我们发布了OpenAI o3‑mini,这是我们的推理系列中最新的、最具成本效益的模型,今天在ChatGPT和API中均可使用。该模型于2024年12月预览,这款强大且快速的模型突破了小型模型所能达到的边界,提供了卓越的STEM能力——特别是在科学、数学和编程方面——同时保持了OpenAI o1‑mini的低成本和低延迟。
OpenAI o3‑mini是我们第一款支持开发者高度需求功能的小型推理模型,包括函数调用、结构化输出和开发者消息,使其在发布时即具备生产就绪性。与OpenAI o1‑mini和OpenAI o1‑preview一样,o3‑mini将支持流式传输。此外,开发者可以选择三种推理努力程度——低、中、高——以优化其特定用例。这种灵活性使得o3‑mini在应对复杂挑战时可以“更深入地思考”,或在延迟成为问题时优先考虑速度。o3‑mini不支持视觉能力,因此开发者应继续使用OpenAI o1进行视觉推理任务。o3‑mini今天开始在Chat Completions API、Assistants API和Batch API中向API使用级别3-5的开发者推出。
ChatGPT Plus、Team和Pro用户今天起可以访问OpenAI o3‑mini,企业访问将于二月推出。o3‑mini将取代OpenAI o1‑mini在模型选择器中的位置,提供更高的速率限制和更低的延迟,使其成为编码、STEM和逻辑问题解决任务的理想选择。作为此次升级的一部分,我们将Plus和Team用户的速率限制从o1‑mini的每天50条消息提高到o3‑mini的每天150条消息。此外,o3‑mini现在可以与搜索结合使用,以找到最新的答案并提供相关网页来源的链接。这是我们努力将搜索集成到推理模型中的早期原型。
