论文重点与难点
1 研究背景与问题
-
背景:多视角三维重建是计算机图形学和视觉中的一个基础任务。近年来,基于神经辐射场(NeRF)的方法在不透明物体的三维建模和新视图合成中取得了显著进展。然而,现有方法在处理半透明物体时存在局限性,因为半透明物体的光线传输和散射特性与不透明物体不同。
-
问题:半透明物体的重建和渲染面临以下挑战:
-
半透明物体内部的光线会多次散射,导致传统方法(如NeuS)在建模时无法准确捕捉内部光线传输。
-
现有方法主要关注表面附近的权重,忽略了物体内部的密度和散射特性,导致重建结果不准确。
-
2 论文的核心贡献
-
提出了一种针对半透明物体的高保真表面重建和新视图合成框架 NeuralTO。
-
通过引入估计的常数消光系数(extinction coefficient),重新参数化了神经辐射场的密度函数,解决了现有方法在半透明物体内部密度建模上的不足。
-
提出了一个两阶段框架:
-
重建阶段:通过优化神经符号距离函数(SDF)网络,结合传输颜色和表面颜色,实现高精度的表面几何重建。
-
渲染阶段:利用重建的几何和密度场,分解散射特性为单次散射和多次散射,并通过神经参与介质(participating media)学习其神经表示,提升渲染效果。
-
-
构建了一个包含合成和真实半透明物体的数据集,用于评估重建和渲染效果。
3 方法的关键创新点
-
密度函数的重新参数化:
- 论文提出了一种基于常数消光系数的密度函数,适用于均匀材质的半透明物体。通过Laplace分布函数与SDF值结合,设计了密度场:
-
该方法确保了物体内部密度的均匀性,并且在训练过程中优化了\(\sigma_0\)和\(\beta\)。
-
多级锥形采样模块:
- 为了学习复杂的半透明外观,论文提出了一种多级锥形采样方法,用于估计多次散射。该方法通过不同层级的采样区域,高效地表示空间区域,并利用球谐函数(Spherical Harmonics)的系数进行渲染:
- 该模块能够捕捉与整体几何形状相关的多次散射特性。
4 实验与结果
-
数据集:作者构建了一个包含合成和真实半透明物体的数据集,包含“Syn-Trans”(合成图像)和“Real-Trans”(真实场景)。
-
几何重建评估:
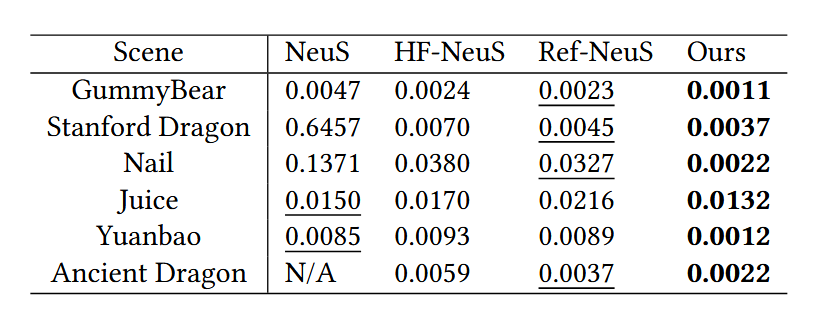
表2. Syn-Trans数据集上重建评估结果的倒角距离(CD ↓)。我们比较了使用神经隐式SDF网络的最先进重建方法:NeuS[Wang et al. 2021]、HFNeuS[Wang et al. 2022]、Ref-NeuS[Ge et al. 2023]。加粗文本表示最佳评估结果,下划线文本表示次佳结果。
-
使用Chamfer Distance(CD)评估重建精度,结果表明NeuralTO优于现有方法(如NeuS、HF-NeuS、Ref-NeuS),见表1。
-
新视图合成评估:
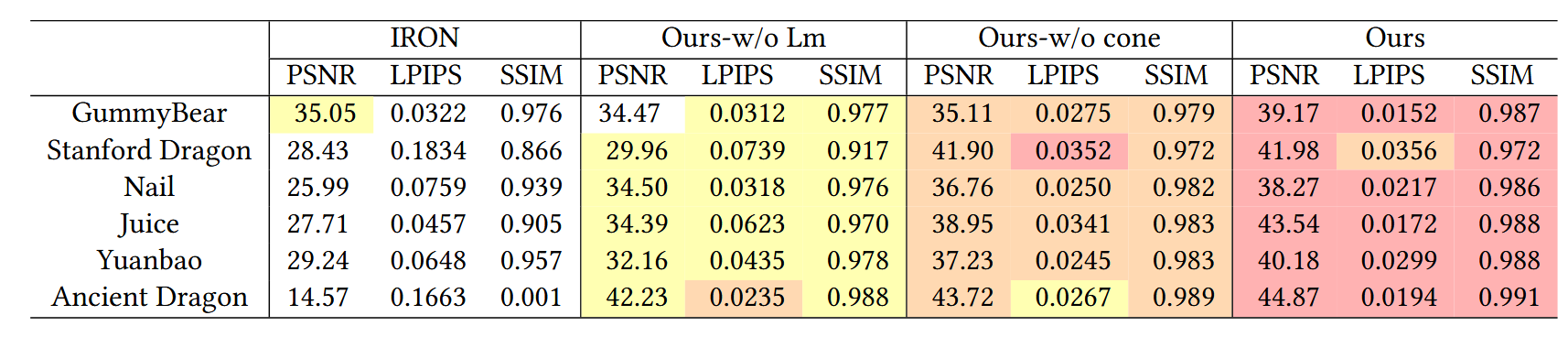
表3. 新共置闪光灯视角下渲染结果的定量比较。我们比较了IRON [Zhang et al. 2022]中的逆渲染方法与我们的方法,使用PSNR ↑、LPIPS ↓和SSIM ↑从光度图像中评估。
- 使用PSNR、LPIPS和SSIM评估渲染质量,结果表明NeuralTO在渲染效果上优于IRON等方法,见表2。
5 难点与挑战
-
半透明物体的复杂性:半透明物体的光线传输和散射特性复杂,尤其是多次散射的建模,需要考虑整体几何形状对光线路径的影响。
-
几何与材质的耦合:在重建过程中,几何形状和材质特性相互影响,如何解耦这些因素是一个难点。
-
计算效率:多级锥形采样和多次散射的建模增加了计算复杂度,如何在保持高质量渲染的同时提高效率是一个挑战。
6 局限性
-
论文忽略了折射现象,对于高透明物体(如玻璃)的重建和渲染效果不佳。
-
在薄区域的渲染结果不够理想,需要进一步优化参数的不变性。
-
学习的散射特性受限于训练时的视角和光照条件,对于真实场景的新视图合成效果有限。
原文翻译
NeuralTO: Neural Reconstruction and View Synthesis of Translucent Objects
NeuralTO:半透明物体的神经重建与视角合成
YUXIANG CAI, VCIP, 南开大学计算机学院, 中国
JIAXIONG QIU, VCIP, 南开大学计算机学院, 中国
ZHONG LI, OPPO 美国研究院, 美国
BO REN, VCIP, 南开大学计算机学院, 中国
利用神经隐式符号距离函数从多视角图像中学习,在不透明物体的3D重建中表现出色。然而,现有的方法在应用于半透明物体时,由于渲染函数中存在不可忽略的偏差,难以重建准确的几何形状。为了解决现有模型中的不准确性,我们通过引入估计的恒定消光系数,重新参数化了神经辐射场的密度函数。这一修改构成了我们创新框架的基础,该框架旨在实现半透明物体的高保真表面重建和新视角合成。我们的框架包含两个阶段。在重建阶段,我们引入了一种新的权重函数,以实现准确的表面几何重建。在恢复几何形状后,第二阶段涉及学习参与介质的独特散射特性以增强渲染效果。我们构建了一个包含合成和真实半透明物体的综合数据集,用于进行广泛的实验。实验表明,我们的方法在重建和新视角合成方面优于现有方法。
CCS概念:• 计算方法 → 网格几何模型。
关键词:半透明物体,神经隐式表面,多视角3D重建
1 引言
多视角3D重建是计算机图形学和视觉中的一项基本任务。最近,受[Mildenhall et al. 2021]提出的神经辐射场的启发,许多后续工作专注于使用密度\(\sigma\)和视角相关颜色\(c\)来建模3D场景。这种学习到的隐式表示在物体或场景的新视角合成中表现出色。由VolSDF [Yariv et al. 2021]和NeuS [Wang et al. 2021]引领的改进工作使用符号距离函数(SDF)来优化密度场的视角一致性,从而可以从其中提取有意义的表面。他们提出使用神经网络学习隐式SDF,并将其与场景的密度相结合。通过多视角图像进行训练,他们优化隐式神经SDF网络以获得实体表面。
半透明物体是一类具有特殊光学特性的物体。与不透明物体不同,不透明物体会阻挡光线从外部传递到内部,而半透明物体允许光线穿过其表面,同时在不同方向上散射。对于不透明物体,所有离开物体的光线都是从表面散射的。对于半透明物体,部分离开物体的光线在离开之前已经进入物体并多次散射。最近的工作[Ge et al. 2023; Wang et al. 2022]基于NeuS [Wang et al. 2021]使用神经辐射场和隐式SDF网络进行重建,在不透明物体上取得了优异的结果。他们的方法只考虑重建表面上的点,而忽略了物体内部的点。然而,半透明外观与整体几何形状密切相关,通常在渲染结果中可以看到倒置的形状。半透明区域内的吸收和散射在渲染结果中起着关键作用,这些无法通过传统的NeuS类模型覆盖,其中权重仅在靠近不透明表面时非零。
