对话式搜索综述
作者: Fengran Mo1∗, Kelong Mao2∗, Ziliang Zhao2, Hongjin Qian2, Haonan Chen2, Yiruo Cheng2, Xiaoxi Li2, Yutao Zhu2, Zhicheng Dou2, Jian-Yun Nie1
单位: 1蒙特利尔大学, 加拿大;2中国人民大学
摘要:作为现代信息获取的基石,搜索引擎已成为日常生活中不可或缺的工具。随着人工智能(AI)和自然语言处理(NLP)技术的快速发展,特别是大语言模型(LLMs)的进步,搜索引擎已经能够支持更直观和智能的用户与系统交互。对话式搜索作为下一代搜索引擎的新兴范式,利用自然语言对话促进复杂且精确的信息检索,因此吸引了广泛关注。与传统的基于关键词的搜索引擎不同,对话式搜索系统通过支持复杂查询、在多轮交互中维护上下文以及提供强大的信息集成和处理能力,显著提升了用户体验。查询重构、搜索澄清、对话式检索和响应生成等关键组件协同工作,实现了这些复杂的交互。在本综述中,我们探讨了对话式搜索的最新进展和未来潜在方向,分析了构成对话式搜索系统的关键模块。我们强调了LLMs在增强这些系统中的作用,并讨论了这一动态领域面临的挑战和机遇。此外,我们还提供了对当前对话式搜索系统的实际应用和稳健评估的见解,旨在为对话式搜索的未来研究和开发提供指导。
关键词: 对话式搜索;查询重构;搜索澄清;对话式检索与生成
1 引言
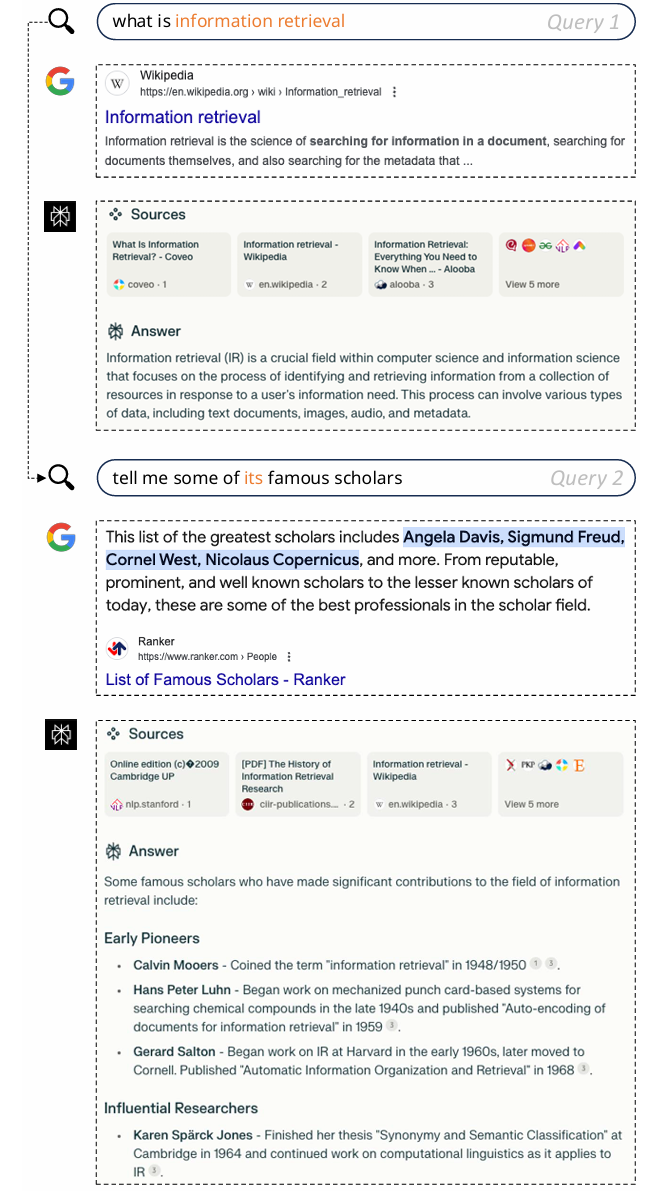
图1. 传统搜索引擎Google与新型对话式搜索引擎Perplexity.ai的对比。第二个查询中的“its”指代第一个查询中的“information retrieval”。然而,传统搜索引擎难以理解用户查询中的此类省略。
搜索引擎已成为现代社会不可或缺的一部分,作为满足用户信息需求的重要工具。人工智能(AI)的进步显著加速了其发展[1]。近年来,随着自然语言处理(NLP)技术的快速发展,特别是大语言模型(LLMs)的出现[2],搜索引擎已经演变为提供更智能和交互式的用户体验。在这一领域中,对话式搜索是一个显著的进步,作为一种新兴范式,它通过自然语言交互实现复杂且准确的信息获取。商业化的对话式AI搜索引擎,如Perplexity.ai和SearchGPT,已经投入使用,迅速吸引了大量用户并保持显著增长。与依赖关键词或短语的传统搜索引擎相比,对话式搜索利用自然语言对话进行交互[3–7],极大地提高了信息交换的效率并优化了用户体验。这种方法支持更复杂的用户查询,管理更长且更复杂的历史上下文,并提供全面的信息集成和处理能力。此外,对话式搜索支持多样化的信息传递方式,并具备与用户进行主动交互的能力[8–10]。例如,这些系统可以主动提出澄清问题[11–13]、提供推荐[14],并通过对话引导用户更好地表达需求。图1展示了传统搜索与对话式搜索的区别。在这个真实示例中,像Google这样的传统搜索引擎无法在查询之间维护上下文。当用户查询“什么是信息检索”后,接着询问“告诉我一些著名的学者”时,搜索引擎提供了不相关的结果,因为它没有识别出用户仍在指代“信息检索领域的学者”。相比之下,对话式搜索引擎Perplexity.ai通过保留上下文成功处理了多轮查询,正确解释了后续问题,并提供了关于信息检索领域著名学者的准确信息。
一个典型的对话式搜索系统由多个关键模块组成,每个模块涉及多种先进技术。随着这一领域的不断发展,它既带来了显著的机遇,也提出了挑战。在本综述中,我们将按照整个信息流的顺序,探讨和分析构成对话式搜索系统的关键组件,重点关注查询重构、搜索澄清、对话式检索和响应生成。这些组件协同工作,使用户与系统之间的交互更加自然和直观,从而提升整体搜索体验。
查询重构:查询重构是对话式搜索系统和传统搜索引擎中至关重要的初始步骤。它涉及多种技术,如查询扩展[15, 16]、重写[7, 17]和查询分解[18],以重构查询,从而提升后续系统模块的性能。在对话式搜索的背景下,准确解释用户的当前信息需求尤为重要,因为它必须基于正在进行的对话的上下文。随着对话的推进,这种上下文可能变得越来越复杂和冗长,这对传统搜索引擎提出了挑战,因为它们通常难以处理这种多轮输入。因此,查询重构在将整个对话上下文与当前查询提炼为用户当前信息需求的简洁而全面的表示中发挥着关键作用。这一过程确保后续组件能够更有效地处理和响应用户查询。
搜索澄清:搜索澄清是对话式搜索系统中的另一个关键组件。它使用户能够通过交互式对话优化其搜索查询,涵盖诸如信息查询、任务执行或网站导航等场景[19–21]。用户通常以模糊或多面的方式表达其搜索意图。为了提高理解,系统可以提出澄清问题,例如“您是指[特定术语]吗?”或“您能提供更多关于[主题]的细节吗?”,而不是直接回答查询。当系统检测到需要澄清时,它会主动提出这些问题以更好地理解用户的意图。这种方法确保系统提供更准确和相关的搜索结果,通过使搜索过程更加个性化和有效来提升整体用户体验。搜索澄清中的主要挑战包括准确且高效地识别何时需要澄清以及生成适当的澄清问题。
对话式检索
在查询和上下文被重构且必要的澄清完成后,系统继续从外部知识库中检索相关信息以满足用户的信息需求。与传统的即席检索不同,对话式检索面临一个独特的挑战,即在复杂的多轮对话上下文中从庞大的知识库中提取有用的知识片段。这一过程要求系统有效管理多轮交互的复杂性和较长的上下文长度,以确保检索到最相关的信息,从而为用户提供准确且有用的响应[22]。一种直接的方法是利用先前重构的对话式查询进行检索[5, 7]。然而,这种方法可能会失败,因为上游的查询重写器通常难以基于下游的检索信号进行优化。此外,随着上下文变长且用户信息需求变得更加复杂,生成简洁而有效的查询重写变得越来越困难。解决这一问题的一个新兴且有前景的方法是对话式密集检索,它通过训练一个会话编码器直接对整个上下文进行编码[23–27]。通过避免显式的查询重写,这种方法可以利用排序信号进行直接优化,从而可能实现更优的性能。然而,由于编码整个上下文的复杂性,训练一个高效的对话式密集检索器仍然具有挑战性。此外,与传统搜索引擎类似,对话式搜索系统需要在复杂的上下文中更精确地对检索到的内容进行重排序[28]。这一重排序过程至关重要,因为它确保后续的响应生成模块能够访问最相关的内容,从而生成更准确和有用的响应。
响应生成
下一代对话式搜索系统与传统搜索引擎的一个关键区别在于其能够提供不仅仅是链接列表的响应。对话式搜索系统可以根据用户需求定制响应,提供各种输出格式,如直接且简洁的答案、摘要内容[29],甚至结构化数据(如表格)[30]。在对话式检索和重排序阶段之后,系统尝试将检索到的信息与上下文对话结合,生成精确且相关的响应。然而,这一生成过程仍面临许多挑战,包括确定呈现内容的适当格式、优化模型保真度以有效利用检索到的知识、管理内部与外部知识源之间的冲突、处理生成过程中极长的上下文信息[31],以及提供准确的引用标签以便于来源验证[32]。解决这些挑战对于提升对话式搜索系统的有效性和可靠性同样重要。
核心模块与领域应用
查询重构、搜索澄清、对话式检索和响应生成这四个关键组件构成了通用对话式搜索系统的基础框架。除了这些核心元素外,此类系统已成功应用于医疗[33–42]、金融[43–48]和法律[49–52]等专业领域,并根据特定用户需求和上下文要求进行定制。这些应用涵盖了从利用先进语言模型的个性化医疗咨询[33]到帮助投资者驾驭复杂市场数据的直观财务咨询服务[46]等多个领域。在法律领域,对话式搜索系统促进了高效案例检索并支持细致的法律推理[49]。此外,在这些专业领域之外,对话式搜索系统通过实现个性化产品推荐和响应式客户服务交互,增强了电子商务平台的功能[53]。这些多样化应用突显了对话式搜索在应对当代信息检索挑战中的适应性和日益增长的重要性。
总结与未来方向
本综述旨在回顾构建对话式搜索系统所涉及的关键技术组件,并探讨其实际应用。我们将分析查询重构、澄清、对话式检索、响应生成以及领域特定应用,以理解这些模块如何协同工作,创造更自然和智能的用户交互。此外,我们将总结可用资源和评估协议,以促进该领域的进一步研究。我们的目标是为研究人员和工程师提供关于对话式搜索挑战与机遇的全面概述。本文将在每个阶段展示技术挑战,探讨当前解决方案,并概述未来方向,以鼓励这一新兴领域的进一步创新和发展。
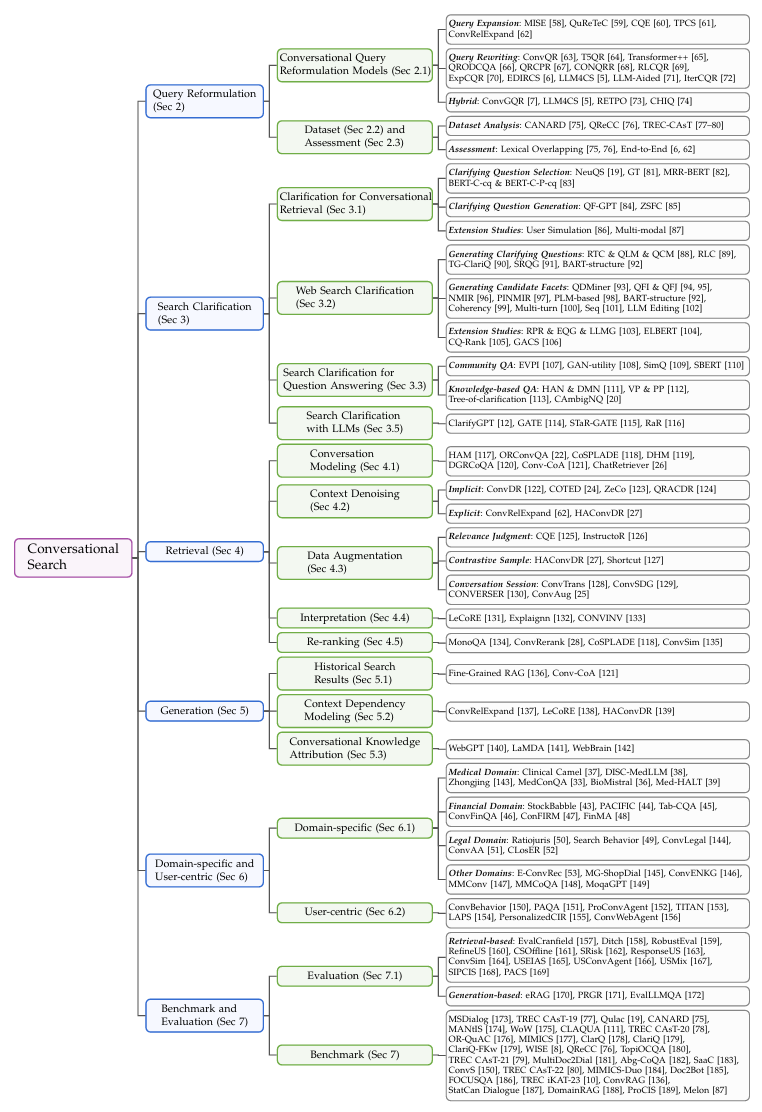
图3. 对话式搜索系统的结构化分类法,对现有研究进行分类。
本文与以往关于对话式搜索的综述[54–57]有两点显著不同。首先,早期的综述在ChatGPT2出现之前进行,主要关注没有LLMs的传统方法。LLMs彻底改变了该领域的技术和应用场景,推动了实际商业对话式搜索引擎的发展。我们的综述结合了最新的LLM技术,并讨论了相关的新挑战和机遇。其次,我们的综述采用了更系统化的方法。我们从对话式搜索引擎的信息流视角构建了综述,特别关注四个关键模块(即查询重构、澄清、对话式检索和对话式响应生成)。图3展示了对话式搜索的广泛概述,并使用结构化分类法对现有研究进行了分类。
本综述的剩余部分组织如下:第2、3、4、5节分别从查询重构、澄清、对话式检索和对话式响应生成的角度回顾进展和关键问题,这些是对话式搜索系统的四个关键组件。随后,第6节介绍了在特定领域和以用户为中心的场景中进行的开创性对话式搜索研究。第7节总结了可用的基准,并讨论了改进对话式搜索系统的评估协议。最后,我们在第8节总结了本综述,并讨论了几个潜在的未来方向。
2 查询重构
查询重构是信息检索领域中广泛使用的一种技术[190, 191],其目的是通过重新表述用户初始搜索查询来改进搜索结果。这是因为输入的查询通常是模糊的、歧义的或不完整的,系统需要揭示用户的搜索意图以更好地满足信息需求。基于各种重构技术,如查询扩展、查询重写和术语替换,搜索系统可以获得更相关和准确的结果[192, 193]。
2.1 对话式搜索中的查询重构

图4. 对话式搜索中Anaphora和Ellipsis语义现象的示例。查询重构在解决这些语义鸿沟中起着关键作用。
在对话式搜索中,查询重构至关重要,因为用户意图的复杂性通常隐藏在后续问题中,导致依赖于上下文的查询[77, 78, 80]。与传统的信息检索不同,对话式搜索必须解决两个关键的语义现象:指代(Anaphora)和省略(Ellipsis)[65, 70]。指代涉及语义依赖于先前上下文的表达式,而省略则指从先前上下文中理解的语义元素的省略。这些现象要求当前查询与先前的历史上下文(例如,查询-答案对)在语义上相关联,因此上下文跟踪对于准确响应至关重要。图4展示了对话式搜索中的查询重构案例。自适应技术[75]需要根据对话历史解析引用并填补省略的信息。因此,有效的查询重构必须是动态的且具有上下文感知能力,能够持续适应不断变化的对话。从文献中,现有方法可以分为三类:1) 查询扩展,2) 查询重写,3) 混合方法,具体介绍如下。
2.1.1 查询扩展
由于缺乏查询重构的标注数据,早期的工作借鉴了传统信息检索(IR)中的查询扩展思想[194],从不同的资源中扩展当前查询轮次。可以通过多种方式实现查询扩展,包括相关术语分类、启发式技术等。相关术语分类将查询重构转化为一个二分类任务,其中查询上下文中的术语被标记为相关或不相关。相关术语随后被附加到原始查询中作为扩展。这种方法系统地整合了重要术语,从而提高了检索性能。例如,Kumar等人[58]开发了一种带有弱监督信号的二分类器,从对话历史中选择相关术语,并使用伪相关反馈(PRF)来解构对话式查询。Voskarides等人[59]提出了基于远程监督的QuReTeC,其伪标签可以直接从用户-系统交互中推断出来。Lin等人[60, 195]在查询重构过程中估计术语的重要性,评估上下文中不同术语的显著性,确保在重构的查询中保留或强调最关键术语。此外,启发式方法侧重于利用语言特征来重构查询,通过词性标注、依存句法分析和共指消解等技术,识别语法结构并解析对先前上下文的引用,从而重构原始查询。通过利用句法和语义分析,这些方法[59, 61]增强了重构查询的清晰度和上下文相关性,从而改进了搜索结果。总体而言,查询扩展方法在不依赖人工标注进行模型训练的情况下,显著提升了对话式搜索的效果。然而,一个尚未解决的挑战是如何区分扩展术语的有用性[196, 197],即通过语言建模概率或启发式规则生成的伪监督信号可能无法保证搜索的有效性。为了缓解这一问题,Mo等人[62]将对话式查询重构视为基于直接搜索影响生成的伪标签的轮次级扩展任务,从历史中选择相关轮次以扩展原始查询。未来可以借助现有的大型语言模型(LLMs)进行更多探索,例如从LLM的生成结果中扩展查询。
2.1.2 查询重写
查询重写是一种将依赖于上下文的查询转化为基于先前对话上下文的独立查询的基本方法,该方法在早期研究中已被应用,并随着LLM的进步不断发展。在早期研究中,Yu等人[63]提出了一种基于规则的查询简化方法,生成远程监督数据以训练查询生成模型。Lin等人[64]采用序列到序列架构模型作为默认原则,模拟人工重写的查询,后续的一些研究[65–67]进一步改进了查询重写结果。然而,这些方法高度依赖于人工标注的质量来训练重写模型,这可能会限制对话式搜索性能的上限。Wu等人[68]首次证明人工标注的重写查询未必是最佳的搜索查询。为此,一些工作[68, 69]采用强化学习,将检索改进作为奖励信号,直接优化重写模型训练以面向下游搜索任务。此外,其他研究[6, 70]利用基于编辑的方法,通过注入排序信号执行显式查询重写。受LLM在长上下文理解和文本生成方面的强大能力启发,Mao等人[5]首次将LLM用作搜索意图解释器,帮助对话式搜索并通过融合多提示结果提升性能。Ye等人[71]通过多阶段生成实现信息丰富的查询重写。为了避免直接调用LLM进行查询重写和人工标注的高成本,Jang等人[72]通过ChatGPT初始化每个查询轮次的训练目标,并设计了一种迭代机制,根据排序结果改进生成的查询。总体而言,查询重写技术有助于解决对话式搜索中查询的模糊性问题。主要挑战在于优化查询重写模型以面向搜索结果,并与基于自然语言的检索器对齐。
2.1.3 混合方法
查询扩展和查询重写方法在对话场景下的查询重构中产生不同的效果。查询扩展旨在为查询添加补充信息,而重写则倾向于处理模糊查询并添加缺失的标记。这两种效果都很重要,但它们通常被分开研究。为了继承它们的优点,Mo等人[7]提出了ConvGQR,这是一种新的对话式查询重构框架,通过结合重写结果和从语言模型生成的答案作为扩展。其假设是,存储的知识使语言模型能够生成与相关文档中的真实答案共现的语义相似答案,从而促进搜索过程。这一原则在LLM时代被广泛使用[15]。由于LLM通过更多的参数化知识获得了更强大的问答能力,生成的答案与重写查询一起成为重要的扩展部分,形成最终查询[5, 73]。此外,Mo等人[74]设计了一种两步方法,利用LLM的不同能力来增强对话历史以进行查询重构,包括但不限于重写和扩展。随着IR和NLP领域各种技术的发展,预计会出现更复杂的混合方法来增强查询重构。
2.2 现有数据集分析
对话式搜索数据集的发展显著促进了查询重构技术的进步。多个专用数据集从不同方面提供了独特的贡献。本节分析了现有数据集在查询重构中的应用,旨在帮助社区根据其构建细节(例如优点和挑战)开发和完善查询重构模型。典型的为对话式搜索设计的查询重构数据集包括CANARD [75]、QReCC [76]、TREC Conversational Assistance Track (CAsT) 系列 [77–80] 等。它们的构建涉及人工标注和自动生成。如前所述,标注的质量会极大地影响搜索性能。尽管成本较高,人工标注者会手动重写原始查询以提供清晰明确的上下文,确保高质量的标注。这在TREC Conversational Assistance Track (CAsT) 系列的测试集中得到体现,并在CANARD数据集的训练数据中得到了示例。QReCC数据集中提供的重写查询继承自CANARD,并通过使用指代消解规则替换代词来自动扩展。因此,其语言现象不如完全人工构建的数据集丰富。此外,与原始问题相关的文档的相关性判断是基于是否包含标注者的答案来确定的,这可能无法保证相应的重写查询是最佳的搜索查询。因此,在设计用于下游搜索任务的查询重构模型时,应仔细处理每个查询轮次的文档评估与重写查询标注之间的差异。
2.3 查询重构的评估
查询重构质量的评估对于确保对话式搜索系统的有效性至关重要。评估重构查询性能的主要方法有两种:1) 词汇重叠指标,2) 端到端检索性能。
词汇重叠指标:词汇重叠指标通过将重构查询与参考查询进行比较,使用词元级别的精确率(Precision)、召回率(Recall)和F1分数来衡量重构查询的准确性。精确率评估生成的所有词元中正确生成的比例,召回率衡量所有相关词元中正确生成的比例,F1分数则提供了精确率和召回率的调和平均值。这些指标提供了重构查询与参考查询匹配程度的定量评估,揭示了查询重写过程的准确性和完整性[75, 76]。
端到端评估:另一种评估查询重构的方法是端到端评估,它通过最终检索性能来衡量重构查询的有效性。这一原则可以应用于稀疏和密集检索系统。与临时搜索类似,在使用重构查询检索相关文档后,其有效性基于检索指标进行评估,例如平均倒数排名(MRR)、归一化折损累积增益(NDCG)以及不同截断水平的召回率(如Recall@10、Recall@100)。这种端到端评估提供了重构查询在实际检索场景中表现的综合评估,反映了查询重构对搜索结果的实际影响[6, 62]。
通过结合词汇重叠指标和端到端评估方法,研究人员可以全面了解查询重构技术的有效性。这种双重方法确保重构查询不仅与参考查询高度一致,还能在实际应用中提升检索性能。
2.4 局限性与讨论
尽管对话式查询重构技术取得了进展,但仍有一些局限性需要解决,以进一步提高其鲁棒性和有效性。
数据集偏差:大多数现有的查询重构数据集是自动构建的,即使是小部分带有人工标注的数据集,其“黄金查询”可能仍然由于标注偏差而次优。这种问题源于主观解释和标注不一致,导致训练数据次优。此外,数据集的规模有限,限制了训练模型在不同对话上下文中的泛化能力,导致实际应用中的查询重构不可靠。开发更大、更多样化且具有一致和准确标注的数据集是必要的。
评估挑战:用于查询重构评估的词汇重叠指标(如词元级别的精确率、召回率和F1分数)仅提供了间接评估,因为它们无法反映重构查询在下游搜索任务中的实际有效性。端到端评估虽然更全面,但可能受到模型偏差的影响,例如对不同的查询编码器敏感。这些偏差可能会掩盖查询重构技术的实际性能,导致与词汇重叠指标相同的问题。因此,评估的关键在于确保查询重构技术与直接下游搜索任务性能之间的关联。
长对话中的挑战:在现实场景中,随着对话的进行,长对话中的查询重构错误可能会逐轮累积。这种现象在较长的对话中尤为严重,导致对话式搜索系统的整体性能下降。此外,现有的查询重构技术仅专注于解决语义现象(如共指和省略)并从上下文中扩展关键术语,这可能不足以生成良好的搜索查询,或在对话深入时引入噪声。与临时搜索的查询重构不同,未来的对话场景应考虑更合适的机制,在重构搜索查询时识别有用信息并忽略上下文中的噪声。
未来查询重构的范式:现有检索系统(无论是临时搜索还是对话式搜索)中查询重构的目标是补充缺失的搜索方面或解决原始查询中的歧义。随着大型语言模型的发展,一些新的查询重构范式已经出现,例如与不同搜索代理的协作[198]、主动提供重构查询[199]、通过推理链和生成式语言模型进行查询重构[200–202]。这些研究从不同方面改进了查询重构,并针对不同的目标,但缺乏明确的范式。在演进的对话式搜索范式下,查询重构的最终目标尚不明确,需要社区进一步探索。
3 搜索澄清