从今天起,免费计划用户也可以通过选择消息编辑器中的“推理”或重新生成响应来尝试OpenAI o3‑mini。这是首次在ChatGPT中向免费用户提供推理模型。
虽然OpenAI o1仍然是我们的广泛通用知识推理模型,但OpenAI o3‑mini为需要精确性和速度的技术领域提供了专门的替代方案。在ChatGPT中,o3‑mini使用中等推理努力程度,以在速度和准确性之间提供平衡。所有付费用户还可以在模型选择器中选择o3‑mini‑high,以获得需要稍长时间生成响应的高智能版本。Pro用户可以无限制地访问o3‑mini和o3‑mini‑high。
快速、强大且针对STEM推理优化 与OpenAI o1前身类似,OpenAI o3‑mini针对STEM推理进行了优化。使用中等推理努力程度的o3‑mini在数学、编码和科学方面的表现与o1相当,同时提供更快的响应。专家测试人员的评估显示,o3‑mini比OpenAI o1‑mini产生更准确、更清晰的答案,具有更强的推理能力。测试人员更喜欢o3‑mini的响应,而不是o1‑mini的响应,占56%的时间,并且在困难的现实世界问题上观察到主要错误减少了39%。使用中等推理努力程度,o3‑mini在包括AIME和GPQA在内的最具挑战性的推理和智力评估中与o1的表现相当。
Competition Math (AIME 2024)
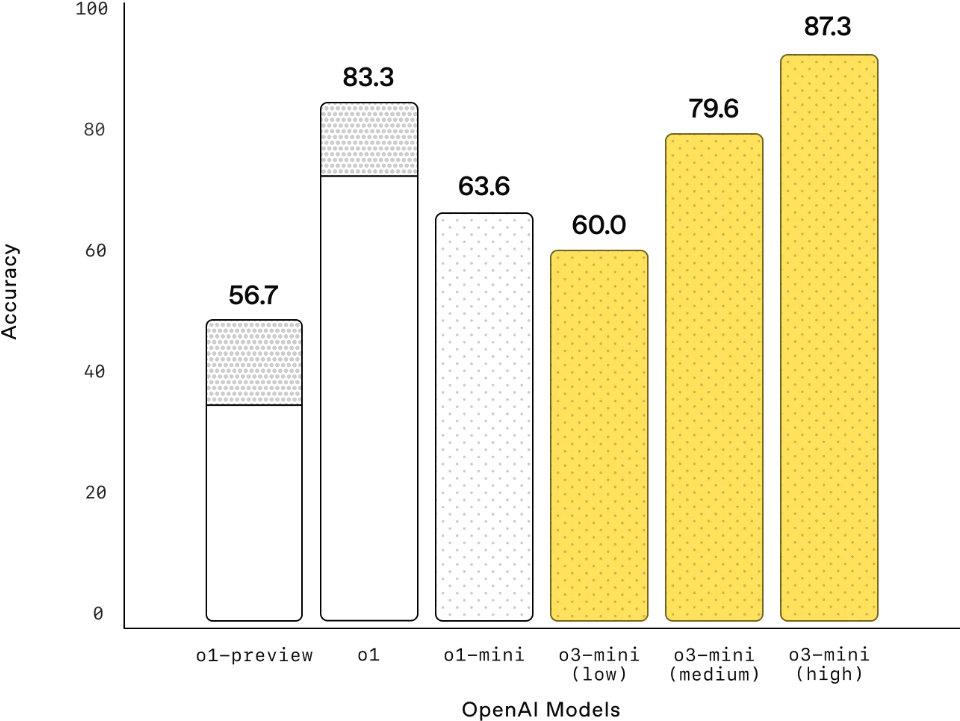
