的性能比较和评估,包括建图与定位、感知、操作和导航。这些模块是智能机器人系统功能的基础和关键。通过比较这些模块的性能,我们旨在提供基于3DGS表示的机器人研究现状的概述。在感知方面,我们仅报告场景分割,因为在本文完成时,尚无其他基于3DGS的感知方法可用。
5.1 SLAM评估
数据集。现有的基于3DGS的视觉SLAM和语义SLAM方法使用室内场景数据集进行评估,包括Replica [196]、ScanNet [197] 和 TUM RGB-D [198]。由于TUM RGB-D数据集 [198] 缺乏语义标注,通常不用于基准测试语义SLAM方法。对于多传感器融合SLAM方法,评估基于所使用的特定传感器在不同的室外场景数据集上进行,而不是统一的数据集。以下是SLAM数据集的详细描述:
• Replica [196] 是一个RGB-D数据集,包含18个室内场景重建,涵盖房间和建筑尺度。每个场景包括密集网格、高动态范围(HDR)纹理、每个基元的语义类别和实例信息。
• ScanNet数据集 [197] 包含1513个场景中的250万帧RGB-D图像和IMU数据,每个场景均标注了3D相机姿态、表面重建、纹理网格和语义分割。
• TUM RGB-D [198] 是一个RGB-D数据集,包含在办公室环境和工业大厅中记录的39个序列。RGB-D数据由Kinect捕获,地面真实姿态估计由运动捕捉系统获得。
指标。重建和跟踪指标用于评估SLAM的准确性。具体而言,深度L1(cm)指标用于重建评估,它是真实深度与重建深度之间的平均绝对误差。ATE RMSE(cm)[198] 是跟踪指标,用于量化估计轨迹与真实轨迹之间的误差。对于SLAM系统,实时性能至关重要,FPS指标用于评估SLAM过程的时间消耗。此外,mIoU(%)用于语义SLAM中的语义分割评估,它衡量预测区域与真实区域在不同类别之间的平均重叠百分比。此外,由于大多数基于3DGS的SLAM方法报告了SLAM建图结果的渲染性能,我们还将渲染指标纳入SLAM评估中。峰值信噪比(PSNR[dB])、结构相似性(SSIM)[199] 和学习感知图像块相似性(LPIPS)[200] 是渲染指标。
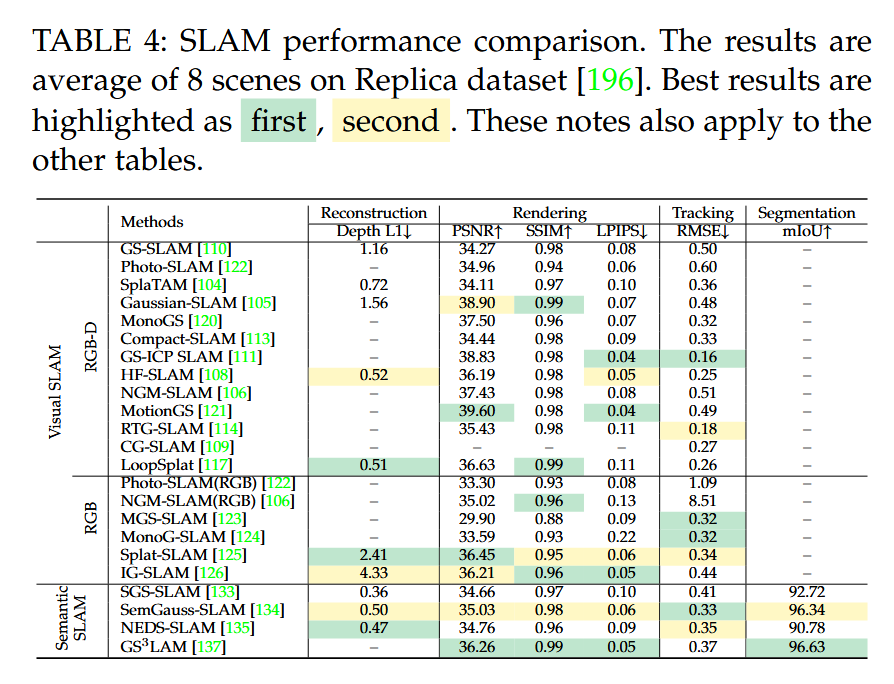
表4:SLAM性能比较。结果为Replica数据集 [196] 上8个场景的平均值。最佳结果以第一、第二标出。这些说明也适用于其他表格。
结果。由于视觉SLAM和语义SLAM方法主要在Replica数据集 [196] 上进行测试,我们在表4中展示了Replica数据集上关于SLAM指标的性能比较。此外,3DGS SLAM工作中报告的时间消耗结果是在不同GPU上进行的实验中获得的。由于GPU的计算能力差异显著,直接基于这些结果比较SLAM方法的实时性能是不公平的。因此,FPS指标未报告。
5.2 场景重建评估
数据集。室内重建通常使用与SLAM相似的数据集。对于室外场景重建,常用的数据集包括KITTI [201]、Waymo [202]、nuScenes [203] 和 Argoverse [204] 数据集。以下是室外重建数据集的详细描述:
• KITTI数据集 [201] 包含来自4个摄像头和1个LiDAR的数据,由22个立体序列组成,总长度为39.2公里。该数据集还包括20万个3D物体标注和389对光流图像对。
• Waymo数据集 [202] 包含来自5个摄像头和5个LiDAR传感器的数据,由1150个场景组成,涵盖城市和郊区地理范围。该数据集标注了2D(摄像头图像)和3D(LiDAR)边界框。
• nuScenes数据集 [203] 包含来自6个摄像头、5个雷达、1个LiDAR传感器和IMU的数据,由1000个场景组成,每个场景均完全标注了23个类别的3D边界框和8个属性。
• Argoverse数据集 [204] 包含LiDAR测量序列、来自7个摄像头的360°图像和前向立体图像。该数据集还包括290公里的车道地图和30万个有趣的车辆轨迹标注。
指标。渲染指标PSNR、SSIM和LPIPS用于评估。
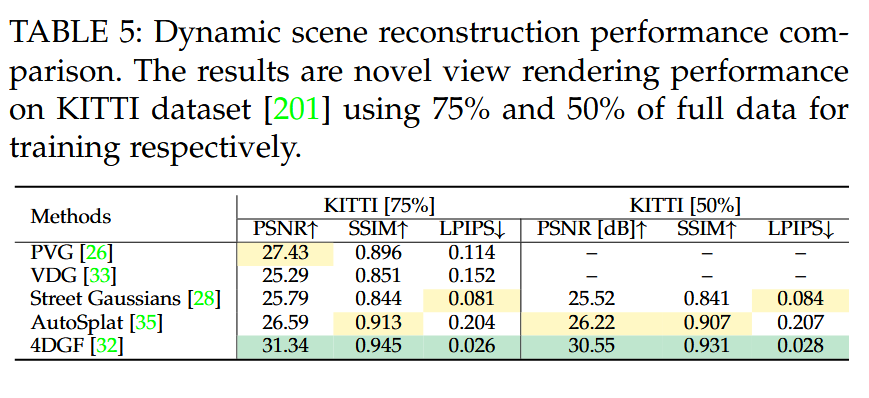
表5:动态场景重建性能比较。结果为使用KITTI数据集 [201] 75%和50%完整数据训练后的新视图渲染性能。
结果。在静态重建方面,各种方法使用这些数据集中的不同场景进行评估,而不是使用特定场景。对于动态场景重建,大多数方法在KITTI数据集 [201] 上使用一致的训练和测试分割进行评估。我们在表5中展示了KITTI数据集 [201] 上关于渲染指标的性能比较。一些未报告KITTI结果的动态场景重建方法未在表中显示。
5.3 定位评估
数据集。定位性能的评估通常使用Tanks&Temples [205]、7 Scenes [206] 数据集以及类似于室外场景重建中使用的自动驾驶数据集。以下是定位数据集的详细描述:
• Tanks&Temples数据集 [205] 包含高分辨率视频序列和室内外场景的真实姿态。
• 7 Scenes [206] 是一个带有真实姿态和密集3D模型的RGB-D数据集。每个场景的序列由不同用户记录,并分为不同的训练和测试集以进行定位评估。
指标。姿态指标绝对轨迹误差(ATE)和相对姿态误差(RPE)用于定位评估。ATE量化估计相机位置与真实位置之间的差异。RPE测量图像对之间的相对姿态误差。在基于3DGS的定位中,渲染指标PSNR、SSIM和LPIPS也用于评估基于估计姿态渲染的图像的准确性。
结果。现有的基于3DGS的定位方法使用各种数据集和序列。同时,这些方法未开源,因此无法在相同条件下比较现有定位方法的性能。总体而言,现有的基于3DGS的定位方法可以实现5厘米的位置精度和2°的角度精度。
5.4 分割评估
数据集:带有真实语义标注的数据集用于分割评估,包括LERFMask [58]、SPIn - NeRF [207],以及也用于同时定位与地图构建(SLAM)评估的室内数据集Replica [196] 和ScanNet [197]。具体而言,LERF - Mask [58] 用于评估文本查询语义分割,这是机器人操作和导航中的一项关键任务,要求机器人根据文本提示识别环境中的特定对象。以下是对分割数据集的详细描述:
-
LERF - Mask数据集 [58] 包含来自LERF - Localization数据集 [208] 的三个场景的语义标注。该数据集总共包含23条提示。
-
SPIn - NeRF数据集 [207] 包含10个带有标注对象掩码的真实世界前向场景。每个场景包括60张带有对象的训练图像和40张不带有对象的测试图像。
评估指标:尽管现有的基于3DGS的语义分割方法能够实现三维分割,但其性能仍通过测量渲染的语义与二维真实标签之间的差异来评估。平均交并比(mIoU(%))、平均边界交并比(mBIoU(%))和像素准确率(Acc.(%))用于语义评估。具体来说,mIoU衡量真实掩码和渲染掩码的重叠程度。mBIoU量化预测掩码与真实掩码之间的轮廓对齐情况。
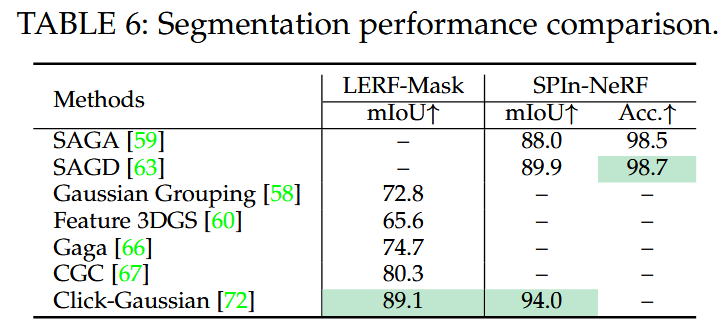
表6:分割性能比较。
结果:在LERF - Mask [58] 和SPIn - NeRF [207] 数据集上的性能比较见表6。
5.5 操作评估
数据集:操作方法的性能在模拟数据集和真实世界场景中都进行了评估。模拟数据集包括RLBench [209] 和Robomimic [210]。此外,还进行了真实世界的机械臂试验,以测量实际场景中的抓取精度。下面是对模拟数据集的详细描述:
-
RLBench数据集 [209] 是一个大规模的学习环境,具有100个独特的、手工设计的任务。这些任务范围从简单的目标抓取和开门,到较长的多阶段任务,例如打开烤箱并将托盘放入其中。
-
Robomimic数据集 [210] 由从三个不同来源收集的数据组成,包括机器生成(MG)、熟练人类(PH)和多人(MH)。MG包含从在强化学习(RL)方法 [211] 训练期间定期保存的智能体检查点得到的300条展开轨迹。PH由从单个熟练人类操作员处收集的200次演示组成。MH由从六名不同熟练程度的人类操作员处收集的300次演示组成。
评估指标:成功率(%)指标用于评估操作性能,代表机械臂在多次尝试中成功执行抓取或放置任务的百分比。
结果:在现有的基于3DGS的操作方法中,使用夹爪来执行操作。由于真实世界测试场景的差异以及所使用机械臂的不同,在相同条件下进行比较是不可行的。一般来说,对于单阶段任务,成功率最高可达80%,而对于多阶段任务,成功率低于50%。
5.6 路径规划评估