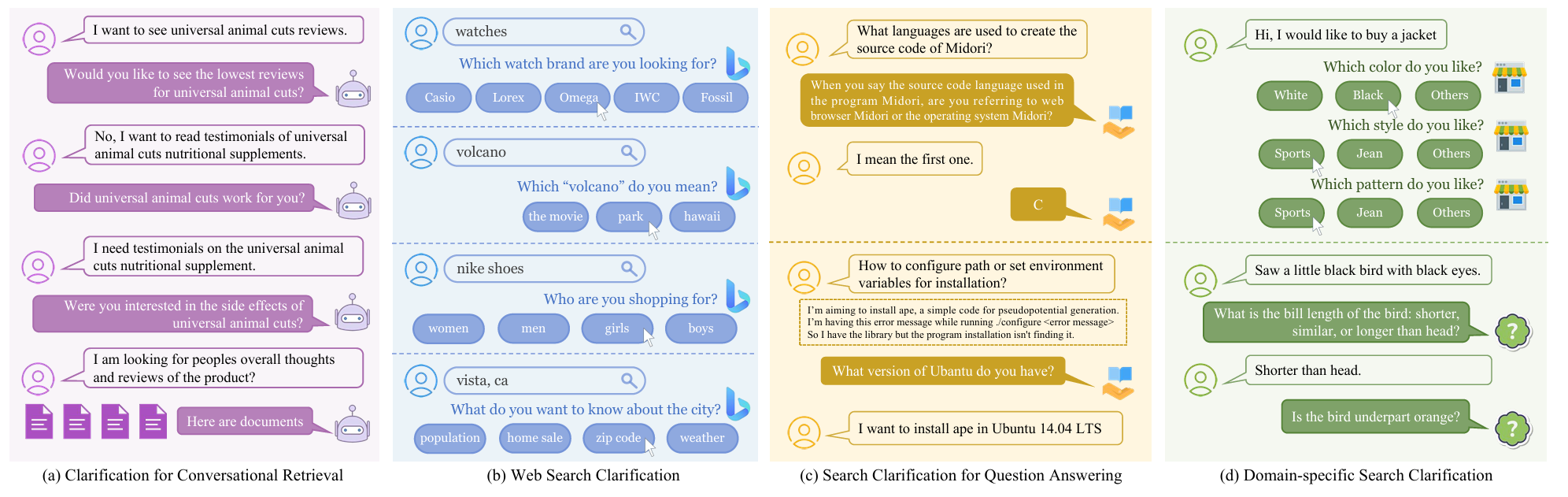
图5. 对话式搜索系统中搜索澄清的不同场景和示例,包括:(1) 对话式文档检索的澄清,(2) 网络搜索澄清,(3) 问答中的搜索澄清,以及(4) 领域特定的搜索澄清。
对话式搜索为用户提供了一个交互式界面,使他们能够通过多轮交互来寻求信息、执行行为或查找网站。在对话过程中,用户可能会表达模糊、多面或不明确的搜索意图,系统需要对其进行澄清以实现精确的查询理解。为此,系统应主动向用户提出澄清问题,帮助他们重新表达意图。在本节中,我们总结了关于在对话式搜索系统中提出澄清问题的研究。由于不同对话式搜索系统的场景可能各异,我们首先将澄清场景分为四个主要部分,包括:(1) 对话式文档检索的澄清,(2) 网络搜索澄清,(3) 问答中的搜索澄清,以及(4) 领域特定的搜索澄清。对于领域特定的搜索澄清,我们进一步将其划分为不同的具体领域,包括对话式推荐系统、法律搜索澄清、编程中的搜索澄清等。我们还总结了基于大语言模型(LLMs)的搜索澄清研究,并最后讨论了未来方向。在每个场景中,系统的行为可能有所不同,如图5所示。
3.1 对话式检索中的澄清
图5. 对话式搜索系统中搜索澄清的不同场景和示例,包括:(1) 对话式文档检索的澄清,(2) 网络搜索澄清,(3) 问答中的搜索澄清,以及(4) 领域特定的搜索澄清。
对话式检索是对话式搜索系统的关键部分。在这一检索过程中,搜索澄清被定义为用户与系统之间的多轮交互[19],如图5(a)所示。形式上,在每一轮交互\(k\)中,用户输入查询(\(k=1\))或响应系统返回的澄清问题(\(k>1\))。对于系统而言,它在每一轮中同时提出澄清问题并使用获得的上下文检索相关文档。带有澄清的对话式检索系统的基本思想是通过多轮查询引导用户提供更有用的信息,从而使系统能够返回更好的文档。因此,向检索模型添加澄清信息可以使系统检索到更符合用户意图的相关文档[203]。在本节中,我们首先总结了用于对话式检索澄清的可用数据集,然后介绍了在此设置下的澄清问题选择与生成方法。我们还探讨了专注于数据特征而非提出新方法的分析研究。最后,我们介绍了一些其他相关研究。
3.1.1 可用数据集
有几类可用于对话式检索澄清的数据集,它们对方法论的发展起到了支持作用。Qulac[19]和ClariQ[179]是两个常用的数据集,它们基于TREC Web Track 2009-2012数据[204]构建。由于这两个数据集仅包含通过众包编写的人工澄清问题和答案,不适用于许多场景(例如训练生成模型),Aliannejadi等人[205]进一步收集了合成对话以增强这两个数据集,并对几种最先进的搜索澄清方法进行了基准测试。他们还提出了一个用于在线和离线评估的管道。Sekulic等人[84]基于ClariQ提出了另一个增量数据集ClariQ-FKw,他们提取了澄清问题中的关键词作为关键信息。最近,Yuan等人[87]发布了第一个多模态澄清问题数据集Melon,通过引入多模态信息扩展了现有研究场景。用于对话式检索澄清的数据集的构建至关重要,它使系统的发展成为可能。
3.1.2 澄清问题选择
大多数基于Qulac和ClariQ数据集的早期研究通常关注如何从固定大小的问题池中选择每一轮的澄清问题以揭示用户的搜索意图,因为这些数据集仅支持在简单设置中进行探索。其中,Aliannejadi等人[19]首先设计了一个由澄清问题检索与选择以及文档检索组成的框架。此外,Hashemi等人[81]提出了Guided Transformer,通过利用外部检索文档帮助选择最优澄清问题。Bi等人[82]进一步应用负面反馈生成是/否形式的问题,以在最后几轮对话中探索用户的搜索意图。[83]指出,检索到的文档在每一轮选择最优澄清问题时起着重要作用,他们开发了两个微调模型用于问题检索和排序。尽管这些方法可以满足澄清需求,但候选澄清问题的规模限制了系统响应的能力。
3.1.3 澄清问题生成
从固定大小的问题池中选择澄清问题无法满足现实场景中用户的复杂搜索意图。因此,更优的范式是基于复杂的实际需求生成澄清问题。为此,Sekulic等人[84]首先提出了一种基于方面的方法,微调GPT-2以生成对话式检索的澄清问题。他们从问题中提取关键词以训练方面预测模型,然后利用预测的方面指导GPT-2模型生成问题。最近,Wang等人[85]研究了如何在零样本设置中通过使用方面约束的前缀提示语言模型生成澄清问题,从而降低了标注成本。
3.1.4 分析研究
搜索澄清是实现系统与用户之间混合主动交互的重要组成部分。为了全面理解搜索澄清如何为对话式搜索系统做出贡献,一些分析研究被开展。Krasakis等人[203]首先分析了澄清问题和用户答案是否会影响对话式检索系统中的文档排序能力,以及问题或答案对排序结果的影响是否更为显著。此外,Aliannejadi等人[206]分析了反馈顺序和检索策略如何影响用户的搜索体验。他们揭示,当系统首先提问时,查询澄清效果更好,而当系统在呈现搜索结果后提问时,查询建议效果更佳。最近,Sekulic等人[207]进一步提出了一种分类算法来衡量澄清问题和用户答案的有用性。这些分析研究从经验上展示了在对话式搜索系统中实施搜索澄清机制的有效性。
3.1.5 信息集成
尽管可以生成澄清问题,但很难收集用户对问题的相应响应以改进或评估系统。因此,常见的做法是模拟用户的响应/反馈并将其集成以改进澄清或搜索的性能。为此,Wang等人[86]提出了一种模拟用户响应的方法,并研究了用户如何回复澄清问题及其影响。然后,通过设计的模拟器验证了系统能够更好地提供澄清问题并检索搜索结果。此外,Yuan等人[87]认为非文本信息(如图像和视频)可以为搜索澄清提供额外信息。他们构建了Melon数据集,并提出了一种有效的多模态搜索澄清管道。在未来探索中,更有效的自动生成和集成额外信息(如用户模拟)的方法值得期待。
3.2 网络搜索澄清
图5. 对话式搜索系统中搜索澄清的不同场景和示例,包括:(1) 对话式文档检索的澄清,(2) 网络搜索澄清,(3) 问答中的搜索澄清,以及(4) 领域特定的搜索澄清。
前述关于对话式检索中搜索澄清的研究仅限于在固定集合中选择澄清问题并评估响应。与之不同,Zamani等人[88]提出了网络搜索中的澄清。在网络搜索中,用户查询的形式更加灵活,可以是对话式查询或关键词查询。当用户的查询模糊或多面时,系统可以向用户提出澄清问题,并提供多个候选方面供用户选择,形成如图5(b)所示的澄清面板。在澄清面板中,澄清问题通常用于改善用户的搜索体验,而候选方面则是一组生成或选择的术语,代表用户可能感兴趣的高一致性子意图。当用户点击其中一个给定方面时,查询将通过与所选方面连接重新构建,形成新查询并检索新的网页列表[91]。
3.2.1 数据集
有几个数据集可用于支持网络搜索澄清的探索。其中,MIMICS是由[177]提出的第一个数据集,基于Bing搜索引擎的搜索日志,因此包含丰富的用户兴趣信息。MIMICS数据集分为三个子集,即MIMICS Click(约40万)、MIMICS-ClickExplore(约20万)和MIMICS-Manual(约2千)。前两者完全基于Bing搜索日志,包含大量查询和在线用户反馈,通常用作训练数据。两者的区别在于,MIMICS-ClickExplore中的每个查询对应多个可能的澄清面板,而MIMICS-Click中的每个查询仅包含唯一的澄清面板。MIMICS-Manual中的查询包含人工质量标注,通常用于评估。之后,Tavakoli等人[184]进一步发布了另一个数据集MIMICS-Duo,用于网络搜索澄清的多维离线和在线评估。
3.2.2 生成澄清问题
在网络搜索澄清中,关键问题是如何向用户提出自然且信息丰富的澄清问题。Zamani等人[89]表明,一个好的澄清问题可以通过把握系统的智能性来改善搜索体验。为了生成好的澄清问题,Zamani等人[88]首先提出了基于问题模板和搜索日志的三种算法,为后续研究奠定了基础。他们进一步提出了一个基于Transformer的框架[89],用于选择最优澄清面板。之后,Wang和Li[90]提出了一种基于模板的新方法,让模型填充问题模板中的槽以形成澄清问题。然而,Zhao等人[91]认为基于模板的方法难以找到查询和方面的描述,因此他们提出从查询的网页搜索结果中寻找描述。之后,Zhao等人[92]设计了一个基于BART的seq2seq模型,同时生成澄清问题和候选方面。最近,Rahmani等人[13]通过分析MIMICS[177]和MIMICS-Duo[184]中的数据,研究了澄清的有用性。他们得出结论,具体、积极情感导向、冗长和主观的问题有助于改善用户体验。上述研究从多个角度分析了澄清问题的作用,并提出了相应的生成方法。
3.2.3 生成候选方面
与其他场景中的搜索澄清不同,网络搜索澄清不仅提出澄清问题,还为用户提供多个候选方面供点击。这促进了用户交互,更适合开放域场景。在此之前,查询方面是一种常见的查询意图挖掘解决方案,旨在挖掘全面、多维的查询子意图。例如,有一些基于规则和机器学习的方法从查询的搜索结果页面中挖掘这些术语[93–95]。与这些研究不同,网络搜索澄清专注于找到用户最感兴趣的一组方面,而不是将所有方面展示给用户,这有助于集中用户的兴趣并提供更好的用户体验。遵循这一思路,Hashemi等人[96, 97]首先提出了使用seq2seq框架生成这些方面。Samarinas等人[98]总结了所有基于规则、机器学习和预训练语言模型的主流方法和模型,以生成搜索澄清的候选方面,并得出结论,基于BART的模型以查询和搜索结果片段作为输入,在几乎所有评估指标中表现最佳。Zhao等人[92]认为候选方面通常以列表形式出现,因此他们从搜索结果页面中收集并行结构,并利用这些信息增强基于BART模型的生成能力。Litvinov等人[99]分析了候选方面的连贯性是否以及如何影响生成性能,并提出了一种基于连贯性的生成方法。Zhao和Dou[100]认为直接生成候选方面在多轮方式中不合适,因此他们提出了另一种框架,以多轮方式生成候选方面。最近,随着LLMs的发展,一些基于LLM的方法被提出用于生成网络搜索澄清的候选方面。Ni等人[101]进行了一项比较研究,比较了不同训练目标和基础模型在生成澄清方面时的表现。Lee和Kim[102]完全依赖LLMs生成方面。我们相信,基于LLMs的方面生成将成为更有效的方法,因为LLMs包含大量通用和领域特定知识。
3.2.4 其他相关研究
现有的网络搜索澄清研究通常生成几个子意图作为澄清候选选项。然而,在某些情况下,用户也对并行意图转移感兴趣。为此,Liu等人[103]设计了三种算法,从搜索结果中挖掘并行转移方面,并将这些方面定义为探索性查询。除了生成澄清面板外,Sekulic等人[104]学习了如何使用从真实搜索引擎收集的数据预测用户参与反馈,Lotze等人[105]研究了使用这些预测的用户参与度对澄清问题候选进行排序。此外,Gao和Lam[106]利用这些用户参与预测信息,设计了一种查询-意图-澄清图注意力机制,以选择最优澄清面板。
3.3 问答中的搜索澄清
图5. 对话式搜索系统中搜索澄清的不同场景和示例,包括:(1) 对话式文档检索的澄清,(2) 网络搜索澄清,(3) 问答中的搜索澄清,以及(4) 领域特定的搜索澄清。
在问答(QA)中,目标是回答用户的具体问题。然而,问题可能包含歧义,尤其是在对话式场景下。因此,提出澄清问题以消除歧义是必要的。在本节中,我们将现有的问答搜索澄清研究分为两类:(1) 社区问答,(2) 基于知识的问答。如图5(c)所示,对于社区问答,系统通常关注特定领域场景(如编程)中的歧义意图,而基于知识的问答中的澄清通常关注实体歧义。
3.3.1 数据集
在一些社区问答研究[107, 108]中,数据是从社区问答网站(如StackExchange和Amazon)中提取的。这些网站包含大量歧义问题、用户答案和澄清问题。随后,Kumar和Black[178]基于StackExchange提出了一个数据集ClarQ。据我们所知,ClarQ的规模远大于其他基于StackExchange的数据集。另一方面,在基于知识的问答中,Abg-CoQA[182]被提出来解决对话式问答中的歧义问题,其重点是人类对话中的消歧。
3.3.2 社区问答
Braslavski等人[208]首次分析了社区问答中的澄清问题。他们研究了两个领域的用户问题,并分析了用户行为和所提澄清问题的分类。之后,Rao等人[107, 108]设计了不同的方法为社区问答生成好的澄清问题。Trienes和Balog[109]是第一个研究社区问答问题是否清晰的研究。他们提出了一种判断问题是否需要进一步澄清的方法。Kumar等人[110]研究了如何通过自然语言推理对澄清问题候选进行排序。由于社区问答中的澄清机制较为复杂,一些研究[209, 210]对好的澄清问题的特征、澄清问题的分类以及用户答案的类型进行了分析。尽管这些研究提出了生成社区问答问题的有效方法,但这些方法难以迁移到其他开放域场景中。
3.3.3 基于知识的问答
在基于知识的问答系统中,澄清过程通常针对实体之间的指代问题。Xu等人[111]提出了一个数据集CLAQUA,专注于解决基于知识的问答中的澄清问题。他们还识别了单轮和多轮歧义,并设计了应对这两种情况的方案。Nakano等人[112]探讨了基于句子结构生成伪歧义和澄清问题对澄清问答系统的影响。该研究为优化澄清问答系统提供了有用的指导,使其能够更好地理解用户需求并生成更有针对性的澄清问题。Kim等人[113]研究了使用检索增强的大语言模型处理歧义问题的方法。Lee等人[20]对如何在开放域问答系统中与用户交互以及如何根据用户需求调整系统行为进行了深入分析。上述研究有效解决了实体歧义问题,这对于理解对话式搜索中用户的歧义意图至关重要。
3.4 领域特定的搜索澄清
图5. 对话式搜索系统中搜索澄清的不同场景和示例,包括:(1) 对话式文档检索的澄清,(2) 网络搜索澄清,(3) 问答中的搜索澄清,以及(4) 领域特定的搜索澄清。
除了上述通用的搜索澄清场景外,一些研究还关注封闭搜索场景,如对话式推荐系统、法律搜索等,这些场景同样重要。图5(d)展示了两种封闭领域设置,这些场景需要方法根据具体情况进行调整。我们在本节中介绍并总结了不同领域特定搜索澄清场景的相关研究。
3.4.1 对话式推荐系统
对话式推荐系统(CRS)也是一种搜索澄清场景,用户需要购买产品,系统通过询问产品的不同属性逐步缩小产品范围,使用户更容易找到想要购买的产品。我们列出了近年来一些具有代表性的相关研究[211–222]。由于CRS可以被视为一个独立的研究领域,已有一些综述[223–225]全面总结了相关工作,并提供了更多细节。
3.4.2 法律搜索澄清
在法律搜索中,由于法律文档的复杂性,用户通常表达模糊的意图。因此,澄清问题可以有效地帮助用户表达其复杂的搜索意图。Liu等人[49]比较了对话式搜索和传统搜索在法律案例检索中的行为和结果。之后,他们进一步探讨了缓冲机制和生成查询如何帮助提高对话代理在法律案例检索中的性能[144]。此外,他们还尝试研究对话代理检索更好法律案例的行为。该研究为理解对话代理如何与用户交互以及如何根据用户需求调整其行为提供了深入分析。最近,Liu等人[226]引入了事件模式。通过应用事件模式,对话代理可以更好地理解用户的潜在意图并提出有针对性的澄清问题,从而提高检索法律案例的准确性和效率。
3.4.3 其他场景中的搜索澄清
搜索澄清可以进一步应用于用户查询或问题可能模糊或多面的任何场景。在本节中,我们列出了一些其他场景中的搜索澄清研究。这些研究用于将澄清扩展到新场景,并可以提供启发。
• 交互式分类[88]
• 图像猜测[227]
• 产品描述[228, 229]
• 协作构建[230]
• 编程[231, 232]
• 用户模拟[233]
• 社会或道德情境[11]
• 任务导向对话[21]
• 数学[234]
• 空间推理[235]
• 协作对话[236]
3.5 基于大语言模型(LLMs)的搜索澄清
近年来,随着大语言模型(LLMs)的发展,也有一些研究探讨如何让LLMs提出澄清问题。例如,在对话式检索的澄清中,LLMs可用于生成澄清问题并模拟用户响应[85, 86]。在网络搜索澄清中,LLMs可用于生成更好的澄清问题或查询方面[100–103]。在对话式推荐系统中,利用LLMs也可以提高推荐效果[221, 222]。这些研究表明,由于LLMs强大的自然语言生成和指令遵循能力,它们有助于现有场景提升系统性能。凭借LLMs强大的自然语言生成能力,现有任务和场景可以得到有效改进。然而,目前尚不清楚LLMs是否可用于扩展现有澄清场景,使澄清具有更广泛的定义和应用范围。为此,Mu等人[12]提出了ClarifyGPT,为代码生成提出澄清问题。一些研究探索了新的搜索澄清场景。例如,[114]通过LLMs生成的澄清问题激发用户兴趣。Andukuri等人[115]进一步设计了一个强化学习系统以生成更好的澄清问题。Deng等人[116]提出了“重述与响应(RaR)”框架,让LLM生成澄清问题。
3.6 未来讨论
如本节所述,搜索澄清已在各种类型的对话式搜索系统中得到研究和应用,包括:(1) 对话式(文档)检索的澄清,(2) 网络搜索澄清,(3) 问答中的搜索澄清,以及(4) 领域特定的搜索澄清。我们还介绍了基于LLMs的搜索澄清。然而,尽管许多现有场景已经探索了搜索澄清的有效性,但在LLMs时代,我们仍可以在许多方面进行未来讨论。在本节中,我们提出了搜索澄清的三个潜在未来研究方向。
LLMs的搜索澄清
在第3.5节中,我们总结了最近关于基于LLMs的搜索澄清研究。这些研究侧重于利用LLMs作为工具来提高对话式搜索系统中搜索澄清的有效性。然而,在某些情况下,LLM本身也可以被视为一个拥有大量用户日志的对话式搜索系统。对LLMs本身的搜索澄清也值得研究。
检索增强生成中的搜索澄清
当前一些热门搜索场景也可以引入澄清以增强效果,例如检索增强生成(RAG)。例如,当用户提出包含歧义实体的问题时,系统可以提出问题让用户消除查询歧义,然后再进行检索过程。系统还可以识别问题中体现的模糊或多面意图,以提出更自然的澄清问题。
垂直领域中的搜索澄清
我们可以在一些垂直领域中探索更自然的澄清生成,例如医疗咨询、客服机器人等。
4 对话式检索
给定一个多轮信息寻求对话,对话式搜索系统旨在从大规模文档集合中检索相关段落。由于需要对对话上下文和当前用户查询进行理解,这被认为比传统的临时检索更为复杂。此外,用户与系统之间的对话通常包含丰富的语言模式和话题转换,这增加了上下文建模的难度。阻碍对话式检索模型的挑战来自不同方面,具体介绍如下。首先,尽管最近的神经模型(如BERT [237]、T5 [238] 和最近出现的LLMs [239])在序列建模方面表现出先进的能力,但完全解释多轮自然语言形式的对话仍然是一个长期挑战。其次,搜索意图的转换会向历史上下文中引入大量噪声,这些噪声与当前的搜索行为无关[24, 62]。因此,如何对对话上下文进行去噪至关重要。第三,对话式检索模型的训练数据有限。标注多轮交互对人类标注者来说非常耗时,且段落的相关性信号难以获取。因此,开发了各种级别的数据增强技术,例如生成查询、上下文-段落对以及整个对话。最后,尽管对话式检索模型通常比查询重构方法表现更好,但缺乏可解释性阻碍了对对话中密集表示的理解。为了解决这些挑战,现有的对话式检索研究可以分为四类:(1) 对话建模,(2) 上下文去噪,(3) 数据增强,(4) 解释。
4.1 对话建模