数学: 在低推理努力程度下,OpenAI o3‑mini的表现与OpenAI o1‑mini相当,而在中等努力程度下,o3‑mini的表现与o1相当。同时,在高推理努力程度下,o3‑mini的表现优于OpenAI o1‑mini和OpenAI o1,其中灰色阴影区域显示了64个样本的多数投票(共识)表现。
PhD-level Science Questions (GPQA Diamond)
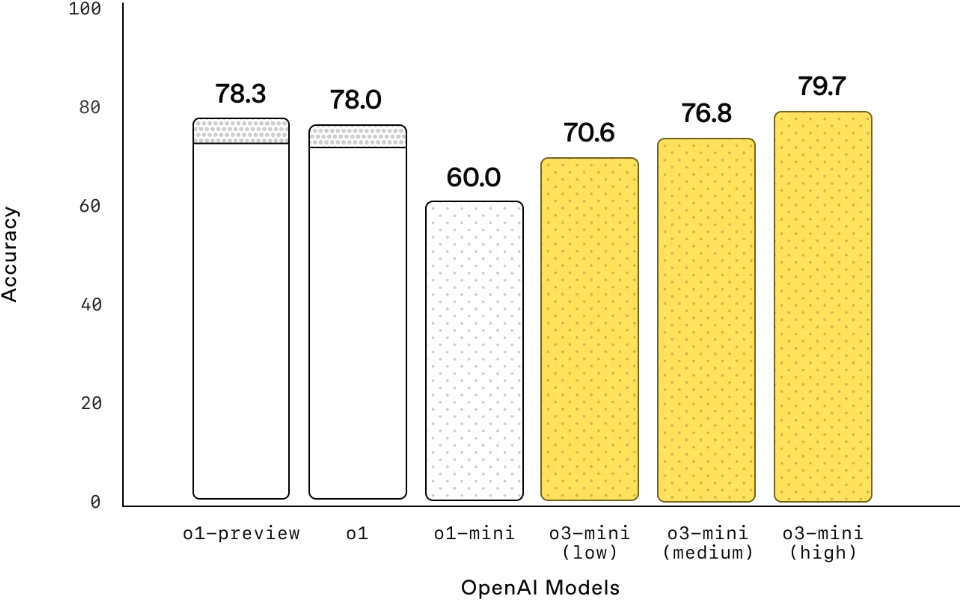
博士级科学: 在博士级生物学、化学和物理问题上,低推理努力程度下,OpenAI o3‑mini的表现高于OpenAI o1‑mini。在高努力程度下,o3‑mini的表现与o1相当。
FrontierMath
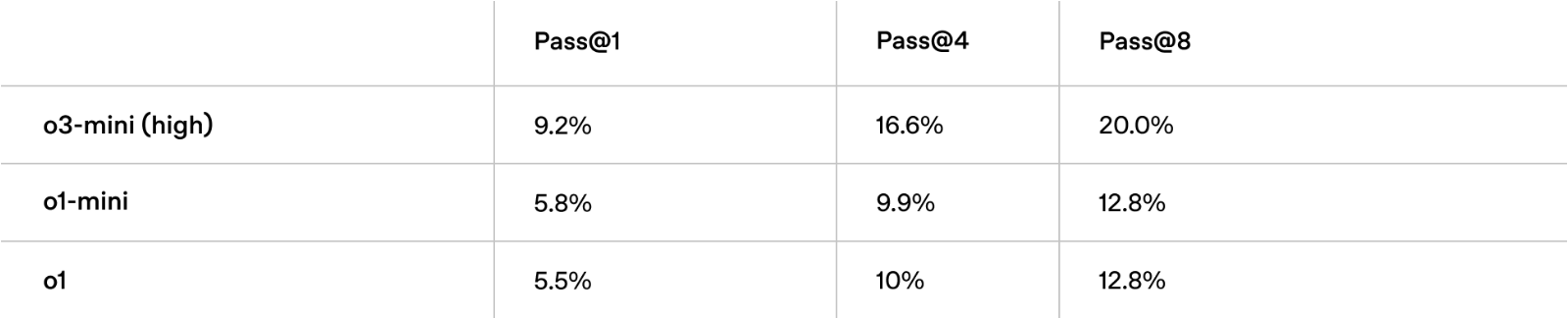
研究级数学: 在高推理努力程度下,OpenAI o3‑mini在FrontierMath上的表现优于其前身。在FrontierMath上,当提示使用Python工具时,高推理努力程度的o3‑mini首次尝试解决了超过32%的问题,包括超过28%的挑战性(T3)问题。这些数字是临时的,上图显示了不使用工具或计算器的表现。
Competition Code (Codeforces)
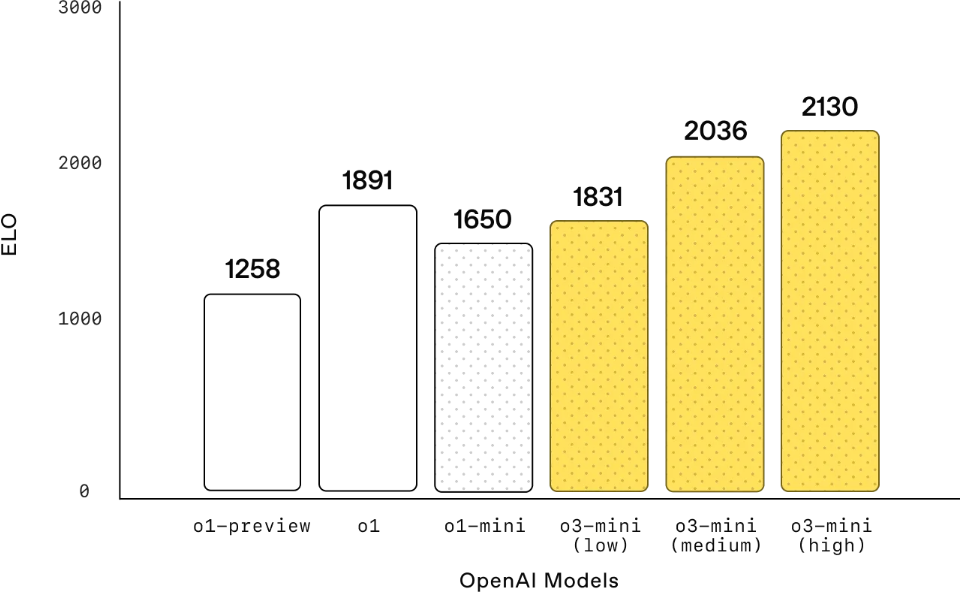
竞赛编程: 在Codeforces竞赛编程中,OpenAI o3‑mini随着推理努力程度的增加,Elo分数逐渐提高,均优于o1‑mini。在中等推理努力程度下,其表现与o1相当。
Software Engineering (SWE-bench Verified)