数据集:基于3DGS的路径规划评估使用模拟数据集Matterport3D [212]、Habitat-Matterport 3D(HM3D)[213] 或通过Unity引擎构建的自定义模拟环境。下面是对路径规划数据集的详细描述:
-
Matterport3D [212] 是一个大规模的RGB-D数据集,包含来自90个建筑规模场景的10,800个全景视图,带有表面重建、相机位姿、二维和三维语义分割标注。这个数据集通常使用Habitat模拟器 [214] 构建,用于评估路径规划。
-
HM3D [213] 是为目标物体导航任务设计的,由216个三维空间中的142,646个物体实例标注以及这些空间内的3,100个房间组成。
评估指标:规划准确性指标成功率(%)和路径长度标准化加权成功率(SPL)[215],以及规划安全性指标 Wasserstein距离(W2(P, Pˆ))[216],用于评估路径规划性能。具体来说,成功率是智能体在距目标物体预定义欧几里得距离内成功调用“停止”动作的试验百分比。SPL是由归一化的逆路径长度加权的成功率,它同时考虑了到达目标的成功率和到达目标的效率(路径长度)。W2(P, Pˆ) 量化了机器人估计的风险分布Pˆ 与真实风险分布P 之间的差异,这表明了机器人对环境风险评估的准确性,代表了机器人的安全性。
结果:现有的基于3DGS的路径规划方法是为各种任务设计的,例如实例图像目标导航(IIN)和安全导航。因此,这些基于3DGS的方法只能在相同条件下与相应的传统导航方法进行比较。通常,对于IIN任务,现有方法的路径规划成功率达到72%。在安全导航方面,现有研究在W2(P, Pˆ) 指标上平均可以达到0.68。
6 未来研究方向
尽管3DGS已广泛应用于机器人任务,但在这些任务中仍存在许多未解决的挑战。在本节中,我们提出了一些有价值的研究方向,为未来研究提供参考。
6.1 鲁棒跟踪
现有的基于3DGS的SLAM方法虽然在密集建图中表现出高精度,但通常难以实现准确且鲁棒的跟踪,尤其是在复杂的现实场景中。当前基于3DGS的SLAM系统的这一局限性源于其依赖于直接使用图像的RGB信息进行姿态优化。这种依赖严重依赖于图像的质量和纹理信息。然而,在现实世界的机器人应用中,图像质量容易受到相机运动模糊的影响,从而降低基于3DGS的SLAM的性能。此外,某些场景(如天空或墙壁)的纹理信息有限,导致姿态估计的约束不足。以下是提高跟踪鲁棒性的相应方向。
相机运动模糊。相机运动模糊主要由机器人的快速运动和相机的慢快门速度引起,导致图像模糊。尽管去模糊方法已被研究(第4.1.1节)并用于SLAM [116],但这些方法无法直接将捕获的模糊图像转换为清晰图像。相反,它们通过平均相机曝光时间内捕获的虚拟清晰图像来合成模糊图像。这些合成的模糊图像随后用于与观察到的模糊图像构建损失以进行高斯优化,确保构建的场景去模糊。然而,这些方法无法解决由运动模糊引起的观察图像质量下降问题,这会对依赖于高质量图像进行姿态优化的跟踪性能产生不利影响。一个合适的研究方向是利用3DGS表示的优势,如几何信息和空间分布,来执行跟踪。这种方法可以减少对图像质量的依赖。
纹理信息有限。在现实场景中,存在一些极端情况,环境纹理信息有限,导致仅依赖图像质量的姿态优化约束不足。尽管一些基于3DGS的SLAM方法 [128][129] 已利用多传感器融合的传统SLAM作为里程计进行跟踪,但这些方法在传统SLAM无法处理复杂极端情况时会失效。一个潜在的研究方向是将多传感器(如IMU、轮式编码器和LiDAR)的原始传感器数据与3D高斯表示结合,为姿态优化提供足够的约束。这种方法不仅利用了3DGS提供的空间结构信息和密集场景表示,还利用了多传感器信息带来的各种约束。
6.2 终身建图与定位
当前的3DGS方法主要关注短期重建和定位。然而,在大多数现实场景中,环境会随着时间的推移不断变化。未考虑这些变化的预建地图可能很快变得过时且不可靠。因此,保持环境的最新模型对于促进机器人的长期操作或导航至关重要。尽管一些传统方法 [217][218] 已经实现了长期建图,但这些方法专注于构建和更新稀疏地图,这对于下游机器人任务来说是不够的。因此,一个有意义的研究方向是基于3DGS的终身密集建图和定位。由于3DGS是一种显式且密集的表示,高斯地图的动态更新和优化可以通过对高斯基元的显式编辑来实现。此外,我们相信,由长期动态变化引起的高斯地图不一致性可以通过利用高斯基元之间的内部约束进行优化。因此,通过利用高斯基元的显式表示和内在约束,可以实现终身建图和定位。
6.3 大规模重定位
在机器人应用中,机器人进入预先建立的地图时需要重新定位其当前位置。然而,现有的基于3DGS的重定位方法 [144][145] 要么需要粗略的初始姿态,要么只能在小规模室内场景中实现重定位。这些方法在没有初始姿态的情况下难以在大规模室外场景中进行重定位。遗憾的是,在实际机器人应用中,获得粗略的初始姿态用于重定位是具有挑战性的。因此,一个有意义的研究方向是无先验姿态的大规模重定位。我们相信,基于3DGS表示构建子图索引库或描述符有助于粗略姿态回归。此外,通过利用3DGS表示中的几何和外观特征进行配准过程,可以优化粗略姿态。
6.4 仿真到现实的操作
收集现实世界的操作数据集具有挑战性,导致训练有效抓取的现实场景数据稀缺。因此,抓取方法通常需要在仿真环境中进行初始训练,然后再转移到现实世界环境中。尽管基于3DGS的仿真到现实方法 [219] 已被探索,但其在泛化方面存在局限性。具体而言,这种方法严重依赖于场景特定的训练,这阻碍了其在相似任务场景之间泛化和迁移学习知识的能力。因此,该方法仍然需要大量的现实世界数据集进行训练。此外,仿真和现实环境之间材料和物理属性的差异可能导致操作任务的训练数据分布显著不同。这些差异可能会产生完全不同的操作策略。然而,现有方法 [220] 仅能对现实场景的物理属性进行建模。因此,一个有意义的研究方向是直接将不确定性和环境特征纳入3DGS表示中,以增强泛化和属性建模能力。
7 结论
作为一种用于密集场景表示的强大辐射场,三维高斯场景表示(3DGS)在机器人领域为场景理解和交互提供了新的选择。具体而言,3DGS为机器人领域的许多应用提供了可靠的选择,例如重建、场景分割、场景编辑、同时定位与地图构建(SLAM)、操作以及导航。此外,3DGS在大规模环境、运动模糊条件、少样本场景等方面提升其性能的能力大多尚未被开发利用。探索这些领域可能会显著加深3DGS与机器人技术之间的融合。
此外,我们对当前3DGS在机器人领域的应用进行了全面的性能评估,帮助读者选择他们偏好的方法。最后,我们详细讨论了3DGS在机器人领域所面临的挑战以及未来的发展方向。
因此,由于我们的综述对该领域的杰出工作进行了全面总结,并强调了其潜力,我们希望这篇综述能够鼓励更多的研究人员探索新的可能性,并在真实的机器人平台上成功实现这些可能性。
REFERENCES
[1] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” in ECCV, 2020.
[2] B. Kerbl, G. Kopanas, T. Leimk ̈uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering,” ACM Trans. Graph., vol. 42, no. 4, pp. 1–14, 2023.
[3] L. A. Westover, Splatting: a parallel, feed-forward volume rendering algorithm. The University of North Carolina at Chapel Hill, 1991.
[4] G. Chen and W. Wang, “A survey on 3d gaussian splatting,” arXiv preprint arXiv:2401.03890, 2024.
[5] B. Fei, J. Xu, R. Zhang, Q. Zhou, W. Yang, and Y. He, “3d gaussian as a new vision era: A survey,” arXiv preprint arXiv:2402.07181, 2024.
[6] A. Dalal, D. Hagen, K. G. Robbersmyr, and K. M. Knausg ̊ard, “Gaussian splatting: 3d reconstruction and novel view synthesis, a review,” IEEE Access, vol. 12, pp. 96 797–96 820, 2024.