与传统的单轮检索不同,建模多轮对话需要更复杂的模型架构设计。HAM [117] 是一项早期工作,利用预训练语言模型(PLM)BERT [237] 和注意力机制对对话历史进行软选择。该模型根据历史交互的相关性和对解决当前信息需求的有用性为其分配不同的权重。它还采用多任务学习来执行对话响应生成任务和对话行为预测任务,以学习更鲁棒的对话表示。Qu等人[22] 提出了一种标准的对话上下文建模方法,通过连接对话中的所有历史查询,并使用基于PLM的编码器将这种连接建模为密集表示以用于检索任务。Le等人[118] 利用稀疏检索器SPLADE [240] 将对话建模为查询和段落的稀疏表示,Jeong等人[23] 则通过建模对话依赖性来实现搜索结果的短语级检索。为了更好地理解对话中用户行为之间的复杂关联,一些研究人员利用基于图的方法对对话进行建模,以捕捉不同查询轮次与检索池之间的联系。Li等人[119] 采用图引导的检索方法,建模不同轮次响应与当前用户查询之间的内部依赖关系。此外,他们开发了一个框架DGRCoQA [120],该框架包括三个组件:动态问题解释器、图推理增强检索器和标准阅读器,以构建动态上下文图来建模对话的响应流。
在LLM时代,强大的上下文理解能力使社区能够设计更复杂的对话建模方法。Pan等人[121] 开发了一种用于对话检索的动作链,设计了一个包含系统提示、预定义动作和基于Hopfield的检索器的框架。Mao等人[26] 使用一种简单但有效的对话指令调优技术,基于对比学习训练LLM,从而为对话检索执行增强的复杂对话建模。这项工作探索了在多轮场景下对齐LLM以检索相关段落的潜力。
4.2 上下文去噪
在对话会话中,并非所有的历史查询轮次都与解决当前用户信息需求相关。简单地连接所有历史上下文会引入不必要且嘈杂的轮次,从而降低系统性能。如何准确识别对话中有用的历史上下文是一个关键的研究问题。
4.2.1 隐式上下文去噪
一些工作尝试隐式地进行上下文去噪。例如,Yu等人[122] 利用密集检索将对话查询和文档嵌入到一个共享的向量空间中,可以直接测量语义相似性。它采用了一种教师-学生框架,通过继承现有训练良好的密集检索器的文档编码并学习模仿教师对查询的嵌入来指导学生模型。这种策略通过捕捉必要的上下文同时忽略无关信息来提高跨对话轮次的检索准确性。Mao等人[24] 开发了一个结合课程学习和对比学习的框架,逐步指导对话查询编码器如何从对话历史中过滤掉无关信息。它涉及生成嘈杂和干净的对话数据版本,并通过逐步增加训练数据的复杂性来训练模型。Krasakis等人[123] 旨在通过利用现有的临时搜索数据来理解和过滤掉嘈杂的上下文,从而在不额外微调对话数据集的情况下提高检索段落的相关性判断。具体来说,它在对话中对查询嵌入进行上下文化,同时确保只有当前查询术语与潜在答案匹配。最近,Mo等人[124] 提出了QRACDR,首先为查询表示学习定义一个更好对齐的嵌入空间,并通过重写查询和相关判断使模型学习将查询表示与该区域对齐,从而隐式地获得较少噪声的上下文表示。
4.2.2 显式上下文去噪
与隐式进行上下文去噪不同,一些研究人员尝试显式地识别和选择有用的历史对话上下文。例如,Mo等人[62] 专注于选择与当前查询相关并能增强其效果的历史查询,而不是使用所有之前的查询,后者可能会引入噪声并降低搜索性能。他们设计了一种伪标签算法,根据对搜索结果的影响来识别历史查询的有用性,随后在这些伪标签上训练选择模型。设计了一个多任务框架,同时优化选择器和段落检索器,保持历史查询选择与检索操作之间的一致性。基于之前的观察,他们进一步开发了HAConvDR [27],以增强对话式搜索系统处理复杂用户-系统交互的能力(例如频繁的主题转换和长噪声上下文),该框架基于一种上下文去噪的查询重构策略,选择性地将相关历史信息纳入当前查询,并通过一种机制从历史轮次中挖掘额外的监督信号来指导历史感知的训练过程。这种上下文去噪机制通过适应实际场景显著提高了对话式搜索系统的性能和鲁棒性。
4.3 数据增强
在对话式检索系统中,有效的查询理解严重依赖于大规模数据集,因为多轮场景中存在长尾和复杂的语言现象。然而,通常缺乏足够的标注数据来使训练过程可行。为了丰富对话式检索数据,文献中探索了各种级别的数据增强方法,包括:1) 相关性判断生成,2) 对比样本生成,3) 对话会话生成。
4.3.1 相关性判断生成
在信息检索的背景下,手动获取相关性判断的成本很高,而在对话式搜索中这一问题更加明显。为了缓解标注稀缺的问题,文献中的常见做法是自动生成相关性判断。例如,Lin等人[125] 基于伪相关反馈生成伪相关性标签,帮助指导模型通过端到端的方式将对话式查询重构直接集成到密集检索框架中,从而实现了跨阶段的更一致优化。Jin等人[126] 利用LLM提供一种监督信号,可以在不需要大量手动标注的情况下指导对话式检索器的训练。其原理是将LLM作为“指导者”生成软标签,通过LLM估计的相关性分数在无监督训练框架中指示会话-段落对的相关性。这种方法通过利用LLM的生成能力来解决对话式检索任务中的数据稀缺问题,是一个值得进一步探索的方向。
4.3.2 对比样本生成
对于密集检索[241] 和对比学习[242] 来说,足够的监督信号(无论是正样本还是负样本)都非常重要。在对话场景中,可以从对话历史中生成额外的对比样本。其基本假设[27] 是,在历史检索结果中,一些结果可能与当前查询高度相关,可以作为伪正样本,而其他结果则相关性较低,可以作为训练中的难负样本。此外,Kim等人[127] 发现了一种“检索捷径”现象,即模型过度依赖部分对话历史而忽略当前查询,导致主题漂移。为此,这项工作从历史轮次中挖掘额外的难负样本,通过迫使模型同时考虑当前问题和整个对话历史来缓解对检索捷径的依赖。
4.3.3 对话会话生成
由于对话场景下的搜索系统尚未广泛实施,获取足够高质量的会话级搜索数据以促进对话式密集检索器的微调具有挑战性。为了解决这一问题,Mao等人[128] 提出了一种数据增强解决方案,通过将现成的网络搜索会话转换为对话式搜索会话,基于网络搜索会话和对话式搜索会话之间的结构和行为相似性。它将原始网络搜索会话重新组织成一个表示用户交互多轮性质的异构图,并通过添加额外的查询来提高多样性。然后,采用随机游走采样算法生成伪对话式搜索会话,用于训练对话式密集检索模型。随着LLM的发展,Mo等人[129] 利用LLM创建额外的对话会话数据,通过两种方法增强训练数据的多样性和数量:对话级会话生成(基于给定主题创建整个会话)和查询级增强(以不同方式重新表述现有查询以表达相同意图)。类似地,Huang等人[130] 提出了CONVERSER,通过提供引导示例来实现少样本生成。Chen等人[25] 提出了ConvAug,其动机是现有对话式搜索数据集中对话表达的多样性有限,使得模型难以适应现实世界的复杂性。受人类认知启发以提高生成数据的质量并减少错误,ConvAug利用LLM生成多级增强对话,以捕捉更广泛的对话上下文。此外,它还采用难度自适应样本过滤器来选择复杂对话中的挑战性样本,扩展了训练模型的学习空间。
4.4 对话式密集检索中的可解释性
尽管对话式密集检索在对话式搜索中已被证明是有效的,但这些方法的一个显著局限性是缺乏可解释性,这阻碍了对模型行为的直观理解并妨碍了有针对性的改进。为此,现有研究[243] 尝试揭示各种对话式密集检索模型的行为特征。例如,Mao等人[131] 提出了LeCoRE,通过创建对话会话的去噪和稀疏词汇表示来增强可解释性。具体来说,LeCoRE扩展了SPLADE模型[240],这是一种基于词汇的模型,进一步将潜在表示转换为词汇空间中的词汇表示,从而提供与搜索结果相关的清晰且可理解的表示。此外,Christmann等人[132] 通过结合来自多个来源的信息并为搜索结果提供用户可理解的解释来提高模型的可解释性。进一步,Cheng等人提出了CONVINV [133],将对话式密集检索模型生成的不透明高维会话嵌入转换为明确的、可解释的文本,便于人类理解。这种转换通过一个训练有素的模型实现,该模型将会话嵌入反转为文本形式,不仅连贯清晰,还能保持原始嵌入的检索性能。与显式进行对话式搜索的查询重构不同,未来需要对密集检索中的可解释性进行更详细的研究,以避免不公平或误导性的搜索结果,并及时纠正。
4.5 对话式搜索中的重排序
在传统搜索过程中,重排序在首次检索步骤之后至关重要[1],其目的是通过增强相关查询的相关性来重新排序从第一阶段检索中获取的文档。在对话场景中,可以适应相同的搜索流程,即结合第一阶段的上下文表示和第二阶段的重排序器来执行对话式搜索。有效的重排序有望显著提高后续答案提取过程的准确性,因为它使阅读器模型能够处理最佳文档集,从而提高对话式搜索系统的整体质量和可靠性。在对话式搜索的重排序背景下,Kongyoung等人[134] 设计了monoQA,通过多任务学习训练一个模型,同时用于重排序检索到的段落和提取答案。通过将重排序和阅读集成到一个统一的模型中,monoQA提高了整体检索精度和答案准确性。Ju等人[28] 尝试通过采用多视图伪标签方法来提高重排序准确性,该方法整合了多样化的上下文信息。它利用视图集成方法生成高质量的伪标签数据,用于微调对话式段落重排序器。Hai等人[118] 在对话式检索阶段之后设计了一个重排序过程,该过程通过第一阶段检索器识别的关键词进行丰富。这些关键词旨在捕捉有用的上下文信息,并利用有用的对话历史对文档进行重排序。Owoicho等人[135] 通过提供系统响应的反馈和回答澄清问题来研究对话式搜索系统,基于用户信息需求的初始描述。这项工作讨论了通过开发更复杂的反馈处理模块(例如基于对话上下文的重排序器)来推动对话式搜索的潜在进展。
4.6 局限性与讨论
现有研究在多轮复杂信息需求的相关段落识别方面取得了巨大成功。本节旨在讨论对话式检索的局限性和潜在解决方案。
有效流程的标准:尽管文献中探索了具有不同机制的多种对话式检索流程,但如何建立一个统一的标准来构建和比较有效流程仍然是一个开放性问题,例如如何比较查询重构方法与对话式密集检索模型。此外,如何将多轮信息(例如历史检索结果)纳入当前轮次检索中,以及是否需要在检索流程中部署重排序器,这些问题也尚未得到充分研究。这些问题需要社区进一步研究如何在可比标准下构建包含相关历史上下文的对话式检索流程。
效率问题:现有的对话式检索模型通常比对话式查询重构方法表现更好,但由于将整个长对话作为输入,它们通常会遇到效率问题。当骨干检索模型是基于LLM(即具有大规模参数)时,这一问题会更加严重。一个可能的直观解决方案是采用缓存机制来存储对话片段的中间表示,从而避免为每个新查询重新处理整个对话历史。此外,利用查询性能预测技术[244] 可以帮助避免冗余的流程步骤。
泛化能力:使用对话式搜索数据微调的密集检索器与临时搜索检索器和普通语言模型(无论是基于PLM还是LLM)相比,不可避免地会丧失一些通用能力。为了增强检索器的泛化能力,使其能够同时适应临时搜索和对话式搜索,研究人员被鼓励结合先进的指令调优技术以面向不同任务,或开发混合数据以用于搜索导向的微调。
可解释性:尽管一些现有工作开始关注对话式密集检索器的可解释性,但对解释研究的探索仍然有限。对对话式(密集)检索模型进行详细和彻底的研究可以帮助社区理解用户和检索器的行为,这对于交互式系统至关重要。一个潜在的解决方案是进行全面的性能分析,探索对话的不同方面(例如主题切换、扩展利用)如何影响检索效果和用户建模。
5 对话式搜索中的生成
生成模型的发展推动了对话式搜索系统的演进,这些系统通过生成上下文感知和个性化的响应来丰富用户体验[2]。随着聊天模式(即多轮对话)成为利用LLMs进行内容生成的常见实践,通过集成生成模块设计对话式搜索系统的新范式引起了更多关注,然而,这一领域在文献中尚未得到充分研究。现有研究主要集中在单轮检索增强生成(RAG)上,其仅处理单轮独立查询或通过重写技术将多轮上下文依赖查询转换为单轮查询,而未利用历史信息进行RAG。在单轮RAG范式中,生成组件对于生成既基于外部知识又与参数化知识一致的响应至关重要。检索到的文档通常作为外部知识,而生成模型(在现有研究中通常为LLM)通过两种关键方法处理这些文档[245]:上下文整理[246–249]和生成器微调[250, 251],前者试图适应IR与RAG之间的一致性[252, 253],后者则分别满足领域或任务的特定需求。
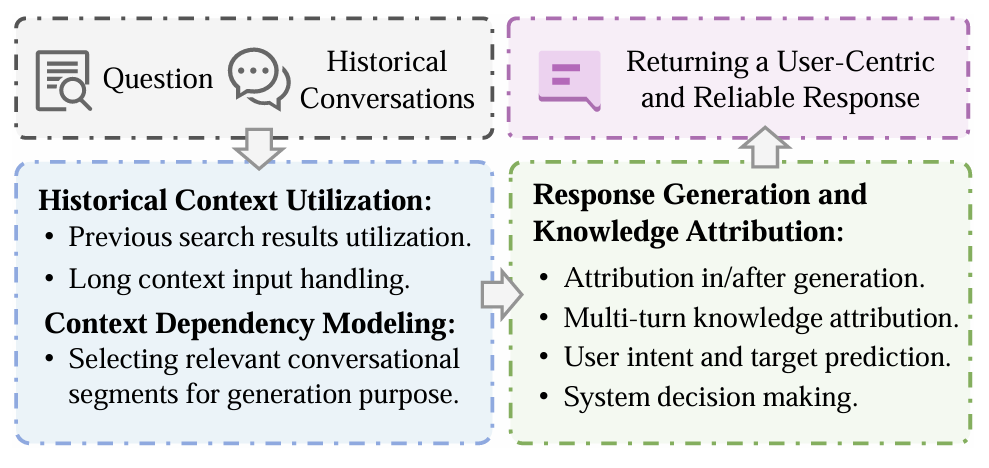
图7. 对话式响应生成系统的概述。为了实现更以用户为中心和可靠的响应,值得进一步探索的潜在方向包括历史上下文利用、上下文依赖建模和知识归因。
关于对话式搜索中的生成,单轮RAG系统忽略了历史信息,例如历史搜索结果、上下文历史、轮次依赖等。由于对话式搜索系统必须考虑正在进行的对话和对话的上下文演变,以生成不仅相关且与用户先前交互一致的响应,历史信息可能对生成准确、可靠和个性化的响应至关重要。因此,尽管一些具有类似目标的机制已在检索过程中应用,但额外的对话上下文处理是否能进一步改善生成结果尚不明确。考虑到目前专注于对话式搜索中生成概念的研究较少,在本节中,我们旨在提供潜在的研究问题、对未明确点的指导以及不同方面的相应解决方案,以促进该领域的未来研究。对话式生成系统的概述如图7所示。
5.1 历史搜索结果的利用
历史搜索结果是一个重要但被忽视的信息,它可能对当前轮次的RAG有所帮助[121, 136]。其假设是,早期轮次检索到的结果可以作为补充,增强当前轮次响应的生成。潜在的改进可能归因于通过提高搜索多样性来增加当前轮次的召回率,或者通过增强将频繁出现在前一轮次的低排名文档推至顶部。从更广泛的角度来看,关键思想是通过选择有用信息并避免引入额外噪声,将历史搜索结果与当前结果整合。系统期望构建一个不仅上下文相关且动态适应对话线程的叙述,使其表现出情景记忆的能力,回忆并引用先前的交互以指导当前对话。然而,历史搜索结果的使用原则尚不明确,未来研究需要更多探索。此外,在设计方法时需要考虑两个潜在挑战。一个挑战是长上下文输入,因为长对话会话和较大的top-k检索列表会显著增加输入长度,导致高延迟成本。此外,上下文可能超过模型输入限制。因此,直观的想法是增加RAG模型的长上下文容量,并通过选择或聚合历史搜索结果中的信息来减少延迟。另一个挑战在于识别历史搜索结果的利用。由于IR与RAG之间的相关性/有用性可能存在不一致,检索器识别的文档可能与生成器的需求不一致。因此,需要一个理想的机制来辨别哪些信息是相关的,并将其整合到正在进行的对话中,以提供更合适的生成响应。
5.2 上下文依赖建模
现有研究[137–139]以不同方式捕捉对话中的上下文依赖,通过更好地理解和满足用户的搜索意图来提高对话式检索的准确性。直观的想法是从历史中检测具有相似信息需求的查询轮次。在对话式生成中,当前轮次与历史轮次之间的依赖关系可能与检索的影响不一致,这需要进一步探索。上下文建模的常见做法是简单地将所有历史上下文连接为输入,这可能无法明确区分历史与当前问题之间的相关性差异。尽管在对话式检索中开发了一些复杂的机制,但生成过程的选择原则不一定相同。因此,在为响应生成目标进行上下文依赖建模时,设计的机制应避免无关信息的干扰,并针对最终答案而不仅仅是排名列表质量。此外,现有的上下文建模研究通常将检索和生成作为独立阶段。然而,检索阶段选择的轮次中的相关对话片段也直接影响后续生成质量。因此,一个有前景的解决方案是通过利用生成质量的反馈,以端到端的方式联合学习检索和生成的上下文建模。
5.3 对话式知识归因
知识归因,也称为引用标注,旨在将输出内容与其知识源关联以增强可信度。现有的知识归因方法可分为两类,与生成并行或在生成之后[254, 255]。前者在生成答案的同时直接生成引用,典型的现有研究包括WebGPT[140]、LaMDA[141]、WebBrain[142]等。为了生成可靠的答案-证据对,SearChain[256]生成查询链以对齐问题和证据,VTG[257]引入验证模块以确保答案与证据之间的一致性。第二类方法[258–260]旨在生成后首先使用自然语言推理(NLI)模型计算响应与证据之间的相关性,然后对内容进行后编辑以添加引用。尽管这些方法从不同角度增强了知识归因和可解释性,但它们并非为对话式场景设计。因此,尚不清楚它们是否适用于对话式生成。例如,这些方法是否也能归因于在注入前几轮上下文信息时检索到的历史证据?潜在的探索和改进可以从以下几个方面开始。
多轮知识归因
现有方法主要关注单轮问答,而多轮对话还应考虑上下文依赖性和不同历史轮次的渐进知识归因。可以探索基于图或分层结构的表示方法,以捕捉主题流和知识演变。关键点是从对话历史中识别有用知识,包括但不限于历史搜索结果、轮次依赖等。确定的有用知识可以作为无噪声的证据,以提高响应生成的质量。
用户意图与目标
多轮场景中的知识归因可以与对话意图和目标结合。由于用户意图和目标可能在对话过程中动态变化,需要基于意图和目标转移动态调整归因粒度和范围。潜在的解决方案是识别意图转换,检测不同用户意图中的关键知识,并实现意图驱动的归因。
系统决策
多轮知识归因可以与系统的决策协作,随着对话的进行动态决定是否跟进、纠正错误、消除噪声或引入新话题,基于归因知识的确定性和重要性。这也有助于构建混合主动的对话式搜索系统。知识归因可以作为不同决策策略的基础,而这些策略也可以指导知识归因方法和知识的粒度。协同优化有望提高知识归因组件和系统决策的智能性。
6 领域特定和以用户为中心的对话式搜索
对话式搜索系统的快速发展促进了其在通用领域和多个特定领域中的应用,包括医疗[261]、金融[262]、法律[51]、电子商务[145]等。领域特定系统可能以不同形式存储领域特定知识,例如表格、图或多模态数据,这要求搜索系统通过推理技能收集各种信息资源。除了特定领域需求外,系统还应涵盖真实用户对对话式搜索模型的预期使用。因此,设计的系统在数据集构建和评估标准中也应考虑以用户为中心的视角[263],而不仅仅关注预定义的搜索能力。此外,从个性化角度来看,由于用户的背景不同,对话式系统对同一查询的搜索结果应根据用户配置文件生成不同的结果,基于识别每个查询轮次中用户配置文件中的相关信息[10]。本节介绍了在各个特定领域和以用户为中心的场景中进行的开创性对话式搜索研究,并通过全面讨论新兴的局限性和挑战来总结。
6.1 领域特定的对话式搜索
早期研究[264–266] 尝试通过基于任务起源的对话系统进行多领域/任务学习来解决领域特定问题。其核心思想是通过推理对话历史来搜索跨领域信息以共享。尽管这些系统可以处理跨领域的各种类型信息,但在针对每个特定领域时无法达到令人满意的性能。因此,针对每个领域提出了各种领域特定模型。
6.1.1 医疗领域
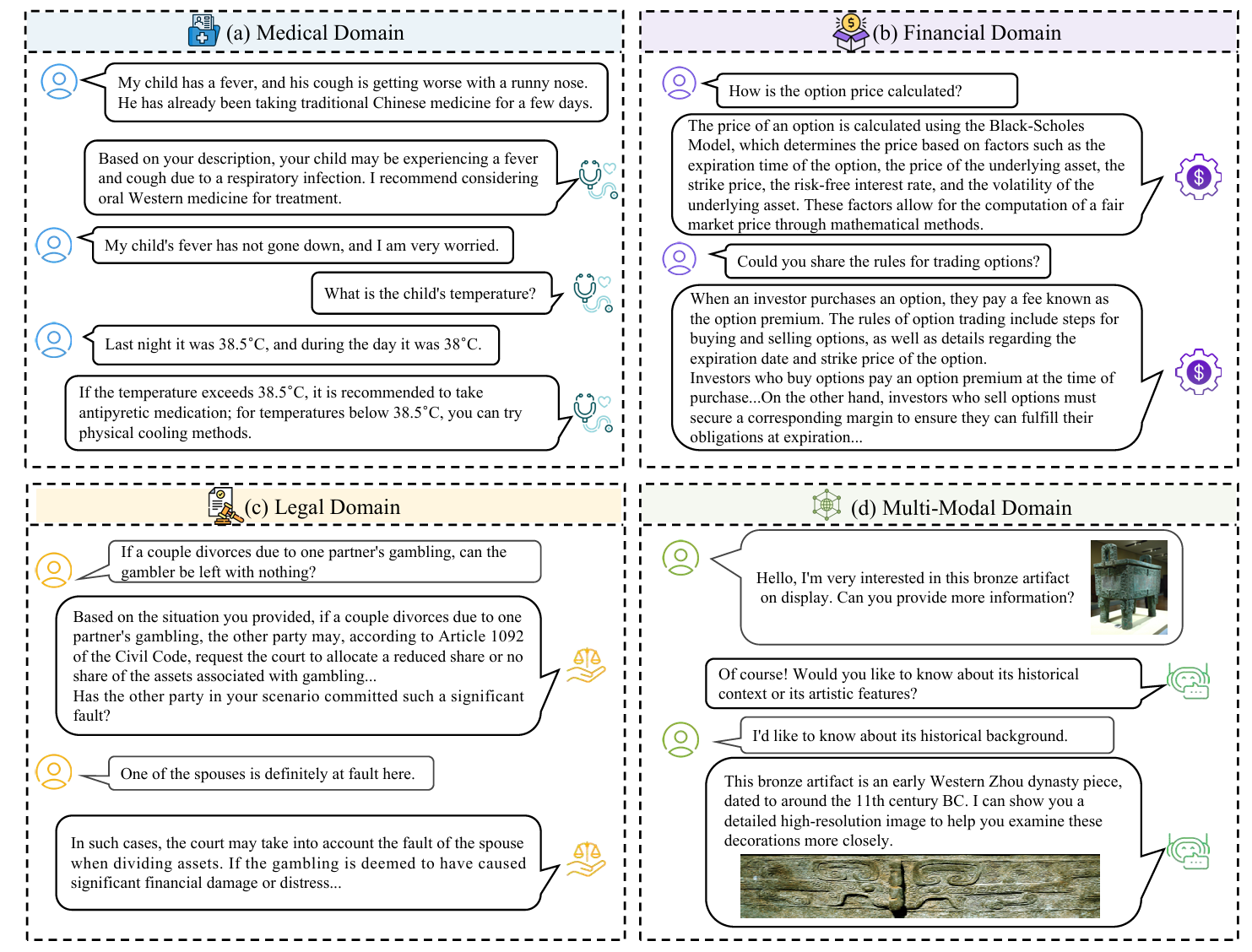
图8. 四个不同领域中对话式搜索系统的典型示例:(a) 医疗,(b) 金融,(c) 法律,和(d) 多模态。每个领域都需要特定的信息处理。
在医疗领域建立对话式搜索系统的常见做法是从对话界面中检索相关信息并提取相关医疗概念以生成响应[33],如图8(a)所示。医疗概念表达的多样性(即同一概念可能以多种非规范形式书写)对准确搜索具有相关概念的文本和建模对话上下文(特别是共指和省略)提出了挑战[34]。随着LLM的出现,医疗领域对话式搜索系统范式面临新的机遇和挑战[261, 267]。可用的医疗语料库[35, 36] 使得现有LLM能够持续训练以增强在相关领域的卓越能力。例如,Toma等人[37] 提出了一种开源专家级医疗语言模型,通过基于对话上下文编码知识。Bao等人[38] 基于对话和知识图谱构建高质量的监督微调数据集,以将LLM与现实世界的医疗咨询联系起来。然而,生成式LLM在返回准确响应方面仍然存在难以解决的问题,特别是当存储的知识过时时。为了缓解这些问题,Pal等人[39] 提出了医疗领域幻觉检测方法以减少LLM的不准确响应,Wang等人[40] 将搜索组件集成到医疗LLM中以帮助检索外部知识以更新支持证据,这表明领域检索比领域预训练更重要。然而,目前缺乏有效的方法来提高LLM在医疗环境中的准确性。考虑到与当地文化、历史、政治和区域背景高度相关的语言特定知识,医疗领域对话式搜索系统的另一个关键因素是进行多语言/跨语言信息检索[268, 269]。例如,与传统文化遗产紧密相连的中医形成了一个独特的医疗搜索系统[143, 270]。虽然翻译系统可以解决其中一些问题[41],但由于医学术语的复杂性和实现精确翻译的挑战,它可能效果不佳。因此,探索整合语言特定医疗知识和对话式搜索的基本机制是一个有前景且尚未探索的方向[42]。