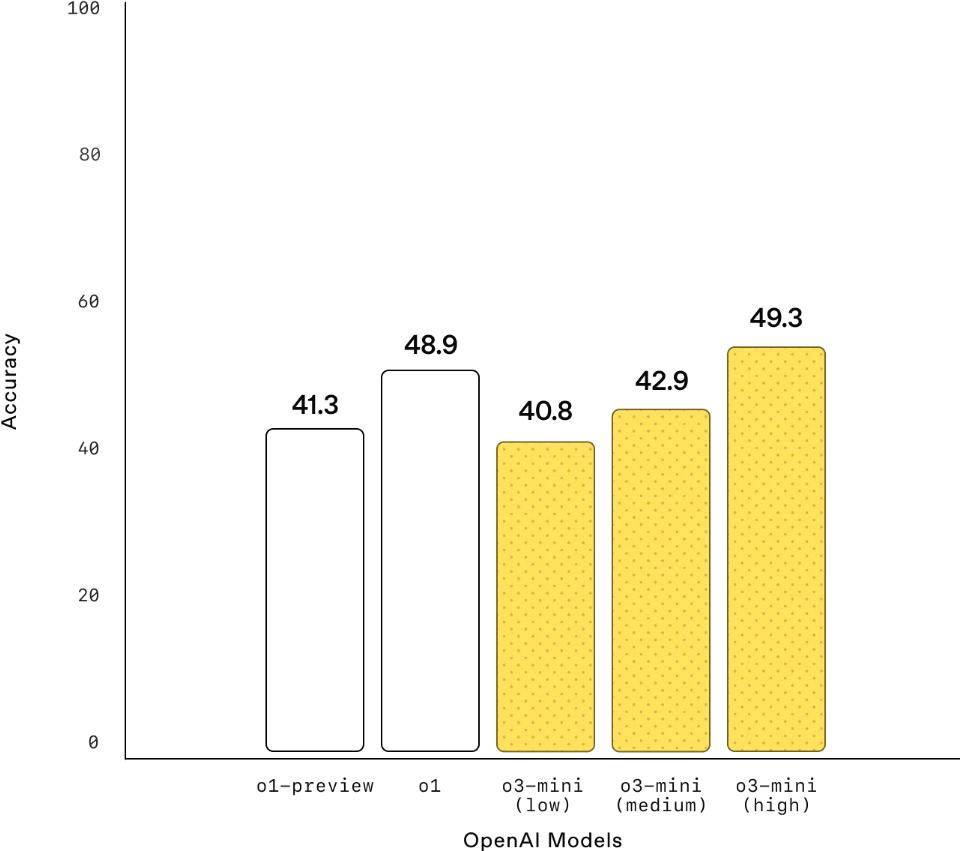
软件工程: o3‑mini是我们在SWEbench-verified上表现最高的发布模型。有关高推理努力程度下SWE-bench Verified结果的额外数据点,包括使用开源Agentless框架(39%)和代表最大能力激发内部工具框架(61%),请参阅我们的系统卡作为权威来源。
LiveBench编程
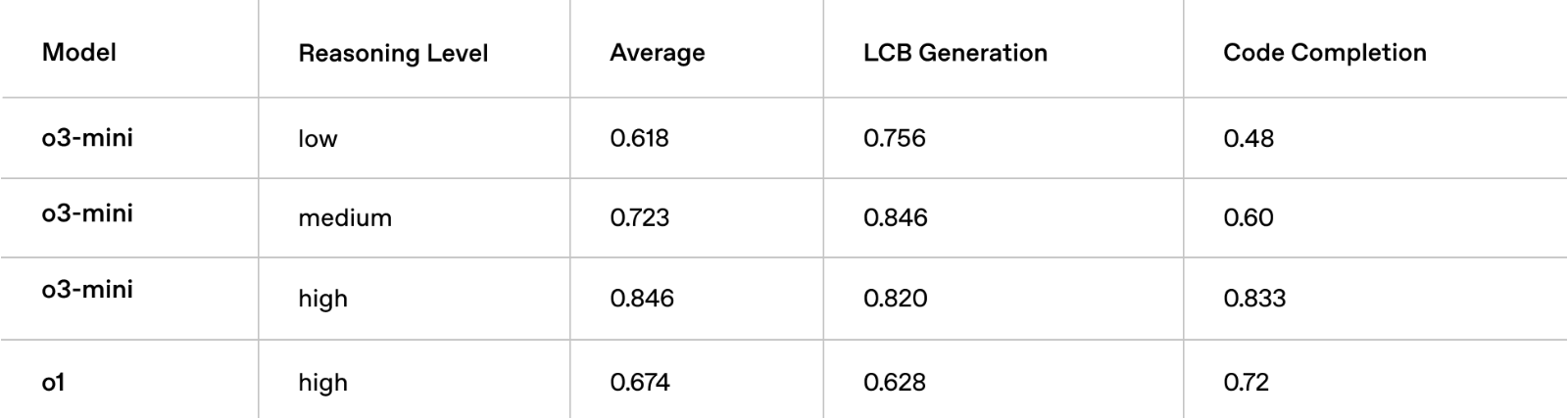
LiveBench编程: 即使在中等推理努力程度下,OpenAI o3‑mini也超越了o1‑high,突显了其在编码任务中的效率。在高推理努力程度下,o3‑mini进一步扩大了领先优势,在关键指标上实现了显著更强的表现。
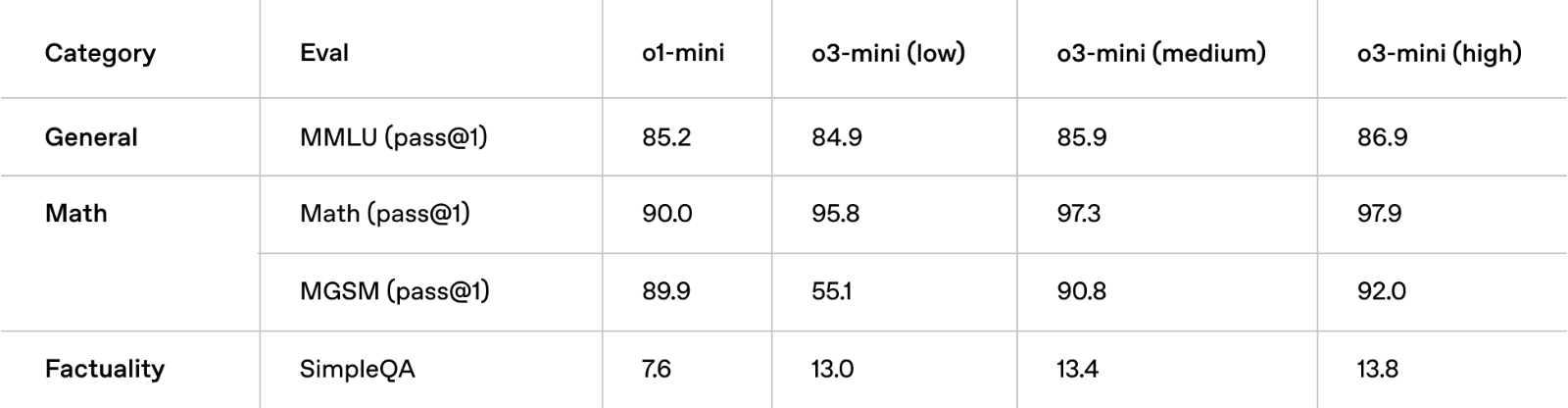
通用知识: 在通用知识领域的评估中,o3‑mini的表现优于o1‑mini。
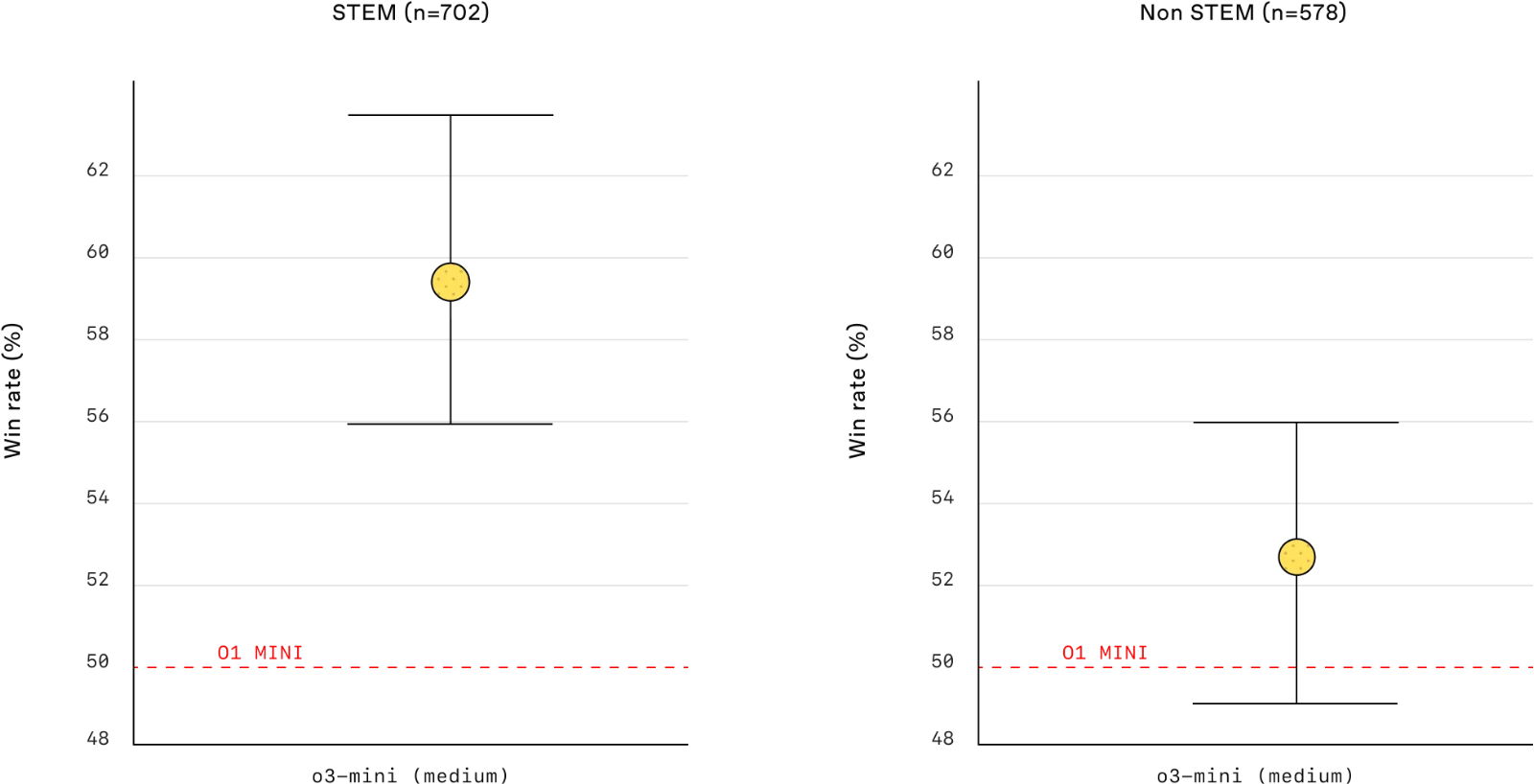
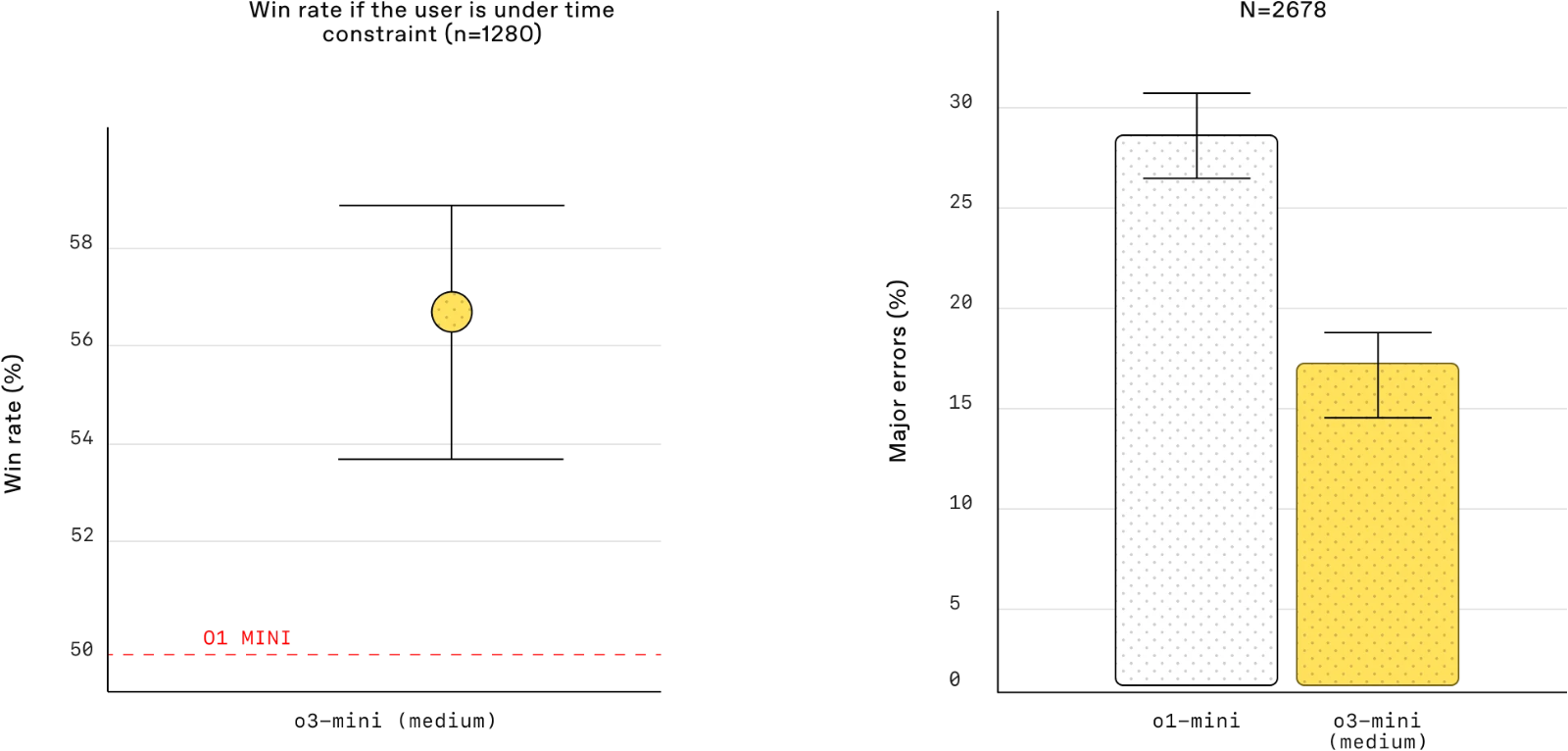
人类偏好评估: 外部专家测试人员的评估也显示,OpenAI o3‑mini比OpenAI o1‑mini产生更准确、更清晰的答案,尤其是在STEM领域具有更强的推理能力。测试人员更喜欢o3‑mini的响应,而不是o1‑mini的响应,占56%的时间,并且在困难的现实世界问题上观察到主要错误减少了39%。
模型速度与性能