[7] T. Wu, Y.-J. Yuan, L.-X. Zhang, J. Yang, Y.-P. Cao, L.-Q. Yan, and L. Gao, “Recent advances in 3d gaussian splatting,” Comp. Visual Media, pp. 1–30, 2024.
[8] M. T. Bagdasarian, P. Knoll, F. Barthel, A. Hilsmann, P. Eisert, and W. Morgenstern, “3dgs. zip: A survey on 3d gaussian splatting compression methods,” arXiv preprint arXiv:2407.09510, 2024.
[9] Y. Bao, T. Ding, J. Huo, Y. Liu, Y. Li, W. Li, Y. Gao, and J. Luo, “3d gaussian splatting: Survey, technologies, challenges, and opportunities,” arXiv preprint arXiv:2407.17418, 2024.
[10] B. Cabral, N. Max, and R. Springmeyer, “Bidirectional reflection functions from surface bump maps,” in Proc. of the 14th annual conf. on Computer graphics and interactive techniques, 1987, pp. 273281.
[11] J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” in CVPR, 2016, pp. 4104–4113.
[12] J. Bai, L. Huang, J. Guo, W. Gong, Y. Li, and Y. Guo, “360-gs: Layout-guided panoramic gaussian splatting for indoor roaming,” arXiv preprint arXiv:2402.00763, 2024.
[13] H. Xiang, X. Li, X. Lai, W. Zhang, Z. Liao, K. Cheng, and X. Liu, “Gaussianroom: Improving 3d gaussian splatting with sdf guidance and monocular cues for indoor scene reconstruction,” arXiv preprint arXiv:2405.19671, 2024.
[14] J. Kim and J. Lim, “Integrating meshes and 3d gaussians for indoor scene reconstruction with sam mask guidance,” arXiv preprint arXiv:2407.16173, 2024.
[15] K. Cheng, X. Long, K. Yang, Y. Yao, W. Yin, Y. Ma, W. Wang, and X. Chen, “Gaussianpro: 3d gaussian splatting with progressive propagation,” in Forty-first Int. conf. on Machine Learning, 2024.
[16] H. Dahmani, M. Bennehar, N. Piasco, L. Roldao, and D. Tsishkou, “Swag: Splatting in the wild images with appearanceconditioned gaussians,” arXiv preprint arXiv:2403.10427, 2024.
[17] C. Ye, Y. Nie, J. Chang, Y. Chen, Y. Zhi, and X. Han, “Gaustudio: A modular framework for 3d gaussian splatting and beyond,” arXiv preprint arXiv:2403.19632, 2024.
[18] K. Wu, K. Zhang, Z. Zhang, S. Yuan, M. Tie, J. Wei, Z. Xu, J. Zhao, Z. Gan, and W. Ding, “Hgs-mapping: Online dense mapping using hybrid gaussian representation in urban scenes,” RA-L, vol. 9, no. 11, pp. 9573–9580, 2024.
[19] Z. Li, Y. Zhang, C. Wu, J. Zhu, and L. Zhang, “Ho-gaussian: Hybrid optimization of 3d gaussian splatting for urban scenes,” arXiv preprint arXiv:2403.20032, 2024.
[20] C. Zhao, S. Sun, R. Wang, Y. Guo, J.-J. Wan, Z. Huang, X. Huang, Y. V. Chen, and L. Ren, “Tclc-gs: Tightly coupled lidar-camera gaussian splatting for surrounding autonomous driving scenes,” arXiv preprint arXiv:2404.02410, 2024.
[21] D. Chen, H. Li, W. Ye, Y. Wang, W. Xie, S. Zhai, N. Wang, H. Liu, H. Bao, and G. Zhang, “Pgsr: Planar-based gaussian splatting for efficient and high-fidelity surface reconstruction,” arXiv preprint arXiv:2406.06521, 2024.
[22] J. Xu, Y. Mei, and V. M. Patel, “Wild-gs: Real-time novel view synthesis from unconstrained photo collections,” arXiv preprint arXiv:2406.10373, 2024.
[23] J. Kulhanek, S. Peng, Z. Kukelova, M. Pollefeys, and T. Sattler, “Wildgaussians: 3d gaussian splatting in the wild,” NeurIPS, 2024.
[24] X. Shi, L. Chen, P. Wei, X. Wu, T. Jiang, Y. Luo, and L. Xie, “Dhgs: Decoupled hybrid gaussian splatting for driving scene,” arXiv preprint arXiv:2407.16600, 2024.
[25] B. Huang, Z. Yu, A. Chen, A. Geiger, and S. Gao, “2d gaussian splatting for geometrically accurate radiance fields,” in ACM SIGGRAPH 2024 Conf., 2024, pp. 1–11.
[26] Y. Chen, C. Gu, J. Jiang, X. Zhu, and L. Zhang, “Periodic vibration gaussian: Dynamic urban scene reconstruction and real-time rendering,” arXiv preprint arXiv:2311.18561, 2023.