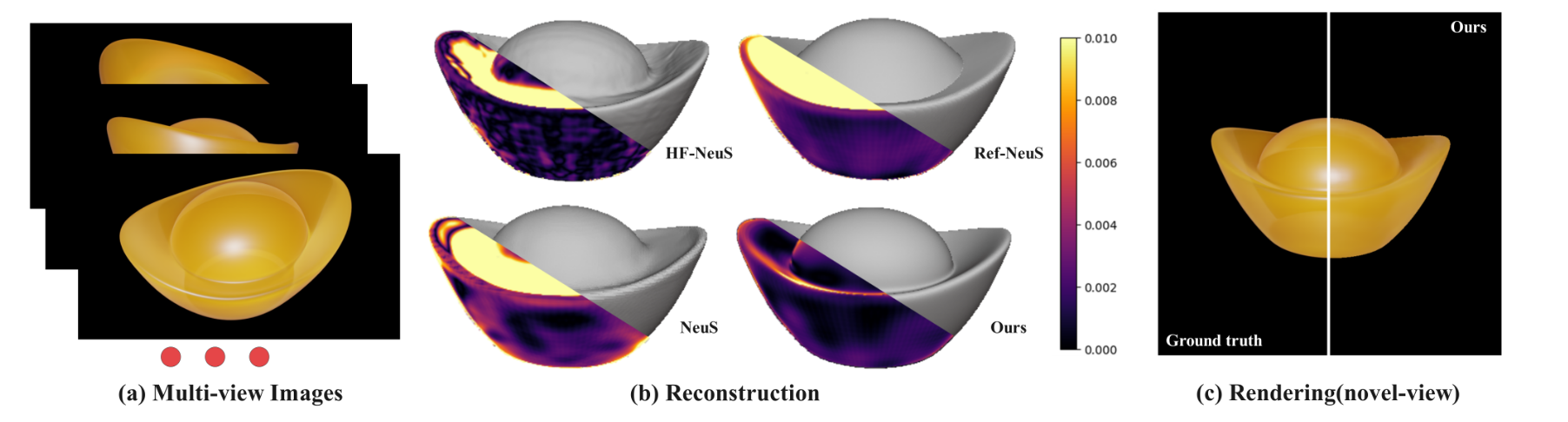
图1. 本文中,我们提出了一种用于半透明物体高保真表面重建和新视角合成的新框架。我们推导了一种增强的密度函数,确保半透明物体内部的消光系数恒定。(a) 多视角RGB图像输入。(b) 与真实几何形状相比,重建误差远小于基线方法[Ge et al. 2023; Wang et al. 2021, 2022]。(c) 使用具有解耦散射特性的学习神经参与介质,在新视角下忠实渲染半透明外观。
为了解决上述问题,我们提出了一种用于半透明物体重建和视角合成的新模型。我们提出了半透明物体神经辐射场的理论模型,并使用估计的消光系数重新参数化物体内部的密度场。消光系数(通常非正式地称为“密度”)定义了由于吸收和散射而导致的辐射净损失。对于具有均匀材料的半透明物体,它们的消光系数是恒定的。我们利用这一物理特性设计了与消光系数相关的不变密度函数。基于所提出的模型,我们设计了一个用于高保真表面重建和新视角合成的框架。我们方法的简单流程如图1所示。在第一阶段,我们结合透射颜色和表面颜色来训练我们的神经SDF网络。在第二阶段,我们利用恢复的几何形状和密度场将散射特性分解为单次散射和多次散射。对于新视角合成,我们使用参与介质和多级圆锥采样来学习它们的神经表示。
为了评估我们方法的性能,需要一个包含半透明物体的数据集来进行重建和渲染。之前的数据集如DTU [Jensen et al. 2014]和BlendedMVS [Yao et al. 2020]可用于重建和渲染不透明物体。[Ge et al. 2023]中的Shiny Blender数据集和[Liu et al. 2023]中的Glossy数据集包含具有高镜面外观的物体。然而,它们都不包含半透明物体。我们提出了一个在共置闪光灯下的半透明物体数据集,其中包含由合成图像组成的“Syn-Trans”和使用智能手机捕获的“Real-Trans”。数据集的详细信息在第4.2节中介绍。
我们总结我们的关键贡献如下:
• 我们提出了半透明物体神经辐射场的理论模型,该模型使用恒定消光系数参数化密度场。
• 我们提出了一种用于半透明物体高保真表面重建的新框架,并使用神经参与介质在共置闪光灯下优化视角合成结果。
• 我们构建了一个新的在共置闪光灯下的半透明数据集,用于评估重建和渲染结果。
2 相关工作
2.1 神经辐射场
NeRF [Mildenhall et al. 2021]利用多层感知器(MLP)网络和多视角图像学习场景的隐式表示。它提出预测3D空间中点的视角相关辐射和视角无关体积密度。NeRF是3D场景的连续隐式表示,与离散显示表示相比,其表达能力有显著提升[Gao et al. 2022; Li et al. 2023a]。通过体积渲染方程,NeRF可以从新视角合成高质量图像。许多后续工作[Chen et al. 2022, 2023; Fridovich-Keil et al. 2022; Müller et al. 2022]改进了NeRF的场景表示。Mip-NeRF [Barron et al. 2021]本质上改进了NeRF的采样理论以实现抗锯齿。NeuLF [Li et al. 2023d, 2021]使用4D光场表示场景,这对高质量新视角合成非常高效。其他工作改进了辐射场以将NeRF应用于复杂场景。Ref-NeRF [Verbin et al. 2022]、Mirror-NeRF [Zeng et al. 2023]和NeRFReN [Guo et al. 2022]在辐射场上添加了镜面反射特性。这些方法专为不透明物体设计,无法建模半透明物体的外观。对于非不透明物体,Bemana等人[Bemana et al. 2022]提出使用简化的Eikonal渲染[Ihrke et al. 2007]处理折射辐射。NeMF [Zhang et al. 2023a]将Microflake理论[Heitz et al. 2015]与神经辐射场结合。OSF [Yu et al. 2023]提出在点和光源之间进行额外采样,这需要已知物体的包围盒和光源位置。这些方法专注于新视角合成,未提及表面重建。
2.2 神经重建与隐式表面
NeRF无法精确定位物体的表面位置。为了使用神经网络表示场景表面,最常用的是占用函数和符号距离场(SDF)。早期工作如[Chen and Zhang 2019]将点云作为输入并输出隐式神经表面。更多工作专注于从多视角图像重建隐式表面,并学习由全连接MLP网络组成的SDF函数。DVR [Niemeyer et al. 2020]和IDR [Yariv et al. 2020]采用表面渲染在相对简单的场景中重建高质量表面。UNISURF [Oechsle et al. 2021]、VolSDF [Yariv et al. 2021]和NeuS [Wang et al. 2021]提出在NeRF的渲染方程中设计权重策略。UNISURF预测占用场以结合物体表面点及附近点的颜色,逐步消除训练中的歧义,最终获得实体表面。VolSDF和NeuS提出设计考虑3D空间中点SDF值的权重函数。基于VolSDF和NeuS,[Mu et al. 2023; Wu et al. 2023; Zhang et al. 2021c]等工作专注于稀疏视图下的重建。BakedSDF [Yariv et al. 2023]将漫反射颜色和镜面反射分量分解为从SDF网络提取的三角网格顶点。NeRO [Liu et al. 2023]和Ref-NeuS [Ge et al. 2023]将NeuS扩展到反射表面重建,提出从神经网络中分离反射辐射。这些方法假设相机观察到的辐射仅与表面辐照度相关,而忽略了半透明物体内部的透射和散射光。[Gao et al. 2023; Li et al. 2023b; Lyu et al. 2020]等方法专注于透明物体重建。Deng等人[2022]利用可微BSSRDF路径追踪重建真实世界中的半透明物体,但其方法计算成本高。[Lin et al. 2023]中的方法使用正弦和二进制照明模式获取半透明物体的形状,而我们的重建方法可以处理任意照明。
2.3 多图像逆渲染