OpenAI o3‑mini在智能上与OpenAI o1相当,但提供了更快的性能和更高的效率。除了上述强调的STEM评估外,o3‑mini在中等推理努力程度下,在额外的数学和事实性评估中也表现出色。在A/B测试中,o3‑mini的响应速度比o1‑mini快24%,平均响应时间为7.7秒,而o1‑mini为10.16秒。
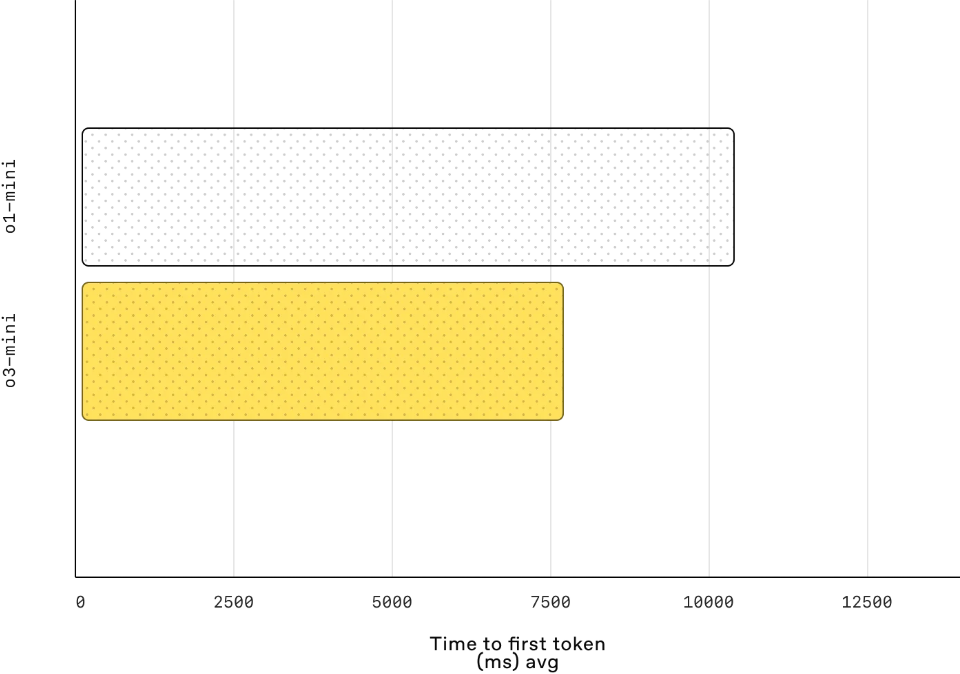
延迟: o3‑mini的平均首个token时间比o1‑mini快2500ms。
安全性
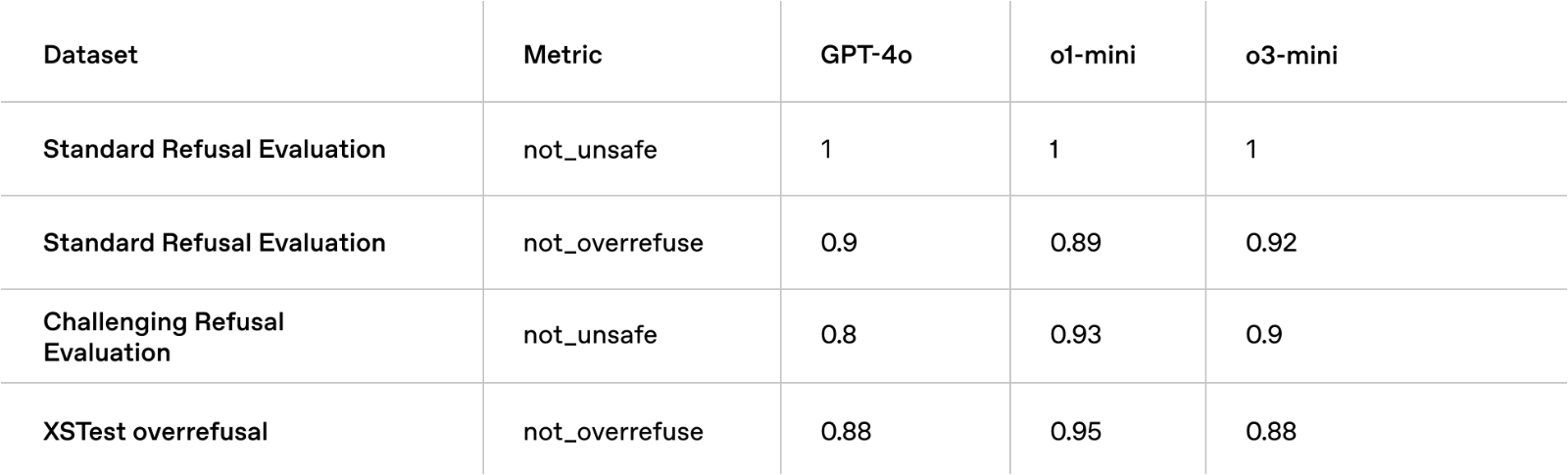
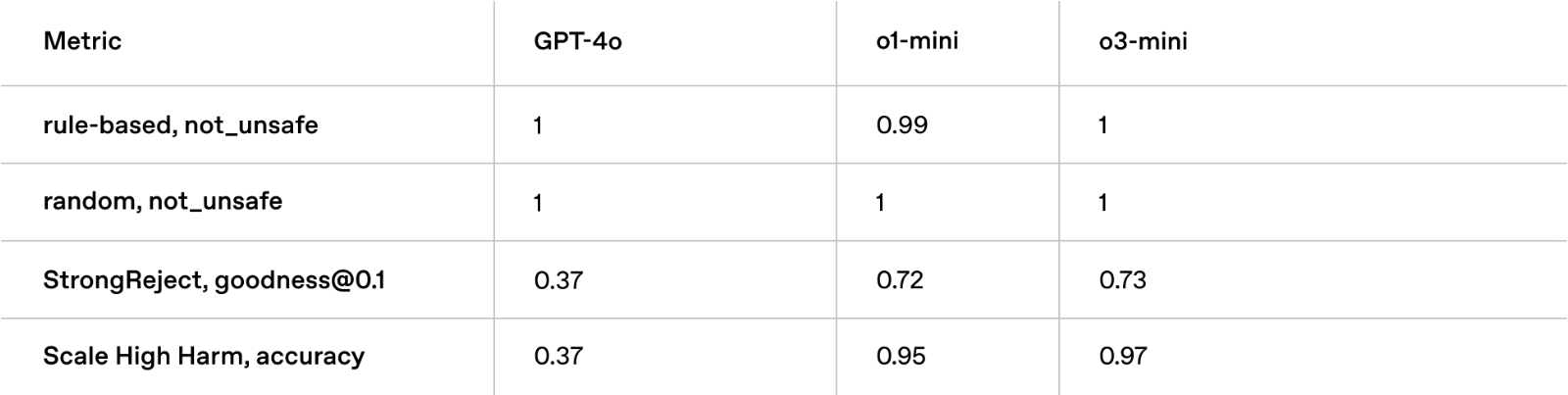
我们用于教导OpenAI o3‑mini安全回应的关键技术之一是审议对齐,即在回答用户提示之前,我们训练模型推理人类编写的安全规范。与OpenAI o1类似,我们发现o3‑mini在具有挑战性的安全和越狱评估中显著超越了GPT‑4o。在部署之前,我们使用与o1相同的准备、外部红队和安全评估方法,仔细评估了o3‑mini的安全风险。我们感谢在早期访问中申请测试o3‑mini的安全测试人员。评估的详细信息以及潜在风险和缓解措施有效性的全面解释,可在o3‑mini系统卡中找到。
Disallowed content evaluations
Jailbreak Evaluations
下一步
OpenAI o3‑mini的发布标志着OpenAI在推动成本效益智能边界使命中的又一步。通过优化STEM领域的推理并保持低成本,我们使高质量AI更加普及。该模型延续了我们降低智能成本的记录——自GPT‑4推出以来,每个token的价格降低了95%——同时保持了顶级的推理能力。随着AI采用范围的扩大,我们仍然致力于在前沿领域引领,构建在智能、效率和安全之间实现大规模平衡的模型。