[27] X. Zhou, Z. Lin, X. Shan, Y. Wang, D. Sun, and M.-H. Yang, “Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes,” in CVPR, 2024, pp. 21 63421 643.
[28] Y. Yan, H. Lin, C. Zhou, W. Wang, H. Sun, K. Zhan, X. Lang, X. Zhou, and S. Peng, “Street gaussians for modeling dynamic urban scenes,” arXiv preprint arXiv:2401.01339, 2024.
[29] H. Zhou, J. Shao, L. Xu, D. Bai, W. Qiu, B. Liu, Y. Wang, A. Geiger, and Y. Liao, “Hugs: Holistic urban 3d scene understanding via gaussian splatting,” in CVPR, 2024, pp. 21 336–21 345.
[30] J. Lei, Y. Weng, A. Harley, L. Guibas, and K. Daniilidis, “Mosca: Dynamic gaussian fusion from casual videos via 4d motion scaffolds,” arXiv preprint arXiv:2405.17421, 2024.
[31] N. Huang, X. Wei, W. Zheng, P. An, M. Lu, W. Zhan, M. Tomizuka, K. Keutzer, and S. Zhang, “S3 gaussian: Selfsupervised street gaussians for autonomous driving,” arXiv preprint arXiv:2405.20323, 2024.
[32] T. Fischer, J. Kulhanek, S. R. Bul `o, L. Porzi, M. Pollefeys, and P. Kontschieder, “Dynamic 3d gaussian fields for urban areas,” arXiv preprint arXiv:2406.03175, 2024.
[33] H. Li, J. Li, D. Zhang, C. Wu, J. Shi, C. Zhao, H. Feng, E. Ding, J. Wang, and J. Han, “Vdg: Vision-only dynamic gaussian for driving simulation,” arXiv preprint arXiv:2406.18198, 2024.
[34] D. Zhang, G. Li, J. Li, M. Bressieux, O. Hilliges, M. Pollefeys, L. Van Gool, and X. Wang, “Egogaussian: Dynamic scene understanding from egocentric video with 3d gaussian splatting,” arXiv preprint arXiv:2406.19811, 2024.
[35] M. Khan, H. Fazlali, D. Sharma, T. Cao, D. Bai, Y. Ren, and B. Liu, “Autosplat: Constrained gaussian splatting for autonomous driving scene reconstruction,” arXiv preprint arXiv:2407.02598, 2024.
[36] J. Luiten, G. Kopanas, B. Leibe, and D. Ramanan, “Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis,” arXiv preprint arXiv:2308.09713, 2023.
[37] Z. Yang, X. Gao, W. Zhou, S. Jiao, Y. Zhang, and X. Jin, “Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction,” in CVPR, 2024, pp. 20 331–20 341.
[38] G. Wu, T. Yi, J. Fang, L. Xie, X. Zhang, W. Wei, W. Liu, Q. Tian, and X. Wang, “4d gaussian splatting for real-time dynamic scene rendering,” in CVPR, 2024, pp. 20 310–20 320.
[39] Z. Yang, H. Yang, Z. Pan, X. Zhu, and L. Zhang, “Real-time photorealistic dynamic scene representation and rendering with 4d gaussian splatting,” arXiv preprint arXiv:2310.10642, 2023.
[40] K. Katsumata, D. M. Vo, and H. Nakayama, “An efficient 3d gaussian representation for monocular/multi-view dynamic scenes,” arXiv preprint arXiv:2311.12897, 2023.
[41] Y.-H. Huang, Y.-T. Sun, Z. Yang, X. Lyu, Y.-P. Cao, and X. Qi, “Sc-gs: Sparse-controlled gaussian splatting for editable dynamic scenes,” in CVPR, 2024, pp. 4220–4230.
[42] Y. Lin, Z. Dai, S. Zhu, and Y. Yao, “Gaussian-flow: 4d reconstruction with dynamic 3d gaussian particle,” in CVPR, 2024, pp. 21 136–21 145.
[43] Y. Liang, N. Khan, Z. Li, T. Nguyen-Phuoc, D. Lanman, J. Tompkin, and L. Xiao, “Gaufre: Gaussian deformation fields for real-time dynamic novel view synthesis,” arXiv preprint arXiv:2312.11458, 2023.
[44] R. Shaw, J. Song, A. Moreau, M. Nazarczuk, S. Catley-Chandar, H. Dhamo, and E. Perez-Pellitero, “Swags: Sampling windows adaptively for dynamic 3d gaussian splatting,” arXiv preprint arXiv:2312.13308, 2023.
[45] Z. Li, Z. Chen, Z. Li, and Y. Xu, “Spacetime gaussian feature splatting for real-time dynamic view synthesis,” in CVPR, 2024, pp. 8508–8520.
[46] Y. Duan, F. Wei, Q. Dai, Y. He, W. Chen, and B. Chen, “4d gaussian splatting: Towards efficient novel view synthesis for dynamic scenes,” arXiv preprint arXiv:2402.03307, 2024.
[47] J. Sun, H. Jiao, G. Li, Z. Zhang, L. Zhao, and W. Xing, “3dgstream: On-the-fly training of 3d gaussians for efficient streaming of photo-realistic free-viewpoint videos,” in CVPR, 2024, pp. 20 67520 685.
[48] J. Bae, S. Kim, Y. Yun, H. Lee, G. Bang, and Y. Uh, “Per-gaussian embedding-based deformation for deformable 3d gaussian splatting,” arXiv preprint arXiv:2404.03613, 2024.
[49] Z. Lu, X. Guo, L. Hui, T. Chen, M. Yang, X. Tang, F. Zhu, and Y. Dai, “3d geometry-aware deformable gaussian splatting for dynamic view synthesis,” in CVPR, 2024, pp. 8900–8910.
[50] B. Zhang, B. Zeng, and Z. Peng, “A refined 3d gaussian representation for high-quality dynamic scene reconstruction,” arXiv preprint arXiv:2405.17891, 2024.
[51] D. Wan, R. Lu, and G. Zeng, “Superpoint gaussian splatting for real-time high-fidelity dynamic scene reconstruction,” arXiv preprint arXiv:2406.03697, 2024.
[52] M.-L. Shih, J.-B. Huang, C. Kim, R. Shah, J. Kopf, and C. Gao, “Modeling ambient scene dynamics for free-view synthesis,” arXiv preprint arXiv:2406.09395, 2024.
[53] C. Stearns, A. Harley, M. Uy, F. Dubost, F. Tombari, G. Wetzstein, and L. Guibas, “Dynamic gaussian marbles for novel view synthesis of casual monocular videos,” arXiv preprint arXiv:2406.18717, 2024.
[54] L. Xie, J. Julin, K. Niinuma, and L. A. Jeni, “Gaussian splatting lk,” arXiv preprint arXiv:2407.11309, 2024.
[55] B. He, Y. Chen, G. Lu, L. Song, and W. Zhang, “S4d: Streaming 4d real-world reconstruction with gaussians and 3d control points,” arXiv preprint arXiv:2408.13036, 2024.
[56] A. Cao and J. Johnson, “Hexplane: A fast representation for dynamic scenes,” in CVPR, 2023, pp. 130–141.
[57] M. T. Bosch, “N-dimensional rigid body dynamics,” ACM Trans. Graph., vol. 39, no. 4, pp. 55–1, 2020.
[58] M. Ye, M. Danelljan, F. Yu, and L. Ke, “Gaussian grouping: Segment and edit anything in 3d scenes,” arXiv preprint arXiv:2312.00732, 2023.
[59] J. Cen, J. Fang, C. Yang, L. Xie, X. Zhang, W. Shen, and Q. Tian, “Segment any 3d gaussians,” arXiv preprint arXiv:2312.00860, 2023.
[60] S. Zhou, H. Chang, S. Jiang, Z. Fan, Z. Zhu, D. Xu, P. Chari, S. You, Z. Wang, and A. Kadambi, “Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields,” in CVPR, 2024, pp. 21 676–21 685.
[61] K. Lan, H. Li, H. Shi, W. Wu, Y. Liao, L. Wang, and P. Zhou, “2d-guided 3d gaussian segmentation,” arXiv preprint arXiv:2312.16047, 2023.
[62] B. Dou, T. Zhang, Y. Ma, Z. Wang, and Z. Yuan, “Cosseggaussians: Compact and swift scene segmenting 3d gaussians,” arXiv preprint arXiv:2401.05925, 2024.