给定物体的多幅图像,逆渲染旨在通过可微渲染恢复形状、材质和光照。最近的逆渲染工作利用基于物理的渲染方程,并从神经网络中学习参数。与[Deschaintre et al. 2018; Li et al. 2020; Shi et al. 2023; Wang et al. 2023; Zhu et al. 2022]等从单幅图像学习材质的方法不同,从多幅图像中学习的形状和材质更适合场景编辑。[Yao et al. 2022; Zhang et al. 2023b, 2021a,b]等工作恢复未知环境光与材质外观。[Kaya et al. 2022; Yang et al. 2022]等工作将传统光度立体法与神经辐射场结合进行重建或逆渲染。IRON [Zhang et al. 2022]在共置闪光灯下实现了令人印象深刻的材质分解。我们的工作与IRON处理相同的照明条件。为了实现鲁棒的新视角合成和渲染半透明外观,我们受益于基于物理的渲染方程,并学习具有解耦散射特性的参与介质的神经表示。
2.4 半透明物体的神经渲染
[Wang et al. 2008; Yang and Xiao 2016]等工作学习BSSRDF模型的材质属性以渲染具有散射的半透明物体。Li等人[2023c]预测用于前向渲染的参数,并训练神经网络使用这些参数预测颜色,这需要使用真实参数进行全监督训练。RPNN [Kallweit et al. 2017]和MRPNN [Hu et al. 2023]使用神经网络渲染具有复杂散射特性的半透明物体(如云),但其方法需要真实密度场并使用真实辐射进行监督。Zhu等人[2023]提出学习神经辐射传递场(NRTF)[Lyu et al. 2022]以渲染散射物体,但在学习过程中需要预计算几何形状,并且需要在不同照明条件下捕获大量图像。Zheng等人[2021]提出学习可重照明的参与介质以在已知光源位置下进行新视角合成。上述方法无法恢复几何形状,而我们的方法利用重建的几何形状渲染出更逼真的结果。
3 方法
3.1 概述
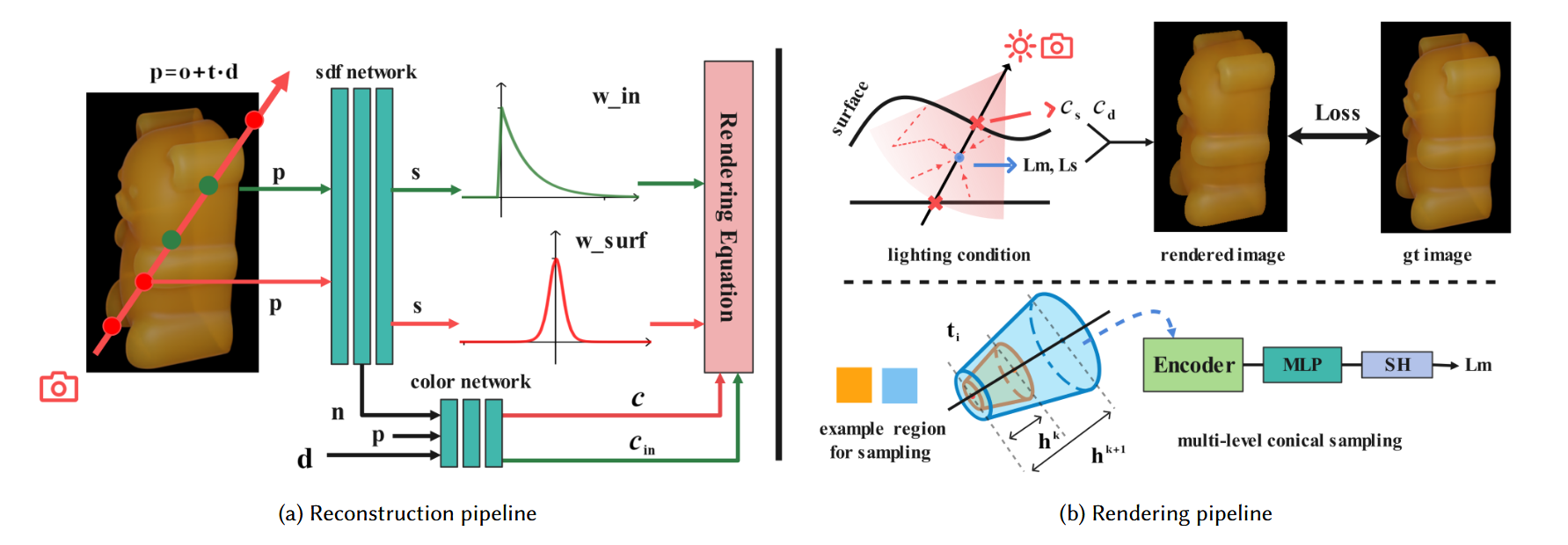
图2. 我们几何重建流程(左)和视角合成流程(右)的概述。对于几何重建,我们基于均匀介质中的恒定消光系数提出了另一种权重函数\(w_{in}\)。为了获得更好的半透明物体视觉外观,我们进一步在重建体积中建模散射特性。我们建模了直接光下的镜面颜色\(c_s\)和漫反射颜色\(c_d\),并将间接光下的散射特性分解为单次散射\(L_s\)和多次散射\(L_m\)。我们使用多级圆锥采样学习\(L_m\)的神经表示。我们方法的详细解释见第3.3节和第3.4节。
给定一组具有已知相机姿态和相机内参的半透明物体的RGB图像,我们的方法采用两个步骤来重建几何形状并渲染具有半透明外观的任意视角。我们假设所有图像均使用共置闪光灯拍摄。我们首先通过使用体积渲染方程优化神经SDF网络来重建半透明物体。我们分析了NeuS [Wang et al. 2021]基线中存在的局限性。为了解决其模型中的这些局限性,我们提出了半透明物体神经辐射场的理论模型进行重建。我们使用消光系数重新参数化物体内部的密度。我们的密度场和训练过程在第3.3节中介绍。之后,我们在基于物理的渲染方程中利用学习到的物体几何形状进行新视角合成。我们学习空间不变颜色,表示为材质中的反照率、粗糙度和透射反照率,用于在直接共置闪光灯下的表面渲染方程。对于间接光下的详细半透明外观,我们学习具有解耦散射特性的神经参与介质。受[Kallweit et al. 2017]和[Zheng et al. 2021]的启发,我们使用单次散射和多次散射分解散射特性。我们提出了一个多级圆锥采样模块来学习与整体几何形状相关的多次散射辐射。我们在第3.4节中详细介绍我们的渲染方法。我们框架的整体流程如图2所示。
3.2 预备知识
神经辐射场(Neural radiance fields)。NeRF[Mildenhall等人,2021]提出使用体渲染方程在不同视角方向下渲染图像。像素的颜色\(C\)对应于给定的光线\(p(t) = o + td\),其中\(o \in \mathbb{R}^3\)表示相机原点,\(d \in \mathbb{S}^2\)表示相机的视角方向。NeRF涉及沿着光线进行积分,积分边界为\(t_n\)和\(t_f\),并使用多层感知器(MLP)来预测渲染方程中的未知值。
\[C = \int_{t_n}^{t_f} T(t)\sigma(p(t))\mathbf{c}(p(t),d)dt \tag{1}\]一个点的体密度\(\sigma\)和辐射度\(\mathbf{c}\)由多层感知器(MLP)建模。体密度用于计算累积透射率\(T(t)\)。
\[T(t) = \exp\left( -\int_{t_n}^{t} \sigma(p(s)) ds \right) \tag{2}\]然后,我们可以计算一个权重函数\(w(t) = T(t)\sigma(p(t))\),用于光线\(p(t)\)上采样点的\(\mathbf{c}\),以计算像素颜色\(C\)。NeRF使用数值积分方法求解这个权重方程:
\[\begin{align} w_j &= \alpha_j \prod_{i = 1}^{j - 1}(1 - \alpha_i) \\ \alpha_j &= 1 - \exp(-\sigma_j \cdot (t_{j + 1} - t_j)) \end{align} \tag{3}\]用于表面重建的NeuS。NeuS[Wang等人,2021]使用隐式神经符号距离函数(SDF)表示物体的表面。它通过在采样点的\(w(t)\)与这些点的SDF值之间建立联系,将体渲染和表面渲染相结合。NeuS将S - 密度定义为\(\phi_s(x) = se^{-sx} / (1 + e^{-sx})^2\),以取代原来的密度,其中\(x\)表示SDF值。在其渲染函数中,使用\(\phi_s\)完成的权重函数在表面交点处达到局部最大值,这符合不透明物体的光学特性。
基于物理的表面渲染
在表面渲染方程中,从视角方向观察到的辐射度被建模为双向反射分布函数(BRDF)和表面点\(x\)处(法向量为\(n\))的辐照度的积分。
\[L_o(x, \omega_o) = \int_{\Omega} L_i(x, \omega_i) f_r(x, \omega_i, \omega_o) (\omega_i \cdot n) d\omega_i \tag{4}\]其中\(L_i(x, \omega_i)\)是从方向\(\omega_i\)入射到\(x\)点的光线。\(f_r\)是BRDF函数,它定义了入射光相对于视角方向\(\omega_o\)的能量分布。