6.1.2 金融领域
图8. 四个不同领域中对话式搜索系统的典型示例:(a) 医疗,(b) 金融,(c) 法律,和(d) 多模态。每个领域都需要特定的信息处理。
为了模拟现实场景,Sharma等人[43] 构建了一个演示,展示金融代理如何在对话场景下支持股票市场投资者,如图8(b)所示。为了开发复杂的金融领域信息系统并自动评估模型,后续研究专注于基于对话式问答任务构建数据集,并将金融信息存储在表格中[44, 45]。关键挑战在于从结构化数据中检索相关信息并通过多跳推理生成最终答案,然而,由于数据稀缺性,模型的性能仍然不尽如人意[46]。
凭借庞大的预训练语料库,LLM在推理能力上表现出色,但在金融领域仍然存在不足,特别是需要检索数值信息时[46]。为了解决这些问题,[47] 开发了一种基于LLM的金融领域对话式搜索模型,专门用于查询意图分类和知识库标注。然而,由于缺乏精确的指令和评估协议,该系统尚未经过全面的信息检索测试。Xie等人[48] 进一步提出了一个综合基准、指令数据集和金融领域的LLM,通过提供系统资源促进研究领域的发展。总体而言,数据集、评估协议和模型构建技术限制了金融系统的发展,以满足用户的特殊信息需求,这要求领域特定的对话搜索系统改进金融搜索并通过正确的检索信息增强响应生成[262]。
6.1.3 法律领域
图8. 四个不同领域中对话式搜索系统的典型示例:(a) 医疗,(b) 金融,(c) 法律,和(d) 多模态。每个领域都需要特定的信息处理。
由于其在社会中的特定影响,法律案例检索在信息检索社区中迅速受到关注,其目的是为给定查询案例搜索支持证据。然而,对于缺乏领域知识的用户来说,使用法律搜索系统具有挑战性,因为用户无法完全表达其特定的信息需求,如图8(c)所示。为此,Liu等人[49] 尝试将对话式搜索系统应用于法律案例检索,并证明其比传统方法更有效。这也归因于领域特定的语言现象,其中语言使用的系统模式(如某些会话含义理论所解释的)有时可以解释为什么法官以不同于字面意义的方式解释法律文本[50]。为了进一步提高系统性能,一系列研究解决了不同方面的问题,包括开发基于代理的决策机制[51, 144]、重排序长上下文响应[52]以及学习提出澄清问题(如第3.4.2节所述)。
6.1.4 其他领域
图8. 四个不同领域中对话式搜索系统的典型示例:(a) 医疗,(b) 金融,(c) 法律,和(d) 多模态。每个领域都需要特定的信息处理。
除了上述仅涉及文本数据的领域外,对话式搜索系统还促进了涉及不同数据形式的领域。例如,电子商务领域涉及各种商品属性和用户画像信息,需要分别处理商品搜索、偏好推荐和基于商品目录匹配、用户建模和商品相关知识理解的问答。最近的一些研究[53, 145, 146] 为混合搜索目标、实体检索和扩展广泛覆盖的对话语料库贡献了资源建设,使得进一步探索变得更加可行。此外,为了从多个资源中检索,Liao等人[147] 将对话会话扩展到多模态场景,需要文本和图像信息来解决下游任务。Li等人[148] 更强调搜索任务,并进一步将表格证据作为检索来源。图8(d)展示了一个典型示例。这一具有挑战性的任务增加了从不同模态检索的证据之间的对齐和推理难度,导致现有最先进方法的性能不尽如人意。为了解决这一问题,MOQAGPT [149] 提出了一种基于分治策略的方法,整合来自各种资源的排序结果。需要更多的研究来促进这一特定任务设置。
6.2 以用户为中心的对话式搜索
对话式搜索系统在各种场景中有效应用,以支持用户寻求信息。除了主要关注特定的预定义模型能力(如检索世界知识、跨候选证据推理等)外,一些现有研究[150] 专注于用户满意度的视角,即通过满足不同意图下的用户信息需求来提高用户满意度。这并非易事,因为明确请求用户的满意度反馈具有挑战性,并且传统信息检索中使用的方法尚未在对话式搜索背景下得到彻底研究。为了促进以用户为中心的对话式搜索研究,最近提出了一些基准[150, 263],用于从以用户为中心的视角评估系统,并研究如何构建主动式对话式搜索系统[151] 以及以人为中心的代理[152]。此外,一些现有研究[80, 153] 专注于混合主动交互,旨在通过多种反馈为用户提供更好的体验。因此,维护以用户为中心的系统对于确保这些技术在未来的发展中继续服务于用户的利益至关重要。另一条研究线尝试通过个性化搜索促进以用户为中心的对话系统,这需要在搜索候选文档时满足用户的信息需求并考虑其背景[10]。具体来说,系统对同一查询的搜索结果应根据用户配置文件生成不同的结果。主要挑战在于模型开发中的数据稀缺性问题。为此,Joko等人[154] 通过LLM合成了大规模个性化多会话对话式搜索数据集。Mo等人[155] 探索了如何以零样本方式将查询重写与个性化元素结合。最近的一些研究旨在定义具体场景并评估系统的个性化能力[10, 156]。随着数据资源的发展,预计会出现更复杂的个性化系统。
6.3 数据资源
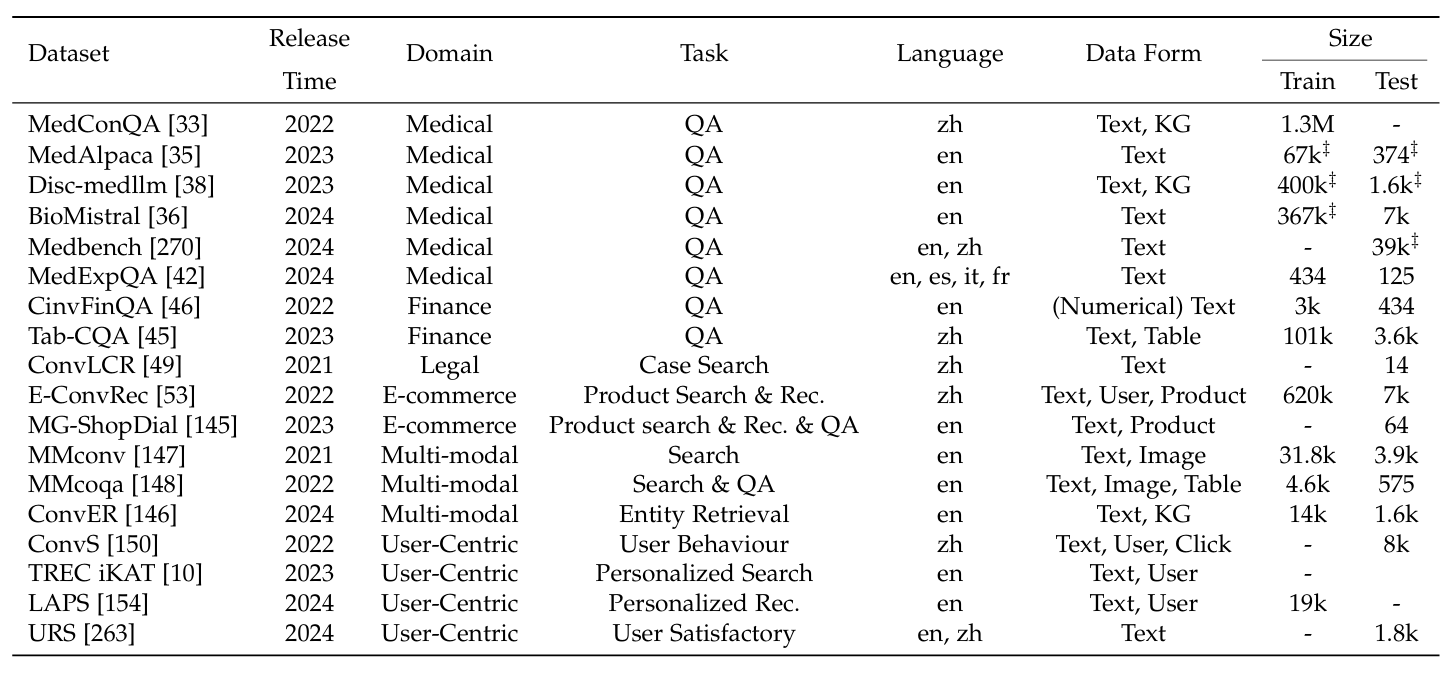
表1. 领域特定对话式搜索数据资源的概述和统计细节。‡表示包含与不同子任务相关的多个子集。
开发领域特定的对话式搜索系统的主要瓶颈在于数据稀缺性,这需要将知识资源注入模型或作为外部基础。此外,可用的基准对于评估系统在满足各领域需求方面的特定能力至关重要。据我们所知,我们在表1中展示了各领域数据资源的统计细节,这在一定程度上反映了每个特定领域的发展。这些数据资源为未来训练和评估更复杂的模型提供了可行性。
6.4 局限性与讨论
尽管在领域特定的对话式搜索方面做出了显著努力,但仍需进一步探索。我们对当前的局限性和潜在改进进行了简要讨论,如下所示。
数据整理:领域特定任务的主要挑战在于缺乏全面的文档库,这限制了模型训练和评估的可行性。与通用领域相比,领域特定数据的获取成本更高,因为需要标注者具备领域知识。因此,大规模资源对于领域特定开发是可取的,而自动数据生成技术(例如LLM辅助)可能是一个潜在的途径。
领域特定的信息检索:特定领域中使用的复杂术语增加了确保检索器与查询语义匹配的难度,特别是涉及当地文化、历史、政治和区域背景时。当用户缺乏专业知识并以不同方式表达术语进行查询时,这一问题可能变得尤为严重。一个潜在的解决方案是利用领域特定的LLM帮助重构查询,并通过考虑多因素进一步发展领域特定的搜索引擎。
可信性:在领域特定应用中,可靠的结果至关重要。例如,传播错误或欺骗性信息可能比其他领域带来更大的伦理和实践影响。检索和生成中的错误信息、虚假信息和幻觉增加了搜索系统返回可信答案的难度,这需要更多的研究。
7 基准与评估
一个完整且智能的对话式搜索系统应集成多个组件,包括查询重构、搜索澄清、对话式检索和响应生成等。由于对话式搜索系统具有灵活的交互界面,信息返回形式可能取决于特定查询,可以是相关文档的排序列表、它们的摘要、检索增强生成的响应等。现有对话式搜索系统的评估可分为两类[150]:1) 基于排序指标(如MRR、NDCG、Recall),或2) 基于语义相似性指标(如F1、BLUE和ROUGE),前者通常用于检索任务,而后者常用于生成任务。在本节中,我们首先介绍现有研究中评估的不同方面,并总结可用的基准。然后,我们讨论基于检索和基于评估的被忽视问题,并提出一些潜在的改进方向。
7.1 评估概述
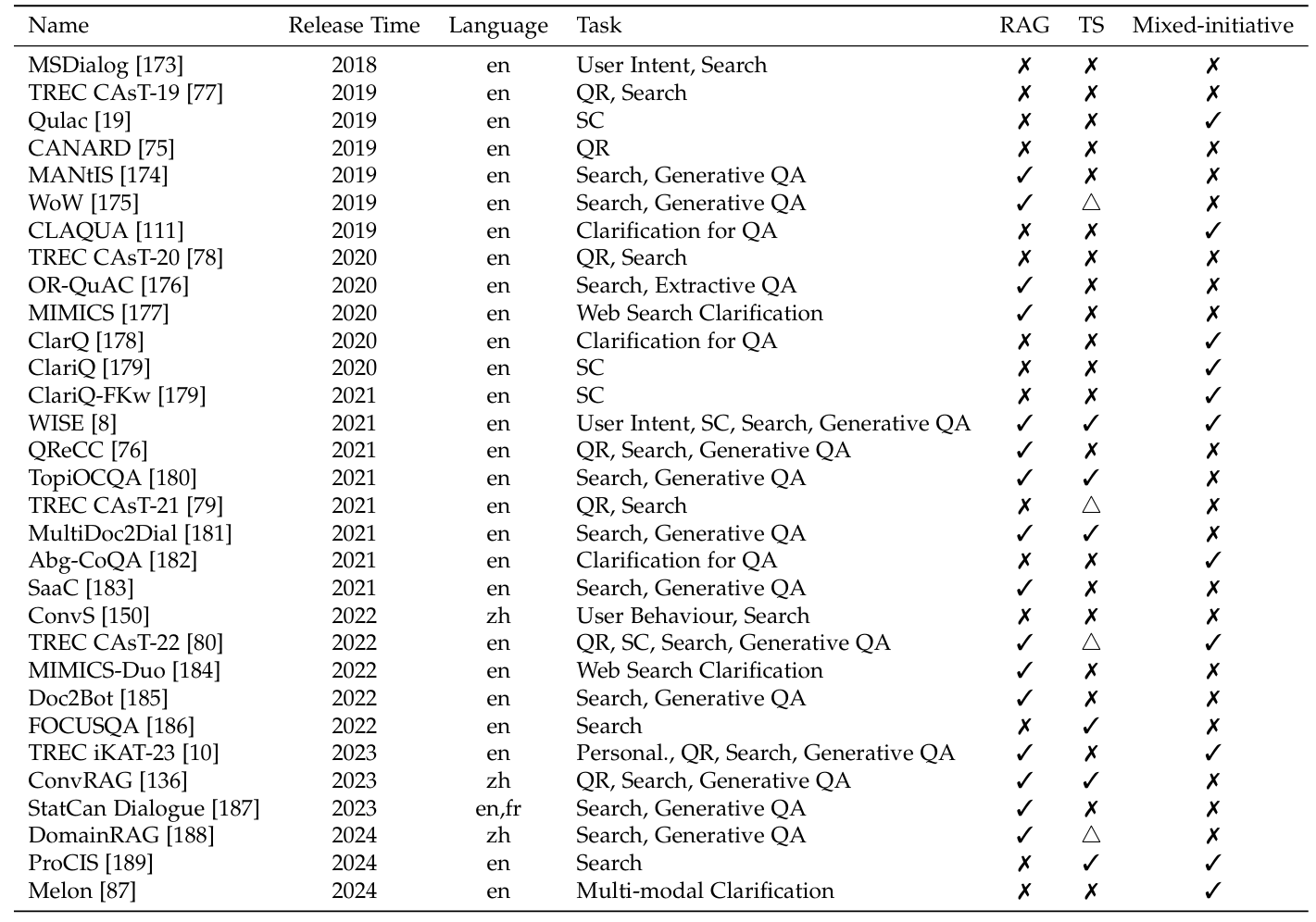
表2. 对话式搜索基准的概述,涵盖多种评估设置。QR、SC、QA和TS分别表示查询重构、搜索澄清、问答和话题切换。
现有对话式搜索基准的概述如表2所示,每个基准对应一个特定设置,例如是否需要生成最终答案(RAG)、是否涉及话题切换(TS)现象,或对话中的多反应目标(混合主动)。我们可以发现,在大语言模型时代(2021年后),用户迭代场景和RAG任务变得更加重要和流行。因此,与大多数关注结果准确性的单轮设置不同,从对话视角评估检索和生成任务的多个方面至关重要。
7.1.1 基于检索的评估
遵循传统的单轮即席检索,现有关于对话式检索的研究通常将会话中的每个查询轮次视为一个单独查询,并使用相应的相关性判断作为真实值。这是因为可用的对话式搜索数据集是从单轮数据集继承构建的。除了传统的即席搜索评估并关注对话特征外,Fu等人[157]基于用户满意度和观察到的搜索性能,检验了即席搜索中的评估模式是否存在于对话式搜索中。Li等人[158]和Siblini等人[159]认为,使用历史上下文中提供的真实答案的现有基准在评估实际人机对话模型时不可靠。为了模拟具有不可预测对话轨迹的开放式环境以应对实际情况,一系列研究利用用户模拟器为系统响应提供反馈。早期工作[160, 161]研究了如何基于用户模拟估计对话式搜索的有效性。随后,Wang等人[162]模拟了澄清用户问题的风险,并根据搜索体验开发了一个风险感知控制模型。为了进一步促进对话式搜索的用户反馈模拟,一些最新研究[163–166]开发了基于用户模拟器的框架,以构建更多用户-系统交互作为混合主动,通过特定用户反馈改进对话式搜索系统。此外,它还可用于评估混合主动对话式搜索系统[167]。混合主动系统的目标是丰富交互模式,可以在对话的任何时刻主动提出各种问题或建议,最终满足用户的信息需求。为了评估混合主动方面,Aliannejadi等人[206]分析了更具吸引力的对话式搜索的潜力以及由于更广泛的交互范围而难以评估的问题。为此,Sekulic等人[167]通过提出对话式用户模拟器实现了自动评估。此外,一些最新研究[168, 169]专注于分析系统主动性和用户行为的预测,为评估混合主动系统提供了新的视角。
7.1.2 基于生成的评估
灵活的用户-系统交互提供了通过多轮查询解决复杂信息需求的机会,这意味着用户的需求可能不仅是一个排序列表,还可能是一个从检索结果中提取的简洁答案。这种范式在LLMs时代变得尤为重要,使得基于生成的评估变得至关重要。然而,传统的指标如F1分数、BLEU分数和精确匹配(EM)可能无法完全捕捉生成的质量。一方面,一些合理且正确生成的答案可能未被标注为评估的黄金标准,从而在传统的词级别指标中失败。另一方面,尽管检索器不完美或存在语义相关的检索文本幻觉,LLMs仍能生成准确响应[253],这引发了同时考虑检索和生成来评估系统的问题。为了将检索到的文档整合为全面、相关且简洁的响应,Lajewska等人[171]为现有对话式搜索基准收集了片段级别的答案标注,以填补检索与生成之间的评估差距。为了提高检索有效性与生成过程性能的相关性,Salemi等人[170]提出了eRAG指标,该指标基于下游任务的真实标签评估每个检索文档的利用情况。然而,IR与RAG之间的评估差距仍然存在,即IR相关的文档可能对下游RAG任务无效[252]。因此,如何评估基于LLM的生成器中的检索器性能,并更好地将检索器-生成器与整体对话式搜索系统对齐,仍然是一个开放的挑战,需要进一步探索[172]。
7.2 局限性与讨论
尽管现有对话式搜索模型取得了显著发展,但这些系统的可信评估仍然是一个开放问题。主要挑战在于如何从以下几个方面进行评估,具体讨论如下。
对话导向的评估
现有对话式搜索系统的开发和评估基于传统的搜索指标,独立评估每个查询轮次。此外,当前基准假设前几轮回答正确以确保对话一致性[158],这在实际应用中并不现实。Samarinas和Zamani[189]首次尝试提出npDCG指标以及一个新的基准,从反应和主动两方面评估系统。用户模拟(基于LLMs)的探索试图使对话式系统评估更加现实和以用户为中心。预计需要更多评估指标和模拟器,以在对话级别评估系统并反映用户体验。
检索有效性评估
生成模型的发展要求系统在某些情况下基于搜索结果生成最终答案(如RAG)。然而,检索和生成的需求可能不一致,检索旨在解决检索集的相关性,而生成需要最大化检索结果对下游任务的效用。因此,需要新的评估协议来弥合检索结果与生成目标之间的有用性。潜在的解决方案是开发一些具有合适目标的确定机制,以在检索结果的基础上识别对生成器有用的部分。
混合主动评估
对话式界面使得返回形式更加灵活,可以是澄清问题、排序文档列表、直接/检索增强的精确响应等。因此,智能对话式搜索系统应能够确定合适的决策和信息生成形式,以返回给用户,这与文献中的混合主动评估一致[80]。尽管LLM代理[198, 271]具备基本的决策规划能力,但仍需要更精确的机制。主要挑战在于缺乏基准,以端到端的方式评估每个轮次操作对最终信息需求的有效性。一个可能的解决方案是首先开发一个基准,并提出用于评估操作预测准确性和信息寻求贡献的评估方法。
8 结论与未来方向
在本综述中,我们对对话式搜索系统进行了深入回顾,重点关注四个核心模块:查询重构、搜索澄清、对话式检索和响应生成。针对每个组件,我们回顾了当前的方法和进展,并讨论了未来发展的潜在方向。我们的大部分讨论集中在LLMs对对话式搜索系统各关键模块的影响上,探讨了LLMs如何集成并支持这些组件,为创新和性能提升提供了新的机遇和挑战。此外,我们还讨论了现有对话式搜索系统在以用户为中心、特定领域场景中的应用,提供了其实际用例的见解。我们总结了用于评估对话式搜索系统性能的可用基准资源和评估方法,并指出了向更实用评估技术改进的潜力。我们期望本综述能够展示现代对话式搜索所需的全景,并为这一快速发展的领域的未来研究提供坚实的基础。
为了未来开发更智能的对话式搜索系统,整体建议总结如下:
智能决策
与用户的交互中,系统返回的适当形式是保证良好搜索体验的关键。需要一个智能决策器来确定是否需要澄清、外部检索、额外响应生成等。一种替代方案是利用LLM代理完成复杂的决策任务,具备工具调用、高级记忆、推理和规划能力。挑战在于确保相关性和准确性、减少偏见、提供实时响应等。
可信且丰富的资源
可信性对搜索系统至关重要,这是生成式系统面临的开放挑战。关键问题是通过知识归因指示资源,确保生成内容对用户是可靠的响应。此外,为了使资源更加丰富,例如整合多模态信息,可以增加可信度并提高交互系统的结果多样性。
主动且个性化的对话
现有对话式搜索系统大多以被动方式运行,对每个查询轮次进行响应,直到用户终止搜索会话。更优的交互设计是主动行动,系统可以决定并参与对话。这也是混合主动交互的愿景,但目前缺乏训练和评估系统的数据。另一个重要元素是提供个性化搜索,这要求对话系统在每次查询时考虑用户档案中的适当方面,以帮助生成个性化内容作为最终响应。
面向实际评估
现有评估数据集基于一个强假设,即在处理当前轮次时,所有前几轮次都已正确回答。这与实际情况相去甚远,因为用户行为的改变会影响后续对话流程。为了解决这一开放挑战,一些努力旨在开发用户模拟器,以模拟真实场景进行实际评估。研究社区需要进一步探索基准开发和新的评估范式。
信息丰富的返回
随着对话式搜索系统的发展,返回的信息可能不仅限于澄清问题或生成的响应。它可能更强调信息形式和主动交互。例如,对话系统可以引导用户朝不同方向发展,例如调用外部工具处理请求[272],规划多步骤策略作为思维链解决信息需求[273],以及与协作环境进行代理信息检索[274]。关键思想是扩大可用资源和能力,帮助用户在对话中反思并最终满足其信息需求。
[1] Y. Zhu, H. Yuan, S. Wang, J. Liu, W. Liu, C. Deng, Z. Dou, and J. Wen, “Large language models for information retrieval: A survey,” CoRR, vol. abs/2308.07107, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2308.07107
[2] D. Li, Z. Sun, X. Hu, Z. Liu, Z. Chen, B. Hu, A. Wu, and M. Zhang, “A survey of large language models attribution,” CoRR, vol. abs/2311.03731, 2023. [Online]. Available: https://doi.org/10.48550/arXiv. 2311.03731
[3] J. S. Culpepper, F. Diaz, and M. D. Smucker, “Research frontiers in information retrieval: Report from the third strategic workshop on information retrieval in lorne (SWIRL 2018),” SIGIR Forum, vol. 52, no. 1, pp. 34–90, 2018. [Online]. Available: https://doi.org/10.1145/3274784.3274788
[4] K. Mao, Z. Dou, H. Qian, F. Mo, X. Cheng, and Z. Cao, “Convtrans: Transforming web search sessions for conversational dense retrieval,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Association for Computational Linguistics, 2022, pp. 2935–2946. [Online]. Available: https: //doi.org/10.18653/v1/2022.emnlp-main.190
[5] K. Mao, Z. Dou, H. Chen, F. Mo, and H. Qian, “Large language models know your contextual search intent: A prompting framework for conversational search,” CoRR, vol. abs/2303.06573, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2303.06573
[6] K. Mao, Z. Dou, B. Liu, H. Qian, F. Mo, X. Wu, X. Cheng, and Z. Cao, “Search-oriented conversational query editing,” in Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Association for Computational Linguistics, 2023, pp. 41604172. [Online]. Available: https://doi.org/10.18653/ v1/2023.findings-acl.256
[7] F. Mo, K. Mao, Y. Zhu, Y. Wu, K. Huang, and J. Nie, “Convgqr: Generative query reformulation for conversational search,” CoRR, vol. abs/2305.15645, 2023. [Online]. Available: https://doi.org/10.48550/ arXiv.2305.15645