关键问题解答
什么是STEM?
STEM是科学(Science)、技术(Technology)、工程(Engineering)和数学(Mathematics)四类学科的简称,强调多个学科的交叉融汇,旨在通过整合不同学科的知识,培养学生的设计能力、合作能力、问题解决能力和实践创新能力。
STEM理念最早可追溯到20世纪50年代美国学者提出的科学素养概念,并在1986年由美国国家科学委员会首次明确提出整合科学、数学、工程和技术教育的纲领性建议。STEM教育不仅仅是这些学科的简单组合,而是一种解决现实问题的方法,强调从科学规律探索到技术工具开发、工程方案落地、数学建模验证的全链条协作。
STEM的核心价值在于通过跨学科的融合,推动科技进步、提升经济竞争力,并培养具备创新能力和批判性思维的复合型人才。
什么是AIME?
AIME(American Invitational Mathematics Examination,美国数学邀请赛)是美国数学竞赛(AMC)系列赛事中的重要一环,衔接了AMC10/12与美国数学奥林匹克(USAMO)/美国少年数学奥林匹克(USAJMO)。AIME主要面向在AMC10/12竞赛中表现优异的学生开放,具体来说,AMC12测验中得分在100分以上或成绩为所有参赛者的前5%,以及在AMC10测验中成绩为所有参赛者的前1%的学生,都有资格被邀请参加AIME。
AIME竞赛始于1983年,通常在每年的2月份举行,分为AIME I和AIME II两场,考试时长为3小时,试卷包含15道填空题,总分为15分。所有题目的答案均需在000至999的数字范围内给出。