参与介质
参与介质[Cerezo等人,2005]会影响穿过它的光线,而不是像光线穿过干净空气时那样保持不变。当光线穿过参与介质时,参与介质会在光线的每个点上吸收、散射和发射光线。非发射性参与介质中的辐射传输方程定义为:
\[\begin{align} (\omega \cdot \nabla)L(\mathbf{x}, \omega) &= -\sigma_t(\mathbf{x})L(\mathbf{x}, \omega) + \sigma_s(\mathbf{x})L_{\text{st}} \\ L_{\text{st}} &= \int_{S^2} \text{phase}(\mathbf{x}, \omega, \omega') L(\mathbf{x}, \omega') d\omega' \end{align} \tag{5}\]其中\(S^2\)表示位置\(\mathbf{x}\)周围的球形区域,\(L\)表示辐射度,\(\omega\)表示方向。\(\sigma_t\)和\(\sigma_s\)分别表示消光系数和散射系数。辐射度在\(\omega\)方向上的导数表示为\(\omega \cdot \nabla\)。相位函数表示双向能量分布。对于各向同性散射的物体,\(\text{phase}(\mathbf{x}, \omega', \omega) = \frac{1}{4\pi}\)。
3.3 从半透明外观进行表面重建
NeuS仅在不透明物体表面附近优化非零权重,并假设物体内部权重为零,这对于半透明物体是不合适的。一个直接的结果是,物体内部的消光系数没有得到优化,即使考虑均匀材料,其值也可能有很大差异。为了解决NeuS中的这一局限性,我们使用消光系数对物体内部的密度进行建模,使其具有正确的物理特性。以下段落将给出详细解释。
用正确的物理特性对密度建模
在均匀的半透明物体内部,消光系数是一个非零常数,而在物体外部,消光系数为零。也就是说,我们需要为一个方波函数找到一个可微形式,使其在物体内部保持不变,在物体外部等于零。受VolSDF[Yariv等人,2021]的启发,我们使用与符号距离函数(SDF)值相关的拉普拉斯分布函数来表示我们的密度场:
\[\sigma(x)= \begin{cases} \frac{\sigma_t}{2} \exp\left(-\frac{f_G(x)}{\beta}\right) & \text{if } f_G(x) \geq 0 \\ \sigma_t - \frac{\sigma_t}{2} \exp\left(\frac{f_G(x)}{\beta}\right) & \text{if } f_G(x) < 0 \end{cases} \tag{6}\]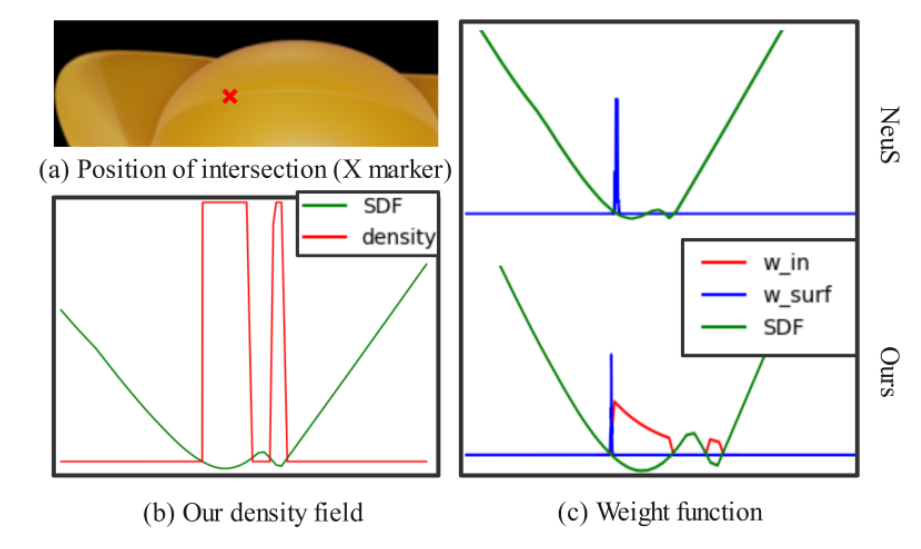
图4. 权重函数和密度值在一条相机光线上的可视化。图(b)展示了物体内部的密度。学习的\(\beta = 2.53e^{-5}\),见公式6。图(c)展示了我们与NeuS的权重函数。注意,NeuS学习的SDF值错误,因为两个表面之间的间隔太小。
其中\(f_G\)是我们的神经隐式SDF,\(f_G(x)\)是点\(x\)的SDF值。\(\sigma_t\)是消光系数的常数值。\(\sigma_t\)越大,半透明度越低,因为光线在物体内部传播时的衰减更高。当\(\beta\)趋近于零时,物体内部点的密度\(\sigma\)收敛到\(\sigma_t\),而外部点的密度设置为0。请注意,公式(6)在半透明物体内部在数学上并不平滑。然而,由于神经渲染方程的离散计算特性,这种误差很小,并且仅在中心附近略有变化,特别是对于接近零的\(\beta\)值。为了具有通用性,我们将\(\sigma_t\)和\(\beta\)设为可学习的参数,并在训练过程中对它们进行优化。图4展示了我们学习到的密度场和\(\beta\)值。
训练过程
图2. 我们几何重建流程(左)和视角合成流程(右)的概述。对于几何重建,我们基于均匀介质中的恒定消光系数提出了另一种权重函数\(w_{in}\)。为了获得更好的半透明物体视觉外观,我们进一步在重建体积中建模散射特性。我们建模了直接光下的镜面颜色\(c_s\)和漫反射颜色\(c_d\),并将间接光下的散射特性分解为单次散射\(L_s\)和多次散射\(L_m\)。我们使用多级圆锥采样学习\(L_m\)的神经表示。我们方法的详细解释见第3.3节和第3.4节。
如图2左侧所示,我们沿着光线从\(t_n\)到\(t_f\)采样\(N_1\)个点。通常,\(n\)代表“近”,\(f\)代表“远”。对于每个点\(p(t)=o + t * d\),其中\(o\)是相机的原始位置,\(d\)是视角方向。这些点被输入到神经SDF网络中,以获得预测的SDF值\(f_G(p(t))\)。我们的目标是从输入图像序列中重建正确的几何形状。然而,大多数半透明物体的外观并非纯粹的透射,还包含表面高光。[Fan等人,2023;Qiu等人,2023]已经证明,分离镜面反射和漫反射分量对重建和渲染是有益的。受他们的启发,我们的框架包含两个分支,分别用于表面颜色\(c\)和物体内部的透射颜色\(c_{in}\)。前者可以进一步通过分离为空间不变颜色\(c_d\)和反射颜色\(c_r\)来估计,其中我们使用[Yariv等人,2020]提出的网络学习\(c_d\),使用[Verbin等人,2022]中的方法学习\(c_r\)。后者需要使用我们的方案进行计算。
\[C = (1 - \gamma)\sum_{t_n}^{t_f} w_{\text{surf}}\mathbf{c}(p(t),d) + \gamma\sum_{t_n^*}^{t_f^*} w_{\text{in}}\mathbf{c}_{\text{in}}(p(t),d) \tag{7}\]渲染颜色由公式(7)给出。\(w_{\text{surf}}\)是NeuS中提出的权重函数。我们添加一个参数\(\gamma\)来平衡这些项。对于从“近”\(t_n^*\)到“远”\(t_f^*\)均匀采样的\(t\),\(w_{\text{in}}\)是根据我们的密度模型公式(6)和公式(3)推导出来的。理论上,具有恒定密度的物体内部点的权重函数与消光系数呈指数关系。