[63] X. Hu, Y. Wang, L. Fan, J. Fan, J. Peng, Z. Lei, Q. Li, and Z. Zhang, “Semantic anything in 3d gaussians,” arXiv preprint arXiv:2401.17857, 2024.
[64] J. Guo, X. Ma, Y. Fan, H. Liu, and Q. Li, “Semantic gaussians: Open-vocabulary scene understanding with 3d gaussian splatting,” arXiv preprint arXiv:2403.15624, 2024.
[65] Q. Gu, Z. Lv, D. Frost, S. Green, J. Straub, and C. Sweeney, “Egolifter: Open-world 3d segmentation for egocentric perception,” arXiv preprint arXiv:2403.18118, 2024.
[66] W. Lyu, X. Li, A. Kundu, Y.-H. Tsai, and M.-H. Yang, “Gaga: Group any gaussians via 3d-aware memory bank,” arXiv preprint arXiv:2404.07977, 2024.
[67] M. C. Silva, M. Dahaghin, M. Toso, and A. Del Bue, “Contrastive gaussian clustering: Weakly supervised 3d scene segmentation,” arXiv preprint arXiv:2404.12784, 2024.
[68] G. Liao, J. Li, Z. Bao, X. Ye, J. Wang, Q. Li, and K. Liu, “Clip-gs: Clip-informed gaussian splatting for real-time and view-consistent 3d semantic understanding,” arXiv preprint arXiv:2404.14249, 2024.
[69] X. Zuo, P. Samangouei, Y. Zhou, Y. Di, and M. Li, “Fmgs: Foundation model embedded 3d gaussian splatting for holistic 3d scene understanding,” arXiv preprint arXiv:2401.01970, 2024.
[70] M.-B. Jurca, R. Royen, I. Giosan, and A. Munteanu, “Rt-gs2: Realtime generalizable semantic segmentation for 3d gaussian representations of radiance fields,” arXiv preprint arXiv:2405.18033, 2024.
[71] Y. Wu, J. Meng, H. Li, C. Wu, Y. Shi, X. Cheng, C. Zhao, H. Feng, E. Ding, J. Wang et al., “Opengaussian: Towards point-level 3d gaussian-based open vocabulary understanding,” arXiv preprint arXiv:2406.02058, 2024.
[72] S. Choi, H. Song, J. Kim, T. Kim, and H. Do, “Click-gaussian: Interactive segmentation to any 3d gaussians,” arXiv preprint arXiv:2407.11793, 2024.
[73] S. Ji, G. Wu, J. Fang, J. Cen, T. Yi, W. Liu, Q. Tian, and X. Wang, “Segment any 4d gaussians,” arXiv preprint arXiv:2407.04504, 2024.
[74] F. Chabot, N. Granger, and G. Lapouge, “Gaussianbev: 3d gaussian representation meets perception models for bev segmentation,” arXiv preprint arXiv:2407.14108, 2024.
[75] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” in ICCV, 2023, pp. 4015–4026.
[76] H. K. Cheng, S. W. Oh, B. Price, A. Schwing, and J.-Y. Lee, “Tracking anything with decoupled video segmentation,” in ICCV, 2023, pp. 1316–1326.
[77] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in Int. conf. on machine learning. PMLR, 2021, pp. 8748–8763.
[78] M. Caron, H. Touvron, I. Misra, H. J ́egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” in ICCV, 2021, pp. 9650–9660.
[79] Y. Wang, Q. Wu, G. Zhang, and D. Xu, “Gscream: Learning 3d geometry and feature consistent gaussian splatting for object removal,” arXiv preprint arXiv:2404.13679, 2024.
[80] Y. Mei, J. Xu, and V. M. Patel, “Reference-based controllable scene stylization with gaussian splatting,” arXiv preprint arXiv:2407.07220, 2024.
[81] J. Huang and H. Yu, “Point’n move: Interactive scene object manipulation on gaussian splatting radiance fields,” arXiv preprint arXiv:2311.16737, 2023.
[82] G. Luo, T.-X. Xu, Y.-T. Liu, X.-X. Fan, F.-L. Zhang, and S.-H. Zhang, “3d gaussian editing with a single image,” ACM Multimedia, 2024.
[83] R.-Z. Qiu, G. Yang, W. Zeng, and X. Wang, “Feature splatting: Language-driven physics-based scene synthesis and editing,” arXiv preprint arXiv:2404.01223, 2024.
[84] T.-X. Xu, W. Hu, Y.-K. Lai, Y. Shan, and S.-H. Zhang, “Texture-gs: Disentangling the geometry and texture for 3d gaussian splatting editing,” arXiv preprint arXiv:2403.10050, 2024.
[85] J. Zhuang, D. Kang, Y.-P. Cao, G. Li, L. Lin, and Y. Shan, “Tipeditor: An accurate 3d editor following both text-prompts and image-prompts,” ACM Trans. Graph., vol. 43, no. 4, pp. 1–12, 2024.
[86] F. Palandra, A. Sanchietti, D. Baieri, and E. Rodol`a, “Gsedit: Efficient text-guided editing of 3d objects via gaussian splatting,” arXiv preprint arXiv:2403.05154, 2024.
[87] J. Wu, J.-W. Bian, X. Li, G. Wang, I. Reid, P. Torr, and V. A. Prisacariu, “Gaussctrl: multi-view consistent text-driven 3d gaussian splatting editing,” arXiv preprint arXiv:2403.08733, 2024.
[88] Y. Wang, X. Yi, Z. Wu, N. Zhao, L. Chen, and H. Zhang, “Viewconsistent 3d editing with gaussian splatting,” arXiv preprint arXiv:2403.11868, 2024.
[89] J. Wang, J. Fang, X. Zhang, L. Xie, and Q. Tian, “Gaussianeditor: Editing 3d gaussians delicately with text instructions,” in CVPR, 2024, pp. 20 902–20 911.
[90] Y. Chen, Z. Chen, C. Zhang, F. Wang, X. Yang, Y. Wang, Z. Cai, L. Yang, H. Liu, and G. Lin, “Gaussianeditor: Swift and controllable 3d editing with gaussian splatting,” in CVPR, 2024, pp. 21 476–21 485.
[91] M. Chen, I. Laina, and A. Vedaldi, “Dge: Direct gaussian 3d editing by consistent multi-view editing,” 2024.
[92] T. Xu, J. Chen, P. Chen, Y. Zhang, J. Yu, and W. Yang, “Tiger: Text-instructed 3d gaussian retrieval and coherent editing,” arXiv preprint arXiv:2405.14455, 2024.
[93] C. Luo, D. Di, Y. Ma, Z. Xue, C. Wei, X. Yang, and Y. Liu, “Trame: Trajectory-anchored multi-view editing for text-guided 3d gaussian splatting manipulation,” arXiv preprint arXiv:2407.02034, 2024.
[94] U. Khalid, H. Iqbal, A. Farooq, J. Hua, and C. Chen, “3dego: 3d editing on the go!” in ECCV, 2024.
[95] H. Xiao, Y. Chen, H. Huang, H. Xiong, J. Yang, P. Prasad, and Y. Zhao, “Localized gaussian splatting editing with contextual awareness,” arXiv preprint arXiv:2408.00083, 2024.
[96] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in CVPR, 2022, pp. 10 684–10 695.
[97] L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” in ICCV, 2023, pp. 3836–3847.
[98] K. Liu, F. Zhan, M. Xu, C. Theobalt, L. Shao, and S. Lu, “Stylegaussian: Instant 3d style transfer with gaussian splatting,” arXiv preprint arXiv:2403.07807, 2024.
[99] D. Zhang, Z. Chen, Y.-J. Yuan, F.-L. Zhang, Z. He, S. Shan, and L. Gao, “Stylizedgs: Controllable stylization for 3d gaussian splatting,” arXiv preprint arXiv:2404.05220, 2024.
[100] A. Saroha, M. Gladkova, C. Curreli, T. Yenamandra, and D. Cremers, “Gaussian splatting in style,” arXiv preprint arXiv:2403.08498, 2024.
[101] V. Jaganathan, H. H. Huang, M. Z. Irshad, V. Jampani, A. Raj, and Z. Kira, “Ice-g: Image conditional editing of 3d gaussian splats,” arXiv preprint arXiv:2406.08488, 2024.
[102] S. Jain, A. Kuthiala, P. S. Sethi, and P. Saxena, “Stylesplat: 3d object style transfer with gaussian splatting,” arXiv preprint arXiv:2407.09473, 2024.
[103] X.-Y. Yu, J.-X. Yu, L.-B. Zhou, Y. Wei, and L.-L. Ou, “Instantstylegaussian: Efficient art style transfer with 3d gaussian splatting,” SIGGRAPH Asia, 2024.