[8] P. Ren, Z. Liu, X. Song, H. Tian, Z. Chen, Z. Ren, and M. de Rijke, “Wizard of search engine: Access to information through conversations with search engines,” CoRR, vol. abs/2105.08301, 2021. [Online]. Available: https://arxiv.org/abs/2105.08301
[9] Z. Wu, R. Parish, H. Cheng, S. Min, P. Ammanabrolu, M. Ostendorf, and H. Hajishirzi, “INSCIT: information-seeking conversations with mixed-initiative interactions,” CoRR, vol. abs/2207.00746, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2207.00746
[10] M. Aliannejadi, Z. Abbasiantaeb, S. Chatterjee, J. Dalton, and L. Azzopardi, “TREC ikat 2023: The interactive knowledge assistance track overview,” CoRR, vol. abs/2401.01330, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.01330
[11] V. Pyatkin, J. D. Hwang, V. Srikumar, X. Lu, L. Jiang, Y. Choi, and C. Bhagavatula, “Clarifydelphi: Reinforced clarification questions with defeasibility rewards for social and moral situations,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Association for Computational Linguistics, 2023, pp. 11 253–11 271. [Online]. Available: https: //doi.org/10.18653/v1/2023.acl-long.630
[12] F. Mu, L. Shi, S. Wang, Z. Yu, B. Zhang, C. Wang, S. Liu, and Q. Wang, “Clarifygpt: Empowering llmbased code generation with intention clarification,” CoRR, vol. abs/2310.10996, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.10996
[13] H. A. Rahmani, X. Wang, M. Aliannejadi, M. Naghiaei, and E. Yilmaz, “Clarifying the path to user satisfaction: An investigation into clarification usefulness,” CoRR, vol. abs/2402.01934, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.01934
[14] C. Gao, W. Lei, X. He, M. de Rijke, and T. Chua, “Advances and challenges in conversational recommender systems: A survey,” AI Open, vol. 2, pp. 100–126, 2021. [Online]. Available: https://doi.org/ 10.1016/j.aiopen.2021.06.002
[15] L. Wang, N. Yang, and F. Wei, “Query2doc: Query expansion with large language models,” CoRR, vol. abs/2303.07678, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2303.07678
[16] X. Ma, Y. Gong, P. He, H. Zhao, and N. Duan, “Query rewriting for retrieval-augmented large language models,” CoRR, vol. abs/2305.14283, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2305.14283
[17] S. Yu, J. Liu, J. Yang, C. Xiong, P. N. Bennett, J. Gao, and Z. Liu, “Few-shot generative conversational query rewriting,” CoRR, vol. abs/2006.05009, 2020. [Online]. Available: https://arxiv.org/abs/2006.05009
[18] K. Lin, K. Lo, J. Gonzalez, and D. Klein, “Decomposing complex queries for tip-of-thetongue retrieval,” in Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023, pp. 5521–5533. [Online]. Available: https: //doi.org/10.18653/v1/2023.findings-emnlp.367
[19] M. Aliannejadi, H. Zamani, F. Crestani, and W. B. Croft, “Asking clarifying questions in opendomain information-seeking conversations,” CoRR, vol. abs/1907.06554, 2019. [Online]. Available: http: //arxiv.org/abs/1907.06554
[20] D. Lee, S. Kim, M. Lee, H. Lee, J. Park, S. Lee, and K. Jung, “Asking clarification questions to handle ambiguity in open-domain QA,” CoRR, vol. abs/2305.13808, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2305.13808
[21] Y. Feng, H. A. Rahmani, A. Lipani, and E. Yilmaz, “Towards asking clarification questions for information seeking on task-oriented dialogues,” CoRR, vol. abs/2305.13690, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2305.13690
[22] C. Qu, L. Yang, C. Chen, M. Qiu, W. B. Croft, and M. Iyyer, “Open-retrieval conversational question answering,” CoRR, vol. abs/2005.11364, 2020. [Online]. Available: https://arxiv.org/abs/ 2005.11364
[23] S. Jeong, J. Baek, S. J. Hwang, and J. C. Park, “Phrase retrieval for open-domain conversational question answering with conversational dependency modeling via contrastive learning,” CoRR, vol. abs/2306.04293, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2306.04293
[24] K. Mao, Z. Dou, and H. Qian, “Curriculum contrastive context denoising for few-shot conversational dense retrieval,” in SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, E. Amigo ́ , P. Castells, J. Gonzalo, B. Carterette, J. S. Culpepper, and G. Kazai, Eds. ACM, 2022, pp. 176–186. [Online]. Available: https://doi.org/10.1145/3477495.3531961
[25] H. Chen, Z. Dou, K. Mao, J. Liu, and Z. Zhao, “Generalizing conversational dense retrieval via llm-cognition data augmentation,” CoRR, vol. abs/2402.07092, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.07092
[26] K. Mao, C. Deng, H. Chen, F. Mo, Z. Liu, T. Sakai, and Z. Dou, “Chatretriever: Adapting large language models for generalized and robust conversational dense retrieval,” CoRR, vol. abs/2404.13556, 2024. [Online]. Available: https://doi.org/10.48550/arXiv. 2404.13556
[27] F. Mo, C. Qu, K. Mao, T. Zhu, Z. Su, K. Huang, and J. Nie, “History-aware conversational dense retrieval,” CoRR, vol. abs/2401.16659, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.16659
[28] J. Ju, S. Lin, M. Tsai, and C. Wang, “Improving conversational passage re-ranking with view ensemble,” CoRR, vol. abs/2304.13290, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2304.13290
[29] H. Qian, P. Zhang, Z. Liu, K. Mao, and Z. Dou, “Memorag: Moving towards next-gen RAG via memory-inspired knowledge discovery,” CoRR, vol. abs/2409.05591, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2409.05591
[30] Y. Li, W. Li, and L. Nie, “Mmcoqa: Conversational question answering over text, tables, and images,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, S. Muresan, P. Nakov, and A. Villavicencio, Eds. Association for Computational Linguistics, 2022, pp. 4220–4231. [Online]. Available: https: //doi.org/10.18653/v1/2022.acl-long.290
[31] P. Zhang, Z. Liu, S. Xiao, N. Shao, Q. Ye, and Z. Dou, “Compressing lengthy context with ultragist,” CoRR, vol. abs/2405.16635, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2405.16635
[32] T. Gao, H. Yen, J. Yu, and D. Chen, “Enabling large language models to generate text with citations,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023, pp. 6465–6488. [Online]. Available: https://doi.org/10.18653/v1/2023.emnlp-main.398
[33] F. Xia, B. Li, Y. Weng, S. He, K. Liu, B. Sun, S. Li, and J. Zhao, “Medconqa: Medical conversational question answering system based on knowledge graphs,” in Proceedings of the The 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022 - System Demonstrations, Abu Dhabi, UAE, December 7-11, 2022, W. Che and E. Shutova, Eds. Association for Computational Linguistics, 2022, pp. 148–158. [Online]. Available: https://doi. org/10.18653/v1/2022.emnlp-demos.15
[34] R. Bhowmik, K. Stratos, and G. de Melo, “Fast and effective biomedical entity linking using a dual encoder,” CoRR, vol. abs/2103.05028, 2021. [Online]. Available: https://arxiv.org/abs/2103.05028
[35] T. Han, L. C. Adams, J. Papaioannou, P. Grundmann, T. Oberhauser, A. Lo ̈ ser, D. Truhn, and K. K. Bressem, “Medalpaca - an open-source collection of medical conversational AI models and training data,” CoRR, vol. abs/2304.08247, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2304.08247
[36] Y. Labrak, A. Bazoge, E. Morin, P. Gourraud, M. Rouvier, and R. Dufour, “Biomistral: A collection of open-source pretrained large language models for medical domains,” CoRR, vol. abs/2402.10373, 2024. [Online]. Available: https://doi.org/10.48550/arXiv. 2402.10373
[37] A. Toma, P. R. Lawler, J. Ba, R. G. Krishnan, B. B. Rubin, and B. Wang, “Clinical camel: An open-source expert-level medical language model with dialogue-based knowledge encoding,” CoRR, vol. abs/2305.12031, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2305.12031
[38] Z. Bao, W. Chen, S. Xiao, K. Ren, J. Wu, C. Zhong, J. Peng, X. Huang, and Z. Wei, “Discmedllm: Bridging general large language models and real-world medical consultation,” CoRR, vol. abs/2308.14346, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2308.14346
[39] L. K. Umapathi, A. Pal, and M. Sankarasubbu, “Med-halt: Medical domain hallucination test for large language models,” CoRR, vol. abs/2307.15343, 2023. [Online]. Available: https://doi.org/10.48550/ arXiv.2307.15343
[40] J. Wang, Z. Yang, Z. Yao, and H. Yu, “JMLR: joint medical LLM and retrieval training for enhancing reasoning and professional question answering capability,” CoRR, vol. abs/2402.17887, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.17887