\[w_{\text{in}}(t_i) = (1 - \exp(-\sigma_t \cdot \delta_t))\exp(-\sigma_t \cdot (t_i - t_n^*)) \tag{8}\]其中\(\delta_t = t_{i + 1} - t_i\)。详细的推导过程见附录。为了保证物理合理性,在计算\(w_{\text{in}}\)时,我们将采样区域限制在交点位置\(t_n^*\)和\(t_f^*\)之间的点,这些位置可以按照[Fu等人,2022]中的方法计算。我们将交点集\(\Omega\)定义为:
\[\begin{align} R &= \{t_i \mid f(t_i) \cdot f(t_{i + 1}) < 0\} \\ \Omega &= \left\{t^* \mid t^* = \frac{f(t_i)t_{i + 1} - f(t_{i + 1})t_i}{f(t_i) - f(t_{i + 1})}, t_i \in R\right\} \end{align} \tag{9}\]其中\(f(t_i)\)是\(f_G(p(t_i))\)的简化形式。我们取\(\Omega\)中的最小值和最大值作为\(t_n^*\)和\(t_f^*\)。
在训练过程中,我们将相机光线上点的权重积分限制为1,这表明该光线是否与表面相交。我们在训练过程中使用L1 RGB损失\(L_{\text{rgb}}\)、Eikonal损失\(L_{\text{eik}}\)[Gropp等人,2020]和法向惩罚损失\(L_n\)[Verbin等人,2022]。\(k_1\)、\(k_2\)是用于调整惩罚权重的超参数。
\[\text{Loss} = L_{\text{rgb}} + k_1 \cdot L_{\text{eik}} + k_2 \cdot L_n \tag{10}\]需要注意的是,经过上述优化后,我们能够获得令人满意的半透明物体几何形状。然而,使用公式(7)渲染颜色的直接结果仍然不完美。原因是在这个函数中,我们没有完全捕捉到参与介质内部的散射效应。
3.4 使用恢复的几何进行神经渲染
为了使半透明物体具有更好的视觉外观,我们进一步使用带学习系数的球谐函数,对重建体积中的散射特性进行建模,并从光度图像中联合优化神经材质。为了符合基于物理的渲染,我们将渲染颜色分为直接光下的表面颜色和间接光下的半透明外观。我们使用基于物理的表面渲染方程渲染表面颜色,并使用具有解耦散射特性的神经参与介质渲染半透明外观。我们将在以下段落中分别介绍这些部分。
共置光假设
我们的方案从物理公式(5)开始。从拍摄的图像中学习半透明外观,这对于一般任务来说具有挑战性。其中一个原因是,对于半透明物体,其几何形状和光照复杂性紧密耦合。得益于3.3节中的方法,我们能够从任意光照环境中恢复出良好的几何形状,并且在本节中我们可以认为几何形状是已知的。然而,在未知的任意环境光照下恢复散射特性仍然具有挑战性,因为光线穿过物体内部的路径非常复杂。先前的研究使用已知的光照条件来简化这个问题。例如,像[Zheng等人,2021;Zhu等人,2023]这样的研究在已知光位置的情况下学习散射特性,[Hu等人,2023;Kallweit等人,2017]则专注于平行光。为了限制输入的复杂性,在本节中,我们将共置闪光灯下的光度图像作为输入,这意味着拍摄的物体仅受一束光照射,且该光与视角方向一致。简化后的表面渲染方程定义为:
\[L_o(x, \omega_o) = \frac{I}{\|x - o\|_2^2} f_r(x, \omega_o, \omega_o) (\omega_o \cdot n) \tag{11}\]其中\(L_o\)、\(x\)、\(n\)、\(\omega_o\)、\(f_r\)分别是观测到的光线、表面交点、表面法向量、相机视角方向和双向反射分布函数(BRDF)。入射光表示为强度为\(I\)的白色点光源的衰减。
直接光下的外观
图2. 我们几何重建流程(左)和视角合成流程(右)的概述。对于几何重建,我们基于均匀介质中的恒定消光系数提出了另一种权重函数\(w_{in}\)。为了获得更好的半透明物体视觉外观,我们进一步在重建体积中建模散射特性。我们建模了直接光下的镜面颜色\(c_s\)和漫反射颜色\(c_d\),并将间接光下的散射特性分解为单次散射\(L_s\)和多次散射\(L_m\)。我们使用多级圆锥采样学习\(L_m\)的神经表示。我们方法的详细解释见第3.3节和第3.4节。
如图2右上角所示,我们使用神经材质渲染直接光下的外观。我们将粗糙度\(\alpha\)表示为神经网络\(f_{\alpha}\),将漫反射反照率表示为\(f_a\)。此外,我们使用神经网络\(f_{\text{Tr}}\)来估计未知材质下的光透射率,该网络决定了有多少光能传输到物体内部。对于直接光下的外观,我们使用与IRON[Zhang等人,2022]相同的GGX微面元BRDF函数\(f_r\)来计算镜面反射颜色\(c_s\)和漫反射颜色\(c_d\)。考虑到光的透射,我们将公式(4)中的\(L\)修改为\((1 - \text{Tr})L\)。
使用神经参与介质对半透明外观建模
与[Zheng等人,2021]类似,我们将散射特性分解为单次散射\(L_s\)和多次散射\(L_m\),并学习它们的神经表示。单次散射表示入射光的散射辐射度。对于呈现各向同性散射的均匀材质,单次散射可以按公式(12)计算。
\[L_s(p) = \frac{1}{4\pi} \sigma_s(p(t)) \cdot L_t(n, \omega_i, x)T(x, p) \tag{12}\]其中\(\sigma_s\)是散射系数,\(T\)是从表面点\(x\)到物体内部点\(p\)的透射率。我们使用第一阶段重建的密度场来计算\(T\)。按照[Hu等人,2023]的方法,我们使用一个可学习的常数参数\(\xi\)来表示消光系数与散射系数的比值。由公式(6)可知,我们根据点的位置表示其真实的消光系数。第一阶段学习得到的\(\beta\)足够小,以确保消光系数的不变性,因此该比值可以视为一个常数值。\(L_t\)表示从表面传输的间接光。
\[L_t(n, \omega_i, x) = (1 - F)\text{Tr}(x, n)\frac{I}{\|x - o\|_2^2}(n \cdot \omega_i) \tag{13}\]
图2. 我们几何重建流程(左)和视角合成流程(右)的概述。对于几何重建,我们基于均匀介质中的恒定消光系数提出了另一种权重函数\(w_{in}\)。为了获得更好的半透明物体视觉外观,我们进一步在重建体积中建模散射特性。我们建模了直接光下的镜面颜色\(c_s\)和漫反射颜色\(c_d\),并将间接光下的散射特性分解为单次散射\(L_s\)和多次散射\(L_m\)。我们使用多级圆锥采样学习\(L_m\)的神经表示。我们方法的详细解释见第3.3节和第3.4节。