[104] N. Keetha, J. Karhade, K. M. Jatavallabhula, G. Yang, S. Scherer, D. Ramanan, and J. Luiten, “Splatam: Splat track & map 3d gaussians for dense rgb-d slam,” in CVPR, 2024, pp. 21 35721 366.
[105] V. Yugay, Y. Li, T. Gevers, and M. R. Oswald, “Gaussian-slam: Photo-realistic dense slam with gaussian splatting,” arXiv preprint arXiv:2312.10070, 2023.
[106] M. Li, J. Huang, L. Sun, A. X. Tian, T. Deng, and H. Wang, “Ngmslam: Gaussian splatting slam with radiance field submap,” arXiv preprint arXiv:2405.05702, 2024.
[107] S. Liu, H. Zhou, L. Li, Y. Liu, T. Deng, Y. Zhou, and M. Li, “Structure gaussian slam with manhattan world hypothesis,” arXiv preprint arXiv:2405.20031, 2024.
[108] S. Sun, M. Mielle, A. J. Lilienthal, and M. Magnusson, “Highfidelity slam using gaussian splatting with rendering-guided densification and regularized optimization,” in IROS, 2024.
[109] J. Hu, X. Chen, B. Feng, G. Li, L. Yang, H. Bao, G. Zhang, and Z. Cui, “Cg-slam: Efficient dense rgb-d slam in a consistent uncertainty-aware 3d gaussian field,” in ECCV, 2024.
[110] C. Yan, D. Qu, D. Xu, B. Zhao, Z. Wang, D. Wang, and X. Li, “Gsslam: Dense visual slam with 3d gaussian splatting,” in CVPR, 2024, pp. 19 595–19 604.
[111] S. Ha, J. Yeon, and H. Yu, “Rgbd gs-icp slam,” in ECCV, 2024.
[112] P. Jiang, H. Liu, X. Li, T. Wang, F. Zhang, and J. M. Buhmann, “Tambridge: Bridging frame-centered tracking and 3d gaussian splatting for enhanced slam,” arXiv preprint arXiv:2405.19614, 2024.
[113] T. Deng, Y. Chen, L. Zhang, J. Yang, S. Yuan, D. Wang, and W. Chen, “Compact 3d gaussian splatting for dense visual slam,” arXiv preprint arXiv:2403.11247, 2024.
[114] Z. Peng, T. Shao, Y. Liu, J. Zhou, Y. Yang, J. Wang, and K. Zhou, “Rtg-slam: Real-time 3d reconstruction at scale using gaussian splatting,” in SIGGRAPH, 2024.
[115] Z. Qu, Z. Zhang, C. Liu, and J. Yin, “Visual slam with 3d gaussian primitives and depth priors enabling novel view synthesis,” arXiv preprint arXiv:2408.05635, 2024.
[116] G. Bae, C. Choi, H. Heo, S. M. Kim, and Y. M. Kim, “I2-slam: Inverting imaging process for robust photorealistic dense slam,” in ECCV, 2024.
[117] L. Zhu, Y. Li, E. Sandstro ̈ m, K. Schindler, and I. Armeni, “Loopsplat: Loop closure by registering 3d gaussian splats,” arXiv preprint arXiv:2408.10154, 2024.
[118] J. Wei and S. Leutenegger, “Gsfusion: Online rgb-d mapping where gaussian splatting meets tsdf fusion,” arXiv preprint arXiv:2408.12677, 2024.
[119] A. Segal, D. Haehnel, and S. Thrun, “Generalized-icp.” in Robotics: science and systems, vol. 2, no. 4. Seattle, WA, 2009, p. 435.
[120] H. Matsuki, R. Murai, P. H. Kelly, and A. J. Davison, “Gaussian splatting slam,” in CVPR, 2024, pp. 18 039–18 048.
[121] X. Guo, P. Han, W. Zhang, and H. Chen, “Motiongs: Compact gaussian splatting slam by motion filter,” arXiv preprint arXiv:2405.11129, 2024.
[122] H. Huang, L. Li, H. Cheng, and S.-K. Yeung, “Photo-slam: Realtime simultaneous localization and photorealistic mapping for monocular stereo and rgb-d cameras,” in CVPR, 2024, pp. 21 58421 593.
[123] P. Zhu, Y. Zhuang, B. Chen, L. Li, C. Wu, and Z. Liu, “Mgs-slam: Monocular sparse tracking and gaussian mapping with depth smooth regularization,” arXiv preprint arXiv:2405.06241, 2024.
[124] T. Lan, Q. Lin, and H. Wang, “Monocular gaussian slam with language extended loop closure,” arXiv preprint arXiv:2405.13748, 2024.
[125] E. Sandstr ̈om, K. Tateno, M. Oechsle, M. Niemeyer, L. Van Gool, M. R. Oswald, and F. Tombari, “Splat-slam: Globally optimized rgb-only slam with 3d gaussians,” arXiv preprint arXiv:2405.16544, 2024.
[126] F. A. Sarikamis and A. A. Alatan, “Ig-slam: Instant gaussian slam,” arXiv preprint arXiv:2408.01126, 2024.
[127] Z. Teed, L. Lipson, and J. Deng, “Deep patch visual odometry,” NeurIPS, vol. 36, 2024.
[128] S. Hong, J. He, X. Zheng, C. Zheng, and S. Shen, “Liv-gaussmap: Lidar-inertial-visual fusion for real-time 3d radiance field map rendering,” RA-L, 2024.
[129] X. Lang, L. Li, H. Zhang, F. Xiong, M. Xu, Y. Liu, X. Zuo, and J. Lv, “Gaussian-lic: Photo-realistic lidar-inertial-camera slam with 3d gaussian splatting,” arXiv preprint arXiv:2404.06926, 2024.
[130] C. Wu, Y. Duan, X. Zhang, Y. Sheng, J. Ji, and Y. Zhang, “Mmgaussian: 3d gaussian-based multi-modal fusion for localization and reconstruction in unbounded scenes,” in IROS, 2024.
[131] I. Vizzo, T. Guadagnino, B. Mersch, L. Wiesmann, J. Behley, and C. Stachniss, “Kiss-icp: In defense of point-to-point icp–simple, accurate, and robust registration if done the right way,” RA-L, vol. 8, no. 2, pp. 1029–1036, 2023.
[132] L. C. Sun, N. P. Bhatt, J. C. Liu, Z. Fan, Z. Wang, T. E. Humphreys, and U. Topcu, “Mm3dgs slam: Multi-modal 3d gaussian splatting for slam using vision, depth, and inertial measurements,” in IROS, 2024.
[133] M. Li, S. Liu, and H. Zhou, “Sgs-slam: Semantic gaussian splatting for neural dense slam,” in ECCV, 2024.
[134] S. Zhu, R. Qin, G. Wang, J. Liu, and H. Wang, “Semgaussslam: Dense semantic gaussian splatting slam,” arXiv preprint arXiv:2403.07494, 2024.
[135] Y. Ji, Y. Liu, G. Xie, B. Ma, and Z. Xie, “Neds-slam: A novel neural explicit dense semantic slam framework using 3d gaussian splatting,” RA-L, vol. 9, no. 10, pp. 8778–8785, 2024.
[136] S. Zhu, G. Wang, H. Blum, J. Liu, L. Song, M. Pollefeys, and H. Wang, “Sni-slam: Semantic neural implicit slam,” in CVPR, 2024, pp. 21 167–21 177.
[137] L. Li, L. Zhang, Z. Wang, and Y. Shen, “Gs3lam: Gaussian semantic splatting slam,” in ACM Multimedia 2024.
[138] Y. Zheng, X. Chen, Y. Zheng, S. Gu, R. Yang, B. Jin, P. Li, C. Zhong, Z. Wang, L. Liu et al., “Gaussiangrasper: 3d language gaussian splatting for open-vocabulary robotic grasping,” arXiv preprint arXiv:2403.09637, 2024.
[139] O. Shorinwa, J. Tucker, A. Smith, A. Swann, T. Chen, R. Firoozi, M. Kennedy III, and M. Schwager, “Splat-mover: Multi-stage, open-vocabulary robotic manipulation via editable gaussian splatting,” arXiv preprint arXiv:2405.04378, 2024.
[140] G. Lu, S. Zhang, Z. Wang, C. Liu, J. Lu, and Y. Tang, “Manigaussian: Dynamic gaussian splatting for multi-task robotic manipulation,” arXiv preprint arXiv:2403.08321, 2024.