[41] Y. Jin, M. Chandra, G. Verma, Y. Hu, M. D. Choudhury, and S. Kumar, “Better to ask in english: Cross-lingual evaluation of large language models for healthcare queries,” CoRR, vol. abs/2310.13132, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.13132
[42] I. Alonso, M. Oronoz, and R. Agerri, “Medexpqa: Multilingual benchmarking of large language models for medical question answering,” CoRR, vol. abs/2404.05590, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2404.05590
[43] S. Sharma, J. Brennan, and J. R. C. Nurse, “Stockbabble: A conversational financial agent to support stock market investors,” CoRR, vol. abs/2106.08298, 2021. [Online]. Available: https://arxiv.org/abs/2106.08298
[44] Y. Deng, W. Lei, W. Zhang, W. Lam, and T. Chua, “PACIFIC: towards proactive conversational question answering over tabular and textual data in finance,” CoRR, vol. abs/2210.08817, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2210.08817
[45] C. Liu, J. Li, and D. Xiong, “Tab-cqa: A tabular conversational question answering dataset on financial reports,” in Proceedings of the The 61st Annual Meeting of the Association for Computational Linguistics: Industry Track, ACL 2023, Toronto, Canada, July 9-14, 2023, S. Sitaram, B. B. Klebanov, and J. D. Williams, Eds. Association for Computational Linguistics, 2023, pp. 196–207. [Online]. Available: https://doi.org/10.18653/v1/2023.acl-industry.20
[46] Z. Chen, S. Li, C. Smiley, Z. Ma, S. Shah, and W. Y. Wang, “Convfinqa: Exploring the chain of numerical reasoning in conversational finance question answering,” CoRR, vol. abs/2210.03849, 2022. [Online]. Available: https://doi.org/10.48550/ arXiv.2210.03849
[47] S. Choi, W. Gazeley, S. H. Wong, and T. Li, “Conversational financial information retrieval model (confirm),” CoRR, vol. abs/2310.13001, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.13001
[48] Q. Xie, W. Han, X. Zhang, Y. Lai, M. Peng, A. LopezLira, and J. Huang, “PIXIU: A comprehensive benchmark, instruction dataset and large language model for finance,” in Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., 2023. [Online]. Available: http: //papers.nips.cc/paper files/paper/2023/hash/ 6a386d703b50f1cf1f61ab02a15967bb-Abstract-Datasets and Benchmarks.html
[49] B. Liu, Y. Wu, Y. Liu, F. Zhang, Y. Shao, C. Li, M. Zhang, and S. Ma, “Conversational vs traditional: Comparing search behavior and outcome in legal case retrieval,” in SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, F. Diaz, C. Shah, T. Suel, P. Castells, R. Jones, and T. Sakai, Eds. ACM, 2021, pp. 1622–1626. [Online]. Available: https://doi.org/10.1145/3404835.3463064
[50] B. G. Slocum, “Conversational implicatures and legal texts,” Ratio juris: An international journal of jurisprudence and philosophy of law, vol. 29, no. 1, pp. 23–43, 2016.
[51] B. Liu, Y. Hu, Y. Wu, Y. Liu, F. Zhang, C. Li, M. Zhang, S. Ma, and W. Shen, “Investigating conversational agent action in legal case retrieval,” in Advances in Information Retrieval - 45th European Conference on Information Retrieval, ECIR 2023, Dublin, Ireland, April 2-6, 2023, Proceedings, Part I, ser. Lecture Notes in Computer Science, J. Kamps, L. Goeuriot, F. Crestani, M. Maistro, H. Joho, B. Davis, C. Gurrin, U. Kruschwitz, and A. Caputo, Eds., vol. 13980. Springer, 2023, pp. 622–635. [Online]. Available: https://doi.org/10.1007/978-3-031-28244-7 39
[52] A. Askari, M. Aliannejadi, A. Abolghasemi, E. Kanoulas, and S. Verberne, “Closer: Conversational legal longformer with expertise-aware passage response ranker for long contexts,” in Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, CIKM 2023, Birmingham, United Kingdom, October 21-25, 2023, I. Frommholz, F. Hopfgartner, M. Lee, M. Oakes, M. Lalmas, M. Zhang, and R. L. T. Santos, Eds. ACM, 2023, pp. 25–35. [Online]. Available: https://doi.org/10.1145/3583780.3614812
[53] M. Jia, R. Liu, P. Wang, Y. Song, Z. Xi, H. Li, X. Shen, M. Chen, J. Pang, and X. He, “E-convrec: A large-scale conversational recommendation dataset for e-commerce customer service,” in Proceedings of the Thirteenth Language Resources and Evaluation Conference, LREC 2022, Marseille, France, 20-25 June 2022, N. Calzolari, F. B ́echet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, J. Odijk, and S. Piperidis, Eds. European Language Resources Association, 2022, pp. 5787–5796. [Online]. Available: https://aclanthology.org/2022.lrec-1.622
[54] H. Zamani, J. R. Trippas, J. Dalton, and F. Radlinski, “Conversational information seeking,” Found. Trends Inf. Retr., vol. 17, no. 3-4, pp. 244–456, 2023. [Online]. Available: https://doi.org/10.1561/1500000081
[55] J. Gao, C. Xiong, P. Bennett, and N. Craswell, Neural Approaches to Conversational Information Retrieval, ser. The Information Retrieval Series. Springer, 2023, vol. 44. [Online]. Available: https://doi.org/10.1007/ 978-3-031-23080-6
[56] K. Keyvan and J. X. Huang, “How to approach ambiguous queries in conversational search: A survey of techniques, approaches, tools, and challenges,” ACM Comput. Surv., vol. 55, no. 6, pp. 129:1–129:40, 2023. [Online]. Available: https://doi.org/10.1145/ 3534965
[57] P. Schneider, W. Poelman, M. Rovatsos, and F. Matthes, “Engineering conversational search systems: A review of applications, architectures, and functional components,” CoRR, vol. abs/2407.00997, 2024. [Online]. Available: https://doi.org/10.48550/ arXiv.2407.00997
[58] V. Kumar and J. Callan, “Making information seeking easier: An improved pipeline for conversational search,” in Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020, ser. Findings of ACL, T. Cohn, Y. He, and Y. Liu, Eds., vol. EMNLP 2020. Association for Computational Linguistics, 2020, pp. 3971–3980. [Online]. Available: https://doi.org/10.18653/v1/ 2020.findings-emnlp.354
[59] N. Voskarides, D. Li, P. Ren, E. Kanoulas, and M. de Rijke, “Query resolution for conversational search with limited supervision,” CoRR, vol. abs/2005.11723, 2020. [Online]. Available: https://arxiv.org/abs/2005.11723
[60] S. Lin, J. Yang, and J. Lin, “Contextualized query embeddings for conversational search,” CoRR, vol. abs/2104.08707, 2021. [Online]. Available: https: //arxiv.org/abs/2104.08707
[61] I. Mele, C. I. Muntean, F. M. Nardini, R. Perego, N. Tonellotto, and O. Frieder, “Topic propagation in conversational search,” CoRR, vol. abs/2004.14054, 2020. [Online]. Available: https://arxiv.org/abs/2004. 14054
[62] F. Mo, J. Nie, K. Huang, K. Mao, Y. Zhu, P. Li, and Y. Liu, “Learning to relate to previous turns in conversational search,” CoRR, vol. abs/2306.02553, 2023. [Online]. Available: https://doi.org/10.48550/ arXiv.2306.02553
[63] S. Yu, J. Liu, J. Yang, C. Xiong, P. N. Bennett, J. Gao, and Z. Liu, “Few-shot generative conversational query rewriting,” CoRR, vol. abs/2006.05009, 2020. [Online]. Available: https://arxiv.org/abs/2006.05009
[64] S. Lin, J. Yang, R. F. Nogueira, M. Tsai, C. Wang, and J. Lin, “Conversational question reformulation via sequence-to-sequence architectures and pretrained language models,” CoRR, vol. abs/2004.01909, 2020. [Online]. Available: https://arxiv.org/abs/2004.01909
[65] S. Vakulenko, S. Longpre, Z. Tu, and R. Anantha, “Question rewriting for conversational question answering,” CoRR, vol. abs/2004.14652, 2020. [Online]. Available: https://arxiv.org/abs/2004.14652
[66] M. D. Tredici, G. Barlacchi, X. Shen, W. Cheng, and A. de Gispert, “Question rewriting for opendomain conversational QA: best practices and limitations,” in CIKM ’21: The 30th ACM International Conference on Information and Knowledge Management, Virtual Event, Queensland, Australia, November 1 5, 2021, G. Demartini, G. Zuccon, J. S. Culpepper, Z. Huang, and H. Tong, Eds. ACM, 2021, pp. 2974–2978. [Online]. Available: https://doi.org/10. 1145/3459637.3482164
[67] S. Vakulenko, N. Voskarides, Z. Tu, and S. Longpre, “A comparison of question rewriting methods for conversational passage retrieval,” CoRR, vol. abs/2101.07382, 2021. [Online]. Available: https: //arxiv.org/abs/2101.07382
[68] Z. Wu, Y. Luan, H. Rashkin, D. Reitter, and G. S. Tomar, “CONQRR: conversational query rewriting for retrieval with reinforcement learning,” CoRR, vol. abs/2112.08558, 2021. [Online]. Available: https://arxiv.org/abs/2112.08558