其中\(F\)是BRDF函数\(f_r\)中的菲涅尔项。多次散射表示入射光在介质内部发生多次散射的情况,可以通过将求解得到的\(L\)递归代入辐射传输方程(RTE)公式(5)的右侧来计算。与单次散射不同,多次散射不仅与单个点相关,还与整体形状有关。多次散射的估计值通常需要对所有追踪路径进行路径追踪和积分计算。[Kallweit等人,2017]的研究提出,可以使用一个以多层采样特征为输入的神经网络来学习多次散射。受他们的启发,我们提出使用从不同采样层级提取的特征来估计多次散射。如图2右下角所示,我们将点光源影响的区域压缩成不同高度和宽度的圆锥体,这对于表示空间区域更为高效。当光发生多次散射时,可达区域会扩大,同时采样层级也应提高。我们的采样区域从黄色区域扩展到蓝色区域,蓝色区域包含更多的点。我们使用[Barron等人,2021]提出的集成位置编码(IPE)作为每个圆锥区域的特征描述符\(z\)。我们将不同采样层级下的编码特征输入到神经网络中,以预测球谐函数系数\(c_l^m\)的权重。我们的锥形采样的详细算法列于算法1中。
然后,我们使用具有\(M\)个采样方向的蒙特卡罗积分来求解多次散射函数中的积分。
\[L_m = \int_{S^2} \frac{1}{4\pi} \sigma_s(p(t)) \cdot \sum_{l = 0}^{l_{max}} \sum_{m = -l}^{l} c_l^m Y_l^m(\omega_i) d\omega_i \tag{14}\]其中\(Y_l^m\)是球谐基函数,\(l_{max}\)是最大带宽。注意,我们按照[Zheng等人,2021]中的方法,使用数值积分方法求解RTE渲染方程,如公式(15)所示。
\[c_t = \sum_{j = 1}^{N_2} T(x_1, p(t)) (1 - \exp(-\sigma_t(p(t))\delta t)) (L_s + L_m) \tag{15}\]其中\(p(t) = x + t * d\),\(x\)定义为表面的第一个交点。我们不使用公式(9)来计算交点,而是使用球体追踪算法来提高准确性。我们至少可以找到两个交点,\(x_2\)是最远的那个。我们使用\(x\)和\(x_2\)的距离来计算\(t\):\(\delta t = \frac{\|x_2 - x\|_2}{N_2}\),\(t_j = j * \delta t\)。
训练过程
我们将直接光下的外观和间接光下的半透明外观结合起来作为渲染结果:\(C = c_s + c_d + c_t\)。我们使用L1 RGB损失\(L_{\text{rgb}}\)来优化\(\sigma_s\)、\(L\)、\(\alpha\)、\(\text{Tr}\)、漫反射反照率以及球谐函数的系数。为了降低复杂度,我们设\(\xi\)等于漫反射反照率。此外,我们对\(x\)和\(x_2\)添加Eikonal损失,以微调学习到的神经SDF网络,这能确保表面交点的法向量准确。我们加入[Yao等人,2022]中提出的双边平滑损失,以避免\(\alpha\)变化过快。\(k_3\)、\(k_4\)是超参数。
\[\text{Loss} = L_{\text{rgb}} + k_3 \cdot L_{\text{eik}} + k_4 \cdot L_{\text{smoothness}} \tag{16}\]4 实验
4.1 实现细节
我们按照NeuS[Wang等人,2021]的方法来表示物体的几何形状:\(f_G : x \to (\mathcal{F}, f_G(x))\)。我们的神经SDF网络的输出由一个256维的几何特征描述符\(\mathcal{F}\)和一个SDF值\(f_G(x)\)组成。几何特征\(\mathcal{F}\)、SDF网络的梯度\(\nabla f_G(x)\)以及点\(p\)被输入到颜色网络中以预测\(c\)。我们通过\(n = \nabla f_G(x)/\|\nabla f_G(x)\|\)来获取法向量\(n\)。
在我们的框架中,表面颜色\(c\)由空间不变颜色\(c_d\)和反射颜色\(c_r\)组成。按照[Verbin等人,2022]的方法,我们通过\(c = c_d + \text{tint} * c_r\)来计算\(c\)。\(c_d\)是使用[Yariv等人,2020]中相同的MLP结构进行预测的,该结构将位置和几何特征描述符作为输入。\(\text{tint}\)是一个介于0和1之间的参数,用于确定反射光的强度。\(c_r\)是使用[Verbin等人,2022]中的方法进行预测的,该方法将计算出的反射方向\(\dot{d}\)、位置和几何特征描述符作为输入。
在表面重建阶段,我们对模型进行10万次迭代训练,每一步采样1024条相机光线。我们均匀采样64个点来计算\(w_{\text{surf}}\),采样32个点来计算\(w_{\text{in}}\)。我们采用Adam优化器[Kingma和Ba,2014],其中\(\beta_1 = 0.9\),\(\beta_2 = 0.999\),并将初始学习率设置为0.0005。参数\(\gamma\)初始设置为0.5。\(k_1\)、\(k_2\)分别设置为0.1和0.005。使用单个NVIDIA GeForce RTX 3090 GPU时,整体训练时间约为8小时。
在渲染阶段,我们将粗糙度\(\alpha\)表示为一个神经网络:\(f_{\alpha} : (x, n, \mathcal{F}) \to \alpha \in R\)。漫反射反照率通过神经网络\(f_a : (x, n, \mathcal{F}) \to \text{反照率} \in R^3\)进行预测。透射反照率通过神经网络\(f_{\text{Tr}} : (x, n) \to \text{Tr} \in R\)进行预测。我们对模型进行8万次迭代训练,每一步采样128×128条相机光线。缩放因子\(\lambda\)设置为0.5,\(r_0\)设置为世界坐标中像素的宽度,\(h_0\)设置为相邻采样点的间隔,其中\(M\)等于64,\(N\)等于32。\(k_3\)、\(k_4\)分别设置为0.1和0.05。
4.2 数据集
针对“Syn-Trans”数据集