[141] Y. Li and D. Pathak, “Object-aware gaussian splatting for robotic manipulation,” in ICRA 2024 Workshop on 3D Visual Representations for Robot Manipulation.
[142] Y. Sun, X. Wang, Y. Zhang, J. Zhang, C. Jiang, Y. Guo, and F. Wang, “icomma: Inverting 3d gaussians splatting for camera pose estimation via comparing and matching,” arXiv preprint arXiv:2312.09031, 2023.
[143] K. Jiang, Y. Fu, M. Varma T, Y. Belhe, X. Wang, H. Su, and R. Ramamoorthi, “A construct-optimize approach to sparse view synthesis without camera pose,” in ACM SIGGRAPH 2024 Conference Papers, 2024, pp. 1–11.
[144] P. Jiang, G. Pandey, and S. Saripalli, “3dgs-reloc: 3d gaussian splatting for map representation and visual relocalization,” arXiv preprint arXiv:2403.11367, 2024.
[145] J.-M. Liu, H.-K. Yang, T.-C. Chiang, T.-R. Liu, C.-W. Huang, Q. Kong, N. Kobori, and C.-Y. Lee, “Enhancing visual relocalization with dense scene coordinates derived from 3d gaussian splatting,” in RoboNerF: 1st Workshop On Neural Fields In Robotics at ICRA 2024.
[146] M. Bortolon, T. Tsesmelis, S. James, F. Poiesi, and A. Del Bue, “6dgs: 6d pose estimation from a single image and a 3d gaussian splatting model,” arXiv preprint arXiv:2407.15484, 2024.
[147] Y. Fu, S. Liu, A. Kulkarni, J. Kautz, A. A. Efros, and X. Wang, “Colmap-free 3d gaussian splatting,” arXiv preprint arXiv:2312.07504, 2023.
[148] H. Li, Y. Gao, D. Zhang, C. Wu, Y. Dai, C. Zhao, H. Feng, E. Ding, J. Wang, and J. Han, “Ggrt: Towards generalizable 3d gaussians without pose priors in real-time,” arXiv preprint arXiv:2403.10147, 2024.
[149] J. Chang, Y. Xu, Y. Li, Y. Chen, and X. Han, “Gaussreg: Fast 3d registration with gaussian splatting,” arXiv preprint arXiv:2407.05254, 2024.
[150] C. Liu, S. Chen, Y. Bhalgat, S. Hu, Z. Wang, M. Cheng, V. A. Prisacariu, and T. Braud, “Gsloc: Efficient camera pose refinement via 3d gaussian splatting,” arXiv preprint arXiv:2408.11085, 2024.
[151] R. Jin, Y. Gao, H. Lu, and F. Gao, “Gs-planner: A gaussiansplatting-based planning framework for active high-fidelity reconstruction,” arXiv preprint arXiv:2405.10142, 2024.
[152] X. Lei, M. Wang, W. Zhou, and H. Li, “Gaussnav: Gaussian splatting for visual navigation,” arXiv preprint arXiv:2403.11625, 2024.
[153] T. Chen, O. Shorinwa, W. Zeng, J. Bruno, P. Dames, and M. Schwager, “Splat-nav: Safe real-time robot navigation in gaussian splatting maps,” arXiv preprint arXiv:2403.02751, 2024.
[154] G. Liu, W. Jiang, B. Lei, V. Pandey, K. Daniilidis, and N. Motee, “Beyond uncertainty: Risk-aware active view acquisition for safe robot navigation and 3d scene understanding with fisherrf,” arXiv preprint arXiv:2403.11396, 2024.
[155] J. Oh, J. Chung, D. Lee, and K. M. Lee, “Deblurgs: Gaussian splatting for camera motion blur,” arXiv preprint arXiv:2404.11358, 2024.
[156] L. Zhao, P. Wang, and P. Liu, “Bad-gaussians: Bundle adjusted deblur gaussian splatting,” arXiv preprint arXiv:2403.11831, 2024.
[157] W. Chen and L. Liu, “Deblur-gs: 3d gaussian splatting from camera motion blurred images,” Proc. of the ACM on Computer Graphics and Interactive Techniques, vol. 7, no. 1, pp. 1–15, 2024.
[158] F. Darmon, L. Porzi, S. Rota-Bul `o, and P. Kontschieder, “Robust gaussian splatting,” arXiv preprint arXiv:2404.04211, 2024.
[159] O. Seiskari, J. Ylilammi, V. Kaatrasalo, P. Rantalankila, M. Turkulainen, J. Kannala, E. Rahtu, and A. Solin, “Gaussian splatting on the move: Blur and rolling shutter compensation for natural camera motion,” arXiv preprint arXiv:2403.13327, 2024.
[160] J. Lee, D. Kim, D. Lee, S. Cho, and S. Lee, “Crim-gs: Continuous rigid motion-aware gaussian splatting from motion blur images,” arXiv preprint arXiv:2407.03923, 2024.
[161] R. T. Chen, Y. Rubanova, J. Bettencourt, and D. K. Duvenaud, “Neural ordinary differential equations,” NeurIPS, vol. 31, 2018.
[162] C. Peng, Y. Tang, Y. Zhou, N. Wang, X. Liu, D. Li, and R. Chellappa, “Bags: Blur agnostic gaussian splatting through multiscale kernel modeling,” arXiv preprint arXiv:2403.04926, 2024.
[163] Y. Chen and G. H. Lee, “Dogaussian: Distributed-oriented gaussian splatting for large-scale 3d reconstruction via gaussian consensus,” arXiv preprint arXiv:2405.13943, 2024.
[164] K. Ren, L. Jiang, T. Lu, M. Yu, L. Xu, Z. Ni, and B. Dai, “Octreegs: Towards consistent real-time rendering with lod-structured 3d gaussians,” arXiv preprint arXiv:2403.17898, 2024.
[165] Y. Liu, H. Guan, C. Luo, L. Fan, J. Peng, and Z. Zhang, “Citygaussian: Real-time high-quality large-scale scene rendering with gaussians,” arXiv preprint arXiv:2404.01133, 2024.
[166] B. Kerbl, A. Meuleman, G. Kopanas, M. Wimmer, A. Lanvin, and G. Drettakis, “A hierarchical 3d gaussian representation for realtime rendering of very large datasets,” ACM Trans. Graph., vol. 43, no. 4, pp. 1–15, 2024.
[167] T. Suzuki, “Fed3dgs: Scalable 3d gaussian splatting with federated learning,” arXiv preprint arXiv:2403.11460, 2024.
[168] Z. Wang and D. Xu, “Pygs: Large-scale scene representation with pyramidal 3d gaussian splatting,” arXiv preprint arXiv:2405.16829, 2024.
[169] J. Lin, Z. Li, X. Tang, J. Liu, S. Liu, J. Liu, Y. Lu, X. Wu, S. Xu, Y. Yan et al., “Vastgaussian: Vast 3d gaussians for large scene reconstruction,” in CVPR, 2024, pp. 5166–5175.
[170] J. C. Lee, D. Rho, X. Sun, J. H. Ko, and E. Park, “Compact 3d gaussian representation for radiance field,” in CVPR, 2024, pp. 21 719–21 728.
[171] K. Navaneet, K. P. Meibodi, S. A. Koohpayegani, and H. Pirsiavash, “Compact3d: Smaller and faster gaussian splatting with vector quantization,” arXiv preprint arXiv:2311.18159, 2023.
[172] T. Lu, M. Yu, L. Xu, Y. Xiangli, L. Wang, D. Lin, and B. Dai, “Scaffold-gs: Structured 3d gaussians for view-adaptive rendering,” in CVPR, 2024, pp. 20 654–20 664.
[173] X. Sun, J. C. Lee, D. Rho, J. H. Ko, U. Ali, and E. Park, “F3dgs: Factorized coordinates and representations for 3d gaussian splatting,” arXiv preprint arXiv:2405.17083, 2024.
[174] H. Wang, H. Zhu, T. He, R. Feng, J. Deng, J. Bian, and Z. Chen, “End-to-end rate-distortion optimized 3d gaussian representation,” arXiv preprint arXiv:2406.01597, 2024.
[175] Z. Fan, K. Wang, K. Wen, Z. Zhu, D. Xu, and Z. Wang, “Lightgaussian: Unbounded 3d gaussian compression with 15x reduction and 200+ fps,” NeurIPS, 2023.