AIME的含金量很高,尤其是在申请美国学校的时候。许多顶尖大学,如斯坦福大学、麻省理工学院(MIT)、耶鲁、哥大等,在申请表格中都专门设有填写AMC/AIME成绩的栏目,这些学校对AIME成绩给予了高度的认可和重视。
AIME竞赛的目的是选拔在大学之前阶段在数学方面表现出色的学生,为美国数学奥林匹克竞赛选拔参赛者。该考试为数学方面有优势的高中生提供了进一步挑战的机会,也为他们认识自己的才能提供了机会。
什么是GPQA?
GPQA(Graduate-Level Google-Proof Q&A Benchmark)是一个高难度的问答基准测试,专门用于评估模型在研究生级别知识水平和复杂推理场景下的表现。它由生物学、物理学和化学领域的专家编写,包含448道多项选择题,特点是高质量和极端难度。即使是拥有或正在攻读相关领域博士学位的专家,准确率也只有65%,而高技能的非专家验证者,即使在允许访问网络超过30分钟的情况下,准确率也仅为34%。
GPQA的核心目标是精准衡量模型是否具备深入理解专业知识、运用逻辑思维解决复杂问题以及进行审慎推理的能力,推动人工智能迈向能够处理现实世界中高难度专业任务的新阶段,助力实现专家级通用人工智能(AGI)的长远目标。
GPQA-Diamond是GPQA系列中的最高难度子集,专注于评估大模型在博士级科学问题上的推理能力和专业知识。它由纽约大学、Cohere AI和Anthropic的研究团队联合开发,包含198条高难度问题,是原版GPQA的精选子集,确保评测数据的纯净与高质量。
总的来说,GPQA是一个极具挑战性的基准测试,用于评估模型在高级推理和专业知识应用方面的能力。
什么是Elo分数?