我们选择6个不同的物体,来创建具有不同半透明材质的合成场景,包括“小熊软糖”、“斯坦福龙”、“元宝”、“远古龙”、“指甲”和“果汁”。我们使用Blender中的PrincipleBSDF着色器来模拟现实世界中的材质,如玉石、软糖、果汁和塑料。每个场景和材质的详细信息见附录。我们在球体或半球体上均匀采样90 - 120个视角,以渲染分辨率为800×800的训练图像。
针对“Real-Trans”数据集
我们将半透明物体放置在自动旋转平台的中心,并在暗室中拍摄约40秒的视频。我们从视频中每10帧提取1帧用于训练,并使用COLMAP[Schonberger和Frahm,2016]估计相机位姿。我们从视频中每20帧提取1帧来测试视图合成的结果。对于一些具有复杂光学特性的半透明物体,我们添加一个不透明物体用于相机位姿估计。每个真实场景使用大约100张来自圆形轨迹的图像,图像分辨率为960×540像素 。
4.3 几何评估
表2. Syn-Trans数据集上重建评估结果的倒角距离(CD ↓)。我们比较了使用神经隐式SDF网络的最先进重建方法:NeuS[Wang et al. 2021]、HFNeuS[Wang et al. 2022]、Ref-NeuS[Ge et al. 2023]。加粗文本表示最佳评估结果,下划线文本表示次佳结果。

图3. 重建结果。我们在提出的”Syn-Trans”数据集上比较了使用隐式神经SDF的重建方法:NeuS[Wang et al. 2021]、HF-NeuS[Wang et al. 2022]、Ref-NeuS[Ge et al. 2023]的结果。
图4. 权重函数和密度值在一条相机光线上的可视化。图(b)展示了物体内部的密度。学习的\(\beta = 2.53e^{-5}\),见公式6。图(c)展示了我们与NeuS的权重函数。注意,NeuS学习的SDF值错误,因为两个表面之间的间隔太小。
为了从学习到的神经符号距离函数(SDF)网络中导出网格,我们在一个固定的正方形空间(从 -1 到 1)内进行网格采样,使用SDF网络对每个采样点进行预测,并使用移动立方体算法(Marching - Cubes algorithm)获得重建的网格。我们在“Syn - Trans”数据集下,使用真实网格和重建网格之间的 Chamfer 距离(CD)来评估几何重建结果。定量比较结果见表2,定性比较结果见图3。NeuS 由于来自远离前表面点的不可忽略的颜色偏差,无法重建出准确的表面。HF - NeuS 将半透明外观视为几何的高频细节,这导致表面有噪声且不光滑。Ref - NeuS 利用了拍摄图像中的反射高光,但预测的形状不准确,尤其是在凹面上。相比之下,我们的方法表现最佳,这得益于对物体内部点密度进行建模的恰当方法,以及训练过程中修正后的渲染函数。为了评估我们从多视图图像中学习到的密度场和权重函数,我们在图4中展示了学习到的密度值、SDF值和采样点的权重。在这个场景中学习到的\(\beta\)为\(2.53e - 5\),这个值足够小,以确保内部密度的不变性。图(b)中所示的内部点的密度,适用于均匀物体的恒定消光系数。因此,图(c)中红线所示的内部点的权重,在远离表面点时逐渐下降。整体曲线相对于到表面的距离接近一个指数函数,这在附录中有理论分析。NeuS 忽略了这些点的权重,并且在他们的图中,第二个相交平面的权重接近于零,这是错误的,因为我们可以在左上角图中的标记点处看到第二个相交平面的颜色。
自然场景的结果
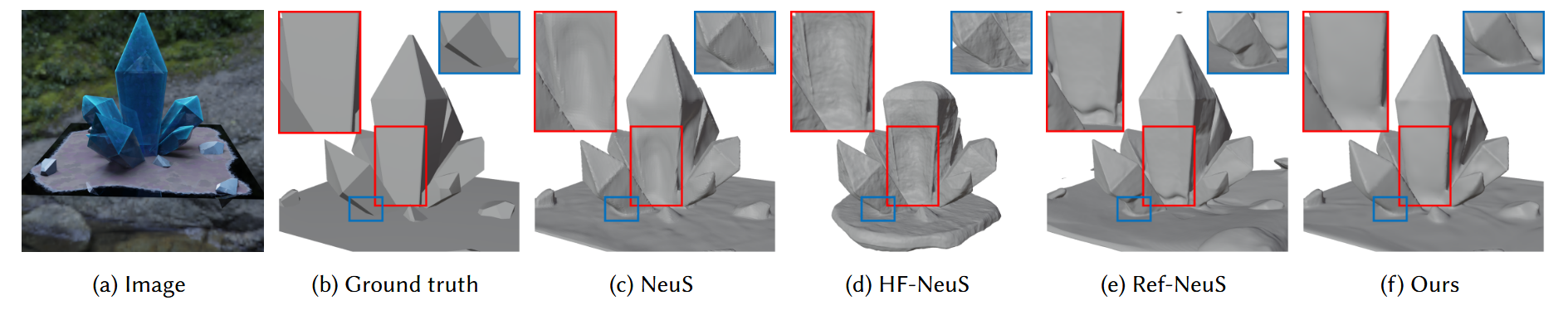
图6. 自然场景中的重建结果。该场景具有环境光照,与共置闪光灯设置不同。
3.3节中的方法能够从任意光照条件下进行重建,而不仅限于共置闪光灯。我们在图6中展示了在有环境光的自然场景下的重建结果。
“Real-Trans”数据集的结果
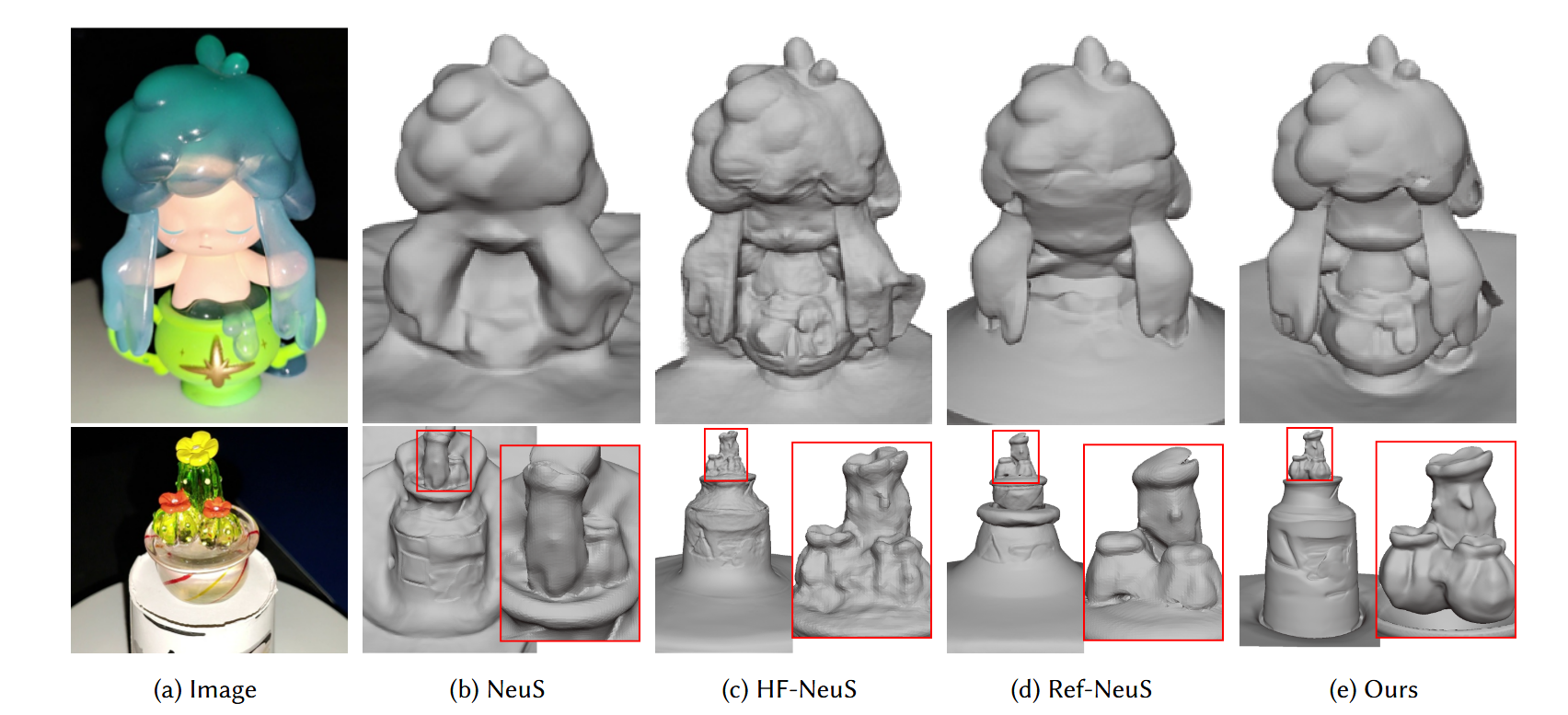
图5. 真实场景中的重建结果。我们在”Real-Trans”数据集上评估了重建结果。注意,最后一行的结果中,NeuS未能恢复完整形状,因此我们在另一个视角中展示了他们的结果。
我们在图5中展示了真实场景的重建结果。在我们的“Real-Trans”数据集中没有真实的几何数据,所以我们跳过了度量比较。对于物体的不透明或接近不透明的部分,与合成场景相比,Ref-NeuS的重建性能存在显著差异。Ref-NeuS中的方法与计算反射所需的准确输入视角方向高度相关。在真实场景中,很难预测准确的相机位姿。不准确的视角方向导致他们的结果中出现错误的表面。
4.4 视图合成评估
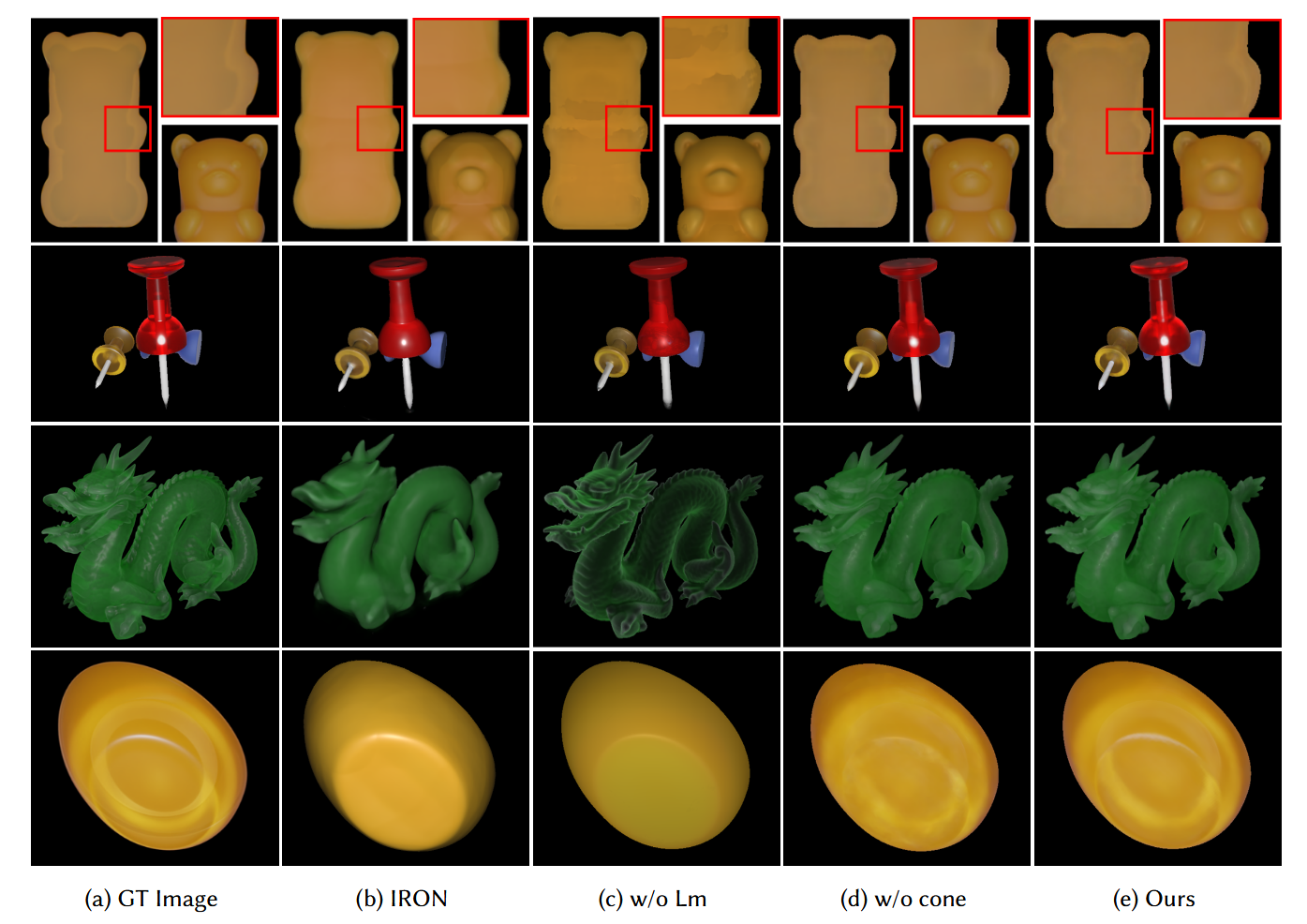
图7. “Syn-Trans”中新视角的渲染结果。列(c)和(d)是消融方法的结果。
表3. 新共置闪光灯视角下渲染结果的定量比较。我们比较了IRON [Zhang et al. 2022]中的逆渲染方法与我们的方法,使用PSNR ↑、LPIPS ↓和SSIM ↑从光度图像中评估。

图8. 新视角渲染的可视化。
为了评估我们的神经渲染阶段,我们在图7中展示了新视图的定性结果。在表3的定量比较中,我们在相同光照条件下,将峰值信噪比(PSNR)、学习感知图像块相似度(LPIPS)[Zhang等人,2018]和结构相似性指数(SSIM)[Schonberger和Frahm,2016]与真实结果进行了比较。IRON[Zhang等人,2022]在第一阶段依赖NeuS的流程来重建几何形状,在第二阶段分解材质。由于IRON的渲染方程中忽略了半透明外观,且几何形状不准确,其渲染结果没有透明度。我们的方法图像指标较高,这得益于正确重建的几何形状和学习到的散射特性。需要注意的是,IRON无法恢复“远古龙”的几何形状,所以他们的渲染结果只有黑色背景。在图8中,我们展示了与IRON相比,我们在真实场景上的视图合成结果。
4.5 消融研究
为渲染建模散射特性
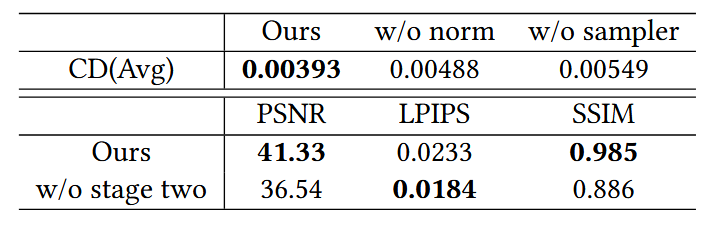
表4. 消融研究中的实验结果。第一个表是倒角距离的平均结果。第二个表是图像指标的平均结果。
我们使用公式(7)得到渲染结果,该公式也可用于新视图合成。然而,此公式中忽略了散射特性。因此,学习到的透射颜色包含噪声,新视图渲染图像的质量较低。我们在表4第二行报告了定量比较的平均结果。术语“第二阶段”表示3.4节中的神经渲染方法。除了“指甲”场景外,我们实验中的LPIPS分数几乎相同。使用公式(7)渲染图像的LPIPS值为0.0068,而对比值为0.0217。这是我们方法在优化薄区域中与表面交点相关参数时的一个局限。
\(w_{\text{in}}\)的计算
表4. 消融研究中的实验结果。第一个表是倒角距离的平均结果。第二个表是图像指标的平均结果。