[69] Z. Chen, J. Zhao, A. Fang, B. Fetahu, O. Rokhlenko, and S. Malmasi, “Reinforced question rewriting for conversational question answering,” CoRR, vol. abs/2210.15777, 2022. [Online]. Available: https: //doi.org/10.48550/arXiv.2210.15777
[70] H. Qian and Z. Dou, “Explicit query rewriting for conversational dense retrieval,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Association for Computational Linguistics, 2022, pp. 4725–4737. [Online]. Available: https://doi.org/10. 18653/v1/2022.emnlp-main.311
[71] F. Ye, M. Fang, S. Li, and E. Yilmaz, “Enhancing conversational search: Large language model-aided informative query rewriting,” CoRR, vol. abs/2310.09716, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.09716
[72] Y. Jang, K. Lee, H. Bae, S. Won, H. Lee, and K. Jung, “Itercqr: Iterative conversational query reformulation without human supervision,” CoRR, vol. abs/2311.09820, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2311.09820
[73] C. Yoon, G. Kim, B. Jeon, S. Kim, Y. Jo, and J. Kang, “Ask optimal questions: Aligning large language models with retriever’s preference in conversational search,” CoRR, vol. abs/2402.11827, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.11827
[74] F. Mo, A. Ghaddar, K. Mao, M. Rezagholizadeh, B. Chen, Q. Liu, and J. Nie, “CHIQ: contextual history enhancement for improving query rewriting in conversational search,” CoRR, vol. abs/2406.05013, 2024. [Online]. Available: https://doi.org/10.48550/ arXiv.2406.05013
[75] A. Elgohary, D. Peskov, and J. L. Boyd-Graber, “Can you unpack that? learning to rewrite questionsin-context,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, K. Inui, J. Jiang, V. Ng, and X. Wan, Eds. Association for Computational Linguistics, 2019, pp. 5917–5923. [Online]. Available: https://doi.org/10.18653/v1/D19-1605
[76] R. Anantha, S. Vakulenko, Z. Tu, S. Longpre, S. Pulman, and S. Chappidi, “Open-domain question answering goes conversational via question rewriting,” CoRR, vol. abs/2010.04898, 2020. [Online]. Available: https://arxiv.org/abs/2010.04898
[77] J. Dalton, C. Xiong, and J. Callan, “TREC cast 2019: The conversational assistance track overview,” CoRR, vol. abs/2003.13624, 2020. [Online]. Available: https://arxiv.org/abs/2003.13624
[78] ——, “TREC cast 2019: The conversational assistance track overview,” CoRR, vol. abs/2003.13624, 2020. [Online]. Available: https://arxiv.org/abs/2003.13624
[79] ——, “TREC cast 2021: The conversational assistance track overview,” in Proceedings of the Thirtieth Text REtrieval Conference, TREC 2021, online, November 15-19, 2021, ser. NIST Special Publication, I. Soboroff and A. Ellis, Eds., vol. 500-335. National Institute of Standards and Technology (NIST), 2021. [Online]. Available: https://trec.nist.gov/pubs/ trec30/papers/Overview-CAsT.pdf
[80] P. Owoicho, J. Dalton, M. Aliannejadi, L. Azzopardi, J. R. Trippas, and S. Vakulenko, “TREC cast 2022: Going beyond user ask and system retrieve with initiative and response generation,” in Proceedings of the Thirty-First Text REtrieval Conference, TREC 2022, online, November 15-19, 2022, ser. NIST Special Publication, I. Soboroff and A. Ellis, Eds., vol. 500-338. National Institute of Standards and Technology (NIST), 2022. [Online]. Available: https://trec.nist. gov/pubs/trec31/papers/Overview cast.pdf
[81] H. Hashemi, H. Zamani, and W. B. Croft, “Guided transformer: Leveraging multiple external sources for representation learning in conversational search,” CoRR, vol. abs/2006.07548, 2020. [Online]. Available: https://arxiv.org/abs/2006.07548
[82] K. Bi, Q. Ai, and W. B. Croft, “Asking clarifying questions based on negative feedback in conversational search,” CoRR, vol. abs/2107.05760, 2021. [Online]. Available: https://arxiv.org/abs/2107.05760
[83] Y. Mass, D. Cohen, A. Yehudai, and D. Konopnicki, “Conversational search with mixed-initiative - asking good clarification questions backed-up by passage retrieval,” CoRR, vol. abs/2112.07308, 2021. [Online]. Available: https://arxiv.org/abs/2112.07308
[84] I. Sekulic, M. Aliannejadi, and F. Crestani, “Towards facet-driven generation of clarifying questions for conversational search,” in ICTIR ’21: The 2021 ACM SIGIR International Conference on the Theory of Information Retrieval, Virtual Event, Canada, July 11, 2021, F. Hasibi, Y. Fang, and A. Aizawa, Eds. ACM, 2021, pp. 167–175. [Online]. Available: https://doi.org/10.1145/3471158.3472257
[85] Z. Wang, Y. Tu, C. Rosset, N. Craswell, M. Wu, and Q. Ai, “Zero-shot clarifying question generation for conversational search,” CoRR, vol. abs/2301.12660, 2023. [Online]. Available: https://doi.org/10.48550/ arXiv.2301.12660
[86] Z. Wang, Z. Xu, Q. Ai, and V. Srikumar, “An in-depth investigation of user response simulation for conversational search,” CoRR, vol. abs/2304.07944, 2023. [Online]. Available: https://doi.org/10.48550/ arXiv.2304.07944
[87] Y. Yuan, C. Siro, M. Aliannejadi, M. de Rijke, and W. Lam, “Asking multimodal clarifying questions in mixed-initiative conversational search,” CoRR, vol. abs/2402.07742, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2402.07742
[88] H. Zamani, S. T. Dumais, N. Craswell, P. N. Bennett, and G. Lueck, “Generating clarifying questions for information retrieval,” in WWW ’20: The Web Conference 2020, Taipei, Taiwan, April 20-24, 2020, Y. Huang, I. King, T. Liu, and M. van Steen, Eds. ACM / IW3C2, 2020, pp. 418–428. [Online]. Available: https://doi.org/10.1145/3366423.3380126
[89] H. Zamani, B. Mitra, E. Chen, G. Lueck, F. Diaz, P. N. Bennett, N. Craswell, and S. T. Dumais, “Analyzing and learning from user interactions for search clarification,” CoRR, vol. abs/2006.00166, 2020. [Online]. Available: https://arxiv.org/abs/2006.00166
[90] J. Wang and W. Li, “Template-guided clarifying question generation for web search clarification,” in CIKM ’21: The 30th ACM International Conference on Information and Knowledge Management, Virtual Event, Queensland, Australia, November 1 - 5, 2021, G. Demartini, G. Zuccon, J. S. Culpepper, Z. Huang, and H. Tong, Eds. ACM, 2021, pp. 3468–3472. [Online]. Available: https://doi.org/10.1145/3459637.3482199
[91] Z. Zhao, Z. Dou, J. Mao, and J. Wen, “Generating clarifying questions with web search results,” in SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, E. Amigo ́ , P. Castells, J. Gonzalo, B. Carterette, J. S. Culpepper, and G. Kazai, Eds. ACM, 2022, pp. 234–244. [Online]. Available: https://doi.org/10.1145/3477495.3531981
[92] Z. Zhao, Z. Dou, Y. Guo, Z. Cao, and X. Cheng, “Improving search clarification with structured information extracted from search results,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2023, Long Beach, CA, USA, August 6-10, 2023, A. K. Singh, Y. Sun, L. Akoglu, D. Gunopulos, X. Yan, R. Kumar, F. Ozcan, and J. Ye, Eds. ACM, 2023, pp. 3549–3558. [Online]. Available: https://doi.org/10.1145/3580305.3599389
[93] Z. Dou, S. Hu, Y. Luo, R. Song, and J. Wen, “Finding dimensions for queries,” in Proceedings of the 20th ACM Conference on Information and Knowledge Management, CIKM 2011, Glasgow, United Kingdom, October 24-28, 2011, C. Macdonald, I. Ounis, and I. Ruthven, Eds. ACM, 2011, pp. 1311–1320. [Online]. Available: https://doi.org/10.1145/2063576.2063767
[94] W. Kong and J. Allan, “Extracting query facets from search results,” in The 36th International ACM SIGIR conference on research and development in Information Retrieval, SIGIR ’13, Dublin, Ireland - July 28 - August 01, 2013, G. J. F. Jones, P. Sheridan, D. Kelly, M. de Rijke, and T. Sakai, Eds. ACM, 2013, pp. 93–102. [Online]. Available: https://doi.org/10.1145/2484028.2484097
[95] ——, “Extending faceted search to the general web,” in Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, CIKM 2014, Shanghai, China, November 3-7, 2014, J. Li, X. S. Wang, M. N. Garofalakis, I. Soboroff, T. Suel, and M. Wang, Eds. ACM, 2014, pp. 839–848. [Online]. Available: https://doi.org/10. 1145/2661829.2661964
[96] H. Hashemi, H. Zamani, and W. B. Croft, “Learning multiple intent representations for search queries,” in CIKM ’21: The 30th ACM International Conference on Information and Knowledge Management, Virtual Event, Queensland, Australia, November 1 - 5, 2021, G. Demartini, G. Zuccon, J. S. Culpepper, Z. Huang, and H. Tong, Eds. ACM, 2021, pp. 669–679. [Online]. Available: https://doi.org/10.1145/3459637.3482445