[176] M. Niemeyer, F. Manhardt, M.-J. Rakotosaona, M. Oechsle, D. Duckworth, R. Gosula, K. Tateno, J. Bates, D. Kaeser, and F. Tombari, “Radsplat: Radiance field-informed gaussian splatting for robust real-time rendering with 900+ fps,” arXiv preprint arXiv:2403.13806, 2024.
[177] W. Liu, T. Guan, B. Zhu, L. Ju, Z. Song, D. Li, Y. Wang, and W. Yang, “Efficientgs: Streamlining gaussian splatting for large-scale high-resolution scene representation,” arXiv preprint arXiv:2404.12777, 2024.
[178] A. Hanson, A. Tu, V. Singla, M. Jayawardhana, M. Zwicker, and T. Goldstein, “Pup 3d-gs: Principled uncertainty pruning for 3d gaussian splatting,” arXiv preprint arXiv:2406.10219, 2024.
[179] P. Papantonakis, G. Kopanas, B. Kerbl, A. Lanvin, and G. Drettakis, “Reducing the memory footprint of 3d gaussian splatting,” Proc. of the ACM on Computer Graphics and Interactive Techniques, vol. 7, no. 1, pp. 1–17, 2024.
[180] O. Mahmoud and M. Gendrin, “On reducing the number of gaussians for radiance field real-time rendering,” in 2024 ECTI DAMT & NCON. IEEE, 2024, pp. 259–264.
[181] S. Subhajyoti Mallick, R. Goel, B. Kerbl, F. V. Carrasco, M. Steinberger, and F. De La Torre, “Taming 3dgs: High-quality radiance fields with limited resources,” arXiv e-prints, pp. arXiv–2406, 2024.
[182] S. Niedermayr, J. Stumpfegger, and R. Westermann, “Compressed 3d gaussian splatting for accelerated novel view synthesis,” in CVPR, 2024, pp. 10 349–10 358.
[183] Y. Chen, Q. Wu, J. Cai, M. Harandi, and W. Lin, “Hac: Hash-grid assisted context for 3d gaussian splatting compression,” arXiv preprint arXiv:2403.14530, 2024.
[184] X. Liu, X. Wu, P. Zhang, S. Wang, Z. Li, and S. Kwong, “Compgs: Efficient 3d scene representation via compressed gaussian splatting,” arXiv preprint arXiv:2404.09458, 2024.
[185] Y. Wang, Z. Li, L. Guo, W. Yang, A. C. Kot, and B. Wen, “Contextgs: Compact 3d gaussian splatting with anchor level context model,” arXiv preprint arXiv:2405.20721, 2024.
[186] W. Morgenstern, F. Barthel, A. Hilsmann, and P. Eisert, “Compact 3d scene representation via self-organizing gaussian grids,” arXiv preprint arXiv:2312.13299, 2023.
[187] Z. Zhu, Z. Fan, Y. Jiang, and Z. Wang, “Fsgs: Real-time fewshot view synthesis using gaussian splatting,” arXiv preprint arXiv:2312.00451, 2023.
[188] J. Chung, J. Oh, and K. M. Lee, “Depth-regularized optimization for 3d gaussian splatting in few-shot images,” in CVPR, 2024, pp. 811–820.
[189] A. Paliwal, W. Ye, J. Xiong, D. Kotovenko, R. Ranjan, V. Chandra, and N. K. Kalantari, “Coherentgs: Sparse novel view synthesis with coherent 3d gaussians,” arXiv preprint arXiv:2403.19495, 2024.
[190] Y. Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T.-J. Cham, and J. Cai, “Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,” arXiv preprint arXiv:2403.14627, 2024.
[191] H. Xiong, S. Muttukuru, R. Upadhyay, P. Chari, and A. Kadambi, “Sparsegs: Real-time 360◦ sparse view synthesis using gaussian splatting,” arXiv preprint arXiv:2312.00206, 2023.
[192] Z. Bao, G. Liao, K. Zhou, K. Liu, Q. Li, and G. Qiu, “Loopsparsegs: Loop based sparse-view friendly gaussian splatting,” arXiv preprint arXiv:2408.00254, 2024.
[193] J. Zhang, J. Li, X. Yu, L. Huang, L. Gu, J. Zheng, and X. Bai, “Corgs: Sparse-view 3d gaussian splatting via co-regularization,” arXiv preprint arXiv:2405.12110, 2024.
[194] J. Li, J. Zhang, X. Bai, J. Zheng, X. Ning, J. Zhou, and L. Gu, “Dngaussian: Optimizing sparse-view 3d gaussian radiance fields with global-local depth normalization,” in CVPR, 2024, pp. 20 775–20 785.
[195] Z. Fan, W. Cong, K. Wen, K. Wang, J. Zhang, X. Ding, D. Xu, B. Ivanovic, M. Pavone, G. Pavlakos et al., “Instantsplat: Unbounded sparse-view pose-free gaussian splatting in 40 seconds,” arXiv preprint arXiv:2403.20309, 2024.
[196] J. Straub, T. Whelan, L. Ma, Y. Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Verma et al., “The replica dataset: A digital replica of indoor spaces,” arXiv:1906.05797, 2019.
[197] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” in CVPR, 2017, pp. 5828–5839.
[198] J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A benchmark for the evaluation of rgb-d slam systems,” in 2012 IEEE/RSJ int. conf. on intelligent robots and systems, 2012, pp. 573580.
[199] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE trans. on image processing, vol. 13, no. 4, pp. 600–612, 2004.
[200] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in CVPR, 2018, pp. 586–595.
[201] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in CVPR, 2012, pp. 3354–3361.
[202] P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, J. Guo, Y. Zhou, Y. Chai, B. Caine et al., “Scalability in perception for autonomous driving: Waymo open dataset,” in CVPR, 2020, pp. 2446–2454.
[203] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” in CVPR, 2020, pp. 11 621–11 631.
[204] M.-F. Chang, J. Lambert, P. Sangkloy, J. Singh, S. Bak, A. Hartnett, D. Wang, P. Carr, S. Lucey, D. Ramanan et al., “Argoverse: 3d tracking and forecasting with rich maps,” in CVPR, 2019, pp. 8748–8757.
[205] A. Knapitsch, J. Park, Q.-Y. Zhou, and V. Koltun, “Tanks and temples: Benchmarking large-scale scene reconstruction,” ACM Trans. Graph., vol. 36, no. 4, pp. 1–13, 2017.
[206] J. Shotton, B. Glocker, C. Zach, S. Izadi, A. Criminisi, and A. Fitzgibbon, “Scene coordinate regression forests for camera relocalization in rgb-d images,” in CVPR, 2013, pp. 2930–2937.
[207] A. Mirzaei, T. Aumentado-Armstrong, K. G. Derpanis, J. Kelly, M. A. Brubaker, I. Gilitschenski, and A. Levinshtein, “Spin-nerf: Multiview segmentation and perceptual inpainting with neural radiance fields,” in CVPR, 2023, pp. 20 669–20 679.
[208] J. Kerr, C. M. Kim, K. Goldberg, A. Kanazawa, and M. Tancik, “Lerf: Language embedded radiance fields,” in ICCV, 2023, pp. 19 729–19 739.
[209] S. James, Z. Ma, D. R. Arrojo, and A. J. Davison, “Rlbench: The robot learning benchmark & learning environment,” RA-L, vol. 5, no. 2, pp. 3019–3026, 2020.
[210] A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y. Zhu, and R. Mart ́ın-Mart ́ın, “What matters in learning from offline human demonstrations for robot manipulation,” arXiv preprint arXiv:2108.03298, 2021.
[211] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in Int. conf. on machine learning. PMLR, 2018, pp. 1861–1870.
[212] A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y. Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,” arXiv preprint arXiv:1709.06158, 2017.
[213] K. Yadav, R. Ramrakhya, S. K. Ramakrishnan, T. Gervet, J. Turner, A. Gokaslan, N. Maestre, A. X. Chang, D. Batra, M. Savva et al., “Habitat-matterport 3d semantics dataset,” in CVPR, 2023, pp. 4927–4936.
[214] M. Savva, A. Kadian, O. Maksymets, Y. Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V. Koltun, J. Malik et al., “Habitat: A platform for embodied ai research,” in ICCV, 2019, pp. 9339–9347.
[215] P. Anderson, A. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V. Koltun, J. Kosecka, J. Malik, R. Mottaghi, M. Savva et al., “On evaluation of embodied navigation agents,” arXiv preprint arXiv:1807.06757, 2018.
[216] C. R. Givens and R. M. Shortt, “A class of wasserstein metrics for probability distributions.” Michigan Mathematical Journal, vol. 31, no. 2, pp. 231–240, 1984.
评论