散射特性仅存在于物体内部的点,所以我们将采样区域限制在物体内部。我们将我们的采样方法作为一种重要性采样,以保留内部点和外部点的清晰边界。此外,我们将所有采样点的\(w_{\text{in}}\)之和限制为1,这样经过\(\gamma\)平衡后的\(w_{\text{surf}}\)和\(w_{\text{in}}\)的积分等于1,这对于判断光线是否与表面相交很有用。我们对权重\(\frac{w_{\text{in}}}{\sum w_{\text{in}}}\)进行归一化。我们在表4中展示了关于是否使用我们的采样方法和归一化的消融实验结果。
多次散射和多层锥形采样
图7. “Syn-Trans”中新视角的渲染结果。列(c)和(d)是消融方法的结果。
表3. 新共置闪光灯视角下渲染结果的定量比较。我们比较了IRON [Zhang et al. 2022]中的逆渲染方法与我们的方法,使用PSNR ↑、LPIPS ↓和SSIM ↑从光度图像中评估。
[Zheng等人,2021]中的方法首次提出使用球谐函数(SH)来求解多次散射。在他们的方法中,\(c_l^m\)是使用多层感知器(MLP)预测的,该MLP将点的位置编码和视角方向作为输入,而不考虑多层采样的空间信息。由于他们的方法无法重建几何形状,我们将与他们方法的比较作为一个消融实验。我们将他们的方法实现为“w/o cone”,即去除我们方法中的锥形采样模块。此外,为了评估学习到的多次散射特性的效果,我们设计了一个消融实验“w/o Lm”,表示在最终渲染方程中忽略\(L_m\)。渲染结果和指标比较见图7和表3。当半透明外观复杂且与未见过区域的几何形状高度相关时,我们的方法显著改善了渲染结果。
5 结论
在本文中,我们提出了一种用于半透明物体的高保真表面重建和新视图合成的全新框架。我们的框架包含两个阶段。首先,我们使用神经隐式符号距离函数(SDF)重建半透明物体的表面。我们使用估计的恒定消光系数对物体内部的密度场进行重新参数化。与NeuS中提出的“S - 密度”不同,我们的密度场在物体内部保持均匀性,这符合均匀物体的物理特性。此外,为了在新视图下获得更好的渲染结果,我们利用学习到的几何形状,并使用参与介质的神经表示来学习半透明外观。我们提出了一种多层锥形采样方法,以学习与整体几何形状相关的复杂半透明外观。为了评估我们的方法,我们创建了一个包含真实世界半透明物体和合成半透明物体的数据集。
局限性

图9. 真实场景中的失败案例:”cactus2”
在我们的重建和渲染方法中,都忽略了折射现象,而这对于像玻璃这样的高透明物体至关重要。如图9所示,我们的方法无法获得可靠的几何形状和合理的渲染结果。我们将此类场景的改进作为未来的工作。3.4节中优化参数的方法在物体的薄区域会导致较差的渲染结果。在更一般的场景中,需要明确对\(\xi\)的不变性进行约束。此外,通过训练学习到的散射特性受到所用视角和共置光照条件的限制。在训练视图不足的情况下,我们学习到的散射特性在新视图合成中的表现较差,尤其是在真实场景中。我们将更通用的散射特性建模留作未来的工作。
A 附录
A.1 公式推导
我们在本节分析恒定密度场的理论权重函数。回顾一下,我们使用公式(3)求解体渲染方程。假设物体内部点的密度是恒定的,所以我们用\(\sigma_t\)表示这个常数值:\(\alpha_j = 1 - \exp(-\sigma_t \cdot \delta_j)\)。将此公式代入权重函数,我们得到物体内部点的权重函数。
\[w_j = \alpha_j \prod_{i = 1}^{j - 1}(1 - \alpha_i) = (1 - \exp(-\sigma_t \cdot \delta_j)) \cdot \exp(-\sigma_t \cdot (t_j - t_1)) \tag{17}\]对于均匀采样的点,所有\(j\)对应的\(\delta_j\)都相等,所以我们可以将这个公式简化为:
\[w_j = (1 - \exp(-\sigma_t \cdot \delta_t)) \cdot \exp(-\sigma_t \cdot \delta_t \cdot (j - 1)) \tag{18}\]其中\(\delta_t = (t_f - t_n)/N\)。\(t_n\)、\(t_f\)在神经辐射场(NeRF)中分别表示近点和远点。\(N\)是采样点的数量。对于一条相机光线,\(\delta_t\)是固定的。我们假设\(\sigma_t\)是常数,所以\(\sigma_t \cdot \delta_t\)可以视为一个常数值。
A.2 额外实验
与VolSDF的比较
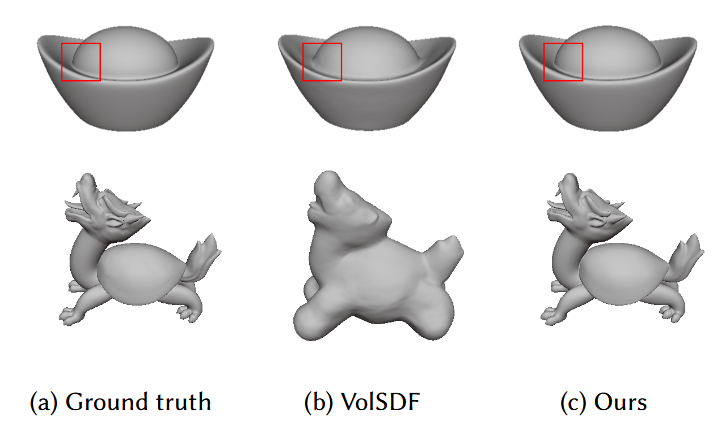
图10. 与VolSDF的重建结果比较。
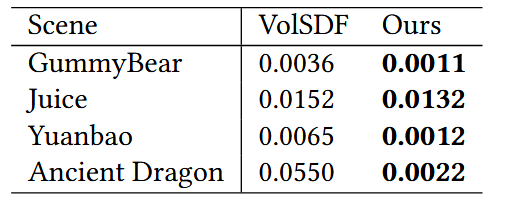
表6. 重建评估结果。
与VolSDF[Yariv等人,2021]的几何重建比较结果如图10和表6所示。未列出的场景是VolSDF未能重建的场景。
与专门为半透明物体设计的方法的比较

图11. [Deng et al. 2022]中的方法”InvTranslucent”未能恢复几何形状。
对于[Deng等人,2022]中的方法,他们利用可微的双向表面散射反射分布函数(BSSRDF)路径追踪来重建半透明物体。然而,他们的重建在很大程度上需要合适的几何初始化,并且他们论文中示例的几何拓扑相对简单。他们假设渲染模型符合BSSRDF,但这与我们的数据集不相符。此外,他们方法中使用的GPU内存过大,所以在这个实验中,我们将数据集中的图像分辨率降低到256×256(原论文中使用的是512×512)。他们在“小熊软糖”场景上的重建结果如图11所示。
A.3 数据集细节
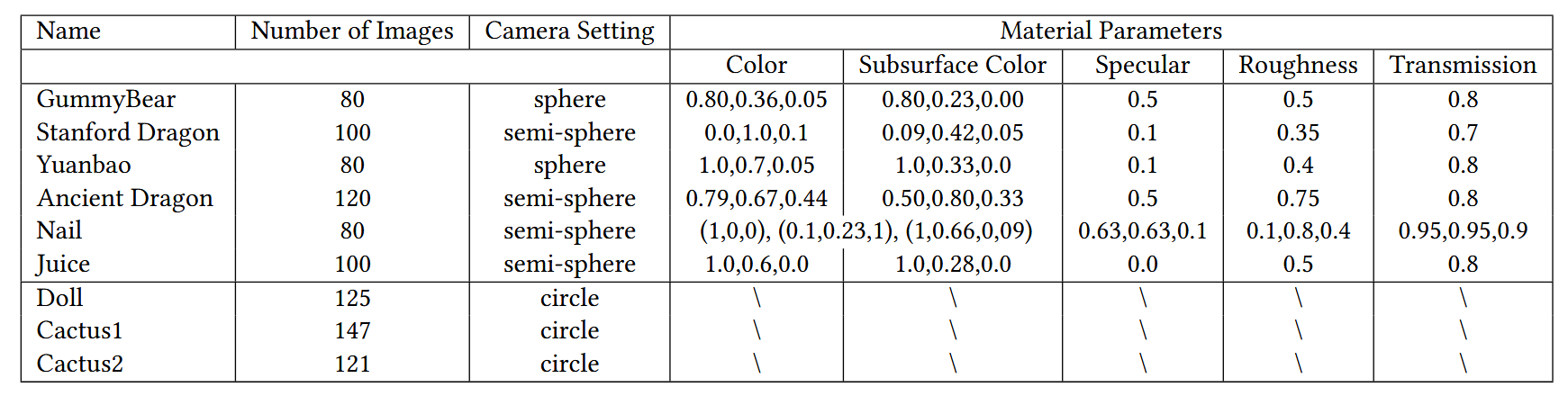
表5. 我们合成数据集中的详细相机设置、图像和材质。
我们数据集的详细信息可在表5中找到。相机设置表示相机的采样区域。“Sphere”表示在单位球体上对相机进行采样,而“semi - sphere”表示仅在球体的上表面进行采样。对于材质,我们使用Blender中的PrincipleBSDF着色器,它是Disney BSDF[Burley,2015]的一种实现。“Color”和“Subsurface Color”的值是浮点格式的RGB值。省略的参数,如金属度、光泽度和清漆值均为零。除了包含玻璃杯的“果汁”场景外,所有场景的折射率(IOR)都设置为1.3。“指甲”场景中的参数分别对应三个物体,并且此场景未设置“Subsurface Color”。
评论