[97] ——, “Stochastic optimization of text set generation for learning multiple query intent representations,” in Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, October 17-21, 2022, M. A. Hasan and L. Xiong, Eds. ACM, 2022, pp. 4003–4008. [Online]. Available: https://doi.org/10.1145/3511808.3557666
[98] C. Samarinas, A. Dharawat, and H. Zamani, “Revisiting open domain query facet extraction and generation,” in ICTIR ’22: The 2022 ACM SIGIR International Conference on the Theory of Information Retrieval, Madrid, Spain, July 11 - 12, 2022, F. Crestani, G. Pasi, and ́E. Gaussier, Eds. ACM, 2022, pp. 43–50. [Online]. Available: https://doi.org/10.1145/3539813.3545138
[99] O. Litvinov, I. Sekulic, M. Aliannejadi, and F. Crestani, “Analyzing coherency in facet-based clarification prompt generation for search,” CoRR, vol. abs/2401.04524, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.04524
[100] Z. Zhao and Z. Dou, “Generating multi-turn clarification for web information seeking,” in Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, May 13-17, 2024, T. Chua, C. Ngo, R. Kumar, H. W. Lauw, and R. K. Lee, Eds. ACM, 2024, pp. 1539–1548. [Online]. Available: https://doi.org/10.1145/3589334.3645712
[101] S. Ni, K. Bi, J. Guo, and X. Cheng, “A comparative study of training objectives for clarification facet generation,” CoRR, vol. abs/2310.00703, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.00703
[102] J. Lee and J. Kim, “Enhanced facet generation with LLM editing,” CoRR, vol. abs/2403.16345, 2024. [Online]. Available: https://doi.org/10.48550/arXiv. 2403.16345
[103] W. Liu, Z. Zhao, Y. Zhu, and Z. Dou, “Mining exploratory queries for conversational search,” in Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, May 13-17, 2024, T. Chua, C. Ngo, R. Kumar, H. W. Lauw, and R. K. Lee, Eds. ACM, 2024, pp. 1386–1394. [Online]. Available: https://doi.org/10.1145/3589334.3645424
[104] I. Sekulic, M. Aliannejadi, and F. Crestani, “User engagement prediction for clarification in search,” CoRR, vol. abs/2102.04163, 2021. [Online]. Available: https://arxiv.org/abs/2102.04163
[105] T. Lotze, S. Klut, M. Aliannejadi, and E. Kanoulas, “Ranking clarifying questions based on predicted user engagement,” CoRR, vol. abs/2103.06192, 2021. [Online]. Available: https://arxiv.org/abs/2103.06192
[106] C. Gao and W. Lam, “Search clarification selection via query-intent-clarification graph attention,” in Advances in Information Retrieval - 44th European Conference on IR Research, ECIR 2022, Stavanger, Norway, April 10-14, 2022, Proceedings, Part I, ser. Lecture Notes in Computer Science, M. Hagen, S. Verberne, C. Macdonald, C. Seifert, K. Balog, K. Nørv ̊ag, and V. Setty, Eds., vol. 13185. Springer, 2022, pp. 230–243. [Online]. Available: https://doi. org/10.1007/978-3-030-99736-6 16
[107] S. Rao and H. D. III, “Learning to ask good questions: Ranking clarification questions using neural expected value of perfect information,” CoRR, vol. abs/1805.04655, 2018. [Online]. Available: http://arxiv.org/abs/1805.04655
[108] ——, “Answer-based adversarial training for generating clarification questions,” CoRR, vol. abs/1904.02281, 2019. [Online]. Available: http: //arxiv.org/abs/1904.02281
[109] J. Trienes and K. Balog, “Identifying unclear questions in community question answering websites,” CoRR, vol. abs/1901.06168, 2019. [Online]. Available: http: //arxiv.org/abs/1901.06168
[110] V. Kumar, V. Raunak, and J. Callan, “Ranking clarification questions via natural language inference,” CoRR, vol. abs/2008.07688, 2020. [Online]. Available: https://arxiv.org/abs/2008.07688
[111] J. Xu, Y. Wang, D. Tang, N. Duan, P. Yang, Q. Zeng, M. Zhou, and X. Sun, “Asking clarification questions in knowledge-based question answering,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, K. Inui, J. Jiang, V. Ng, and X. Wan, Eds. Association for Computational Linguistics, 2019, pp. 1618–1629. [Online]. Available: https://doi.org/10.18653/v1/D19-1172
[112] Y. Nakano, S. Kawano, K. Yoshino, K. Sudoh, and S. Nakamura, “Pseudo ambiguous and clarifying questions based on sentence structures toward clarifying question answering system,” in Proceedings of the Second DialDoc Workshop on Document-grounded Dialogue and Conversational Question Answering, DialDoc@ACL 2022, Dublin, Ireland, May 26, 2022, S. Feng, H. Wan, C. Yuan, and H. Yu, Eds. Association for Computational Linguistics, 2022, pp. 31–40. [Online]. Available: https://doi.org/10.18653/ v1/2022.dialdoc-1.4
[113] G. Kim, S. Kim, B. Jeon, J. Park, and J. Kang, “Tree of clarifications: Answering ambiguous questions with retrieval-augmented large language models,” CoRR, vol. abs/2310.14696, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.14696
[114] B. Z. Li, A. Tamkin, N. D. Goodman, and J. Andreas, “Eliciting human preferences with language models,” CoRR, vol. abs/2310.11589, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.11589
[115] C. Andukuri, J. Fr ̈anken, T. Gerstenberg, and N. D. Goodman, “Star-gate: Teaching language models to ask clarifying questions,” CoRR, vol. abs/2403.19154, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2403.19154
[116] Y. Deng, W. Zhang, Z. Chen, and Q. Gu, “Rephrase and respond: Let large language models ask better questions for themselves,” CoRR, vol. abs/2311.04205, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2311.04205
[117] C. Qu, L. Yang, M. Qiu, Y. Zhang, C. Chen, W. B. Croft, and M. Iyyer, “Attentive history selection for conversational question answering,” CoRR, vol. abs/1908.09456, 2019. [Online]. Available: http://arxiv.org/abs/1908.09456
[118] N. L. Hai, T. Gerald, T. Formal, J. Nie, B. Piwowarski, and L. Soulier, “Cosplade: Contextualizing SPLADE for conversational information retrieval,” CoRR, vol. abs/2301.04413, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2301.04413
[119] Y. Li, W. Li, and L. Nie, “A graph-guided multi-round retrieval method for conversational open-domain question answering,” CoRR, vol. abs/2104.08443, 2021. [Online]. Available: https://arxiv.org/abs/ 2104.08443
[120] ——, “Dynamic graph reasoning for conversational open-domain question answering,” ACM Trans. Inf. Syst., vol. 40, no. 4, pp. 82:1–82:24, 2022. [Online]. Available: https://doi.org/10.1145/3498557
[121] Z. Pan, H. Luo, M. Li, and H. Liu, “Conv-coa: Improving open-domain question answering in large language models via conversational chain-of-action,” CoRR, vol. abs/2405.17822, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2405.17822
[122] S. Yu, Z. Liu, C. Xiong, T. Feng, and Z. Liu, “Few-shot conversational dense retrieval,” CoRR, vol. abs/2105.04166, 2021. [Online]. Available: https://arxiv.org/abs/2105.04166
[123] A. M. Krasakis, A. Yates, and E. Kanoulas, “Zero-shot query contextualization for conversational search,” CoRR, vol. abs/2204.10613, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2204.10613
[124] F. Mo, C. Qu, K. Mao, Y. Wu, Z. Su, K. Huang, and J. Nie, “Aligning query representation with rewritten query and relevance judgments in conversational search,” CoRR, vol. abs/2407.20189, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2407.20189
[125] S. Lin, J. Yang, and J. Lin, “Contextualized query embeddings for conversational search,” CoRR, vol. abs/2104.08707, 2021. [Online]. Available: https: //arxiv.org/abs/2104.08707
[126] Z. Jin, P. Cao, Y. Chen, K. Liu, and J. Zhao, “Instructor: Instructing unsupervised conversational dense retrieval with large language models,” in Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 610, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023, pp. 6649–6675. [Online]. Available: https: //doi.org/10.18653/v1/2023.findings-emnlp.443
[127] S. Kim and G. Kim, “Saving dense retriever from shortcut dependency in conversational search,” CoRR, vol. abs/2202.07280, 2022. [Online]. Available: https://arxiv.org/abs/2202.07280
[128] K. Mao, Z. Dou, H. Qian, F. Mo, X. Cheng, and Z. Cao, “Convtrans: Transforming web search sessions for conversational dense retrieval,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Association for Computational Linguistics, 2022, pp. 2935–2946. [Online]. Available: https: //doi.org/10.18653/v1/2022.emnlp-main.190
[129] F. Mo, B. Yi, K. Mao, C. Qu, K. Huang, and J. Nie, “Convsdg: Session data generation for conversational search,” CoRR, vol. abs/2403.11335, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2403.11335
[130] C. Huang, C