Elo分数是一种用于评估玩家或团队相对技能水平的评分系统,最初由匈牙利裔美国物理学家阿尔帕德·埃洛(Arpad Elo)为国际象棋设计。如今,Elo评分系统被广泛应用于各种竞技游戏和体育赛事中,如围棋、电子竞技、足球等。
Elo评分系统的核心原理
1. 基础假设:Elo系统假设每位选手的表现在一定时间内是围绕某个平均水平波动的,且表现符合正态分布。通过比赛结果,系统动态调整选手的评级分数,以反映其相对实力。
2. 计算公式:
• 预期得分:假设选手A的Elo评分为\(R_A\),选手B的评分为\(R_B\),则选手A的预期得分\(E_A\)为:
\[E_A = \frac{1}{1 + 10^{(R_B - R_A)/400}}\]同理,选手B的预期得分\(E_B\)为:
\[E_B = 1 - E_A\]• 实际得分:比赛结束后,根据结果确定实际得分\(S_A\)(胜为1,负为0,平局为0.5)。
• 评分更新:选手A的新评分\(R'_A\)为:
\[R'_A = R_A + K \cdot (S_A - E_A)\]其中,\(K\)为常数,称为“K因子”,控制评分变化的速度。
Elo系统的应用
• 电子竞技:如《英雄联盟》《DOTA2》等游戏使用Elo系统进行匹配和排名。
• 传统体育:如网球、乒乓球等赛事用Elo评估选手实力和预测比赛结果。
• 在线竞赛平台:如编程竞赛、数据科学竞赛等也采用Elo机制评估参赛者水平。
Elo系统的优势
• 公平性:通过动态调整评分,实现实力相近的选手匹配,提高比赛公平性。
• 适应性:通过调整\(K\)值等参数,适应不同类型的竞技项目和选手群体。
• 可解释性:评分机制简单易懂,选手和观众可以直观理解实力变化。
Elo系统的局限性
• 忽视比赛过程:仅根据比赛结果调整评分,无法反映比赛中的具体表现差异。
• 实力波动适应性不足:面对选手实力突然大幅变化时,反应可能不够迅速。
• 对手实力估计偏差:对手的评分可能受状态等因素影响,导致评分调整不准确。
总结来说,Elo分数是一种通过比赛结果动态调整评分的系统,广泛应用于各类竞技活动,以实现公平匹配和实力评估。
什么是SWE-bench?
SWE-bench(Software Engineering Benchmark)是一个用于评估大型语言模型(LLM)解决现实世界软件工程问题能力的基准测试。它通过模拟真实的软件开发场景,要求模型生成代码补丁来解决从GitHub提取的已解决问题(issue)。每个测试样本包括一个代码库、问题描述以及相关的拉取请求(PR),其中包含解决方案代码和用于验证代码正确性的单元测试。
SWE-bench的评估方式包括两类测试:
1. FAIL_TO_PASS测试:用于验证生成的补丁是否解决了问题。
2. PASS_TO_PASS测试:确保补丁没有破坏代码库中不相关的部分。
尽管SWE-bench在评估AI模型能力方面具有重要价值,但它也存在一些局限性,例如单元测试过于严格、问题描述不够明确以及开发环境设置困难等,这些问题可能导致模型能力被低估。
为了解决这些问题,OpenAI推出了SWE-bench Verified,这是SWE-bench的改进版本。SWE-bench Verified通过人工筛选和验证,确保问题描述清晰、单元测试合理,并优化了开发环境设置,从而提高了评估的准确性和可靠性。
总结来说,SWE-bench是一个用于评估AI模型在软件工程任务中表现的重要基准测试,而SWE-bench Verified则是其改进版本,旨在更准确地反映模型的真实能力。
什么是LiveBench?
LiveBench是一个用于评估大型语言模型(LLM)性能的基准测试平台,旨在通过动态更新的问题和客观的评分机制,提供公平、准确的模型能力评估。它由图灵奖得主Yann LeCun联合Abacus.AI、纽约大学等机构推出,被称为“世界上第一个无法被操纵的LLM基准测试”。
LiveBench的核心特点:
1. 动态更新问题:每月发布新问题,基于最新发布的数据集、arXiv论文、新闻文章和IMDb电影简介生成,避免数据污染。
2. 客观评分:每个问题都有可验证的、客观的真实答案,支持自动评分,无需依赖LLM作为评委。
3. 多维度评估:涵盖推理、编程、写作、数据分析、语言理解和指令跟随等多个复杂维度。
4. 任务多样性:包含6大类18项任务,并会定期发布新的、更难的挑战。
LiveBench的应用场景:
• 模型性能对比:帮助开发者和研究人员评估不同LLM在特定任务上的表现。
• 避免数据污染:通过动态更新问题,防止模型通过训练数据“作弊”。
• 推动模型改进:为LLM的研发和优化提供数据支持。
LiveBench的权威性:
LiveBench以其权威性和客观性著称,是当前AIGC领域最具公信力的评测之一。它通过定期更新问题和自动化评分方法,确保了评测的公平性和准确性。
总结来说,LiveBench是一个动态更新、客观公正的LLM基准测试平台,旨在通过多维度评估和避免数据污染,推动大型语言模型的持续改进和公平竞争。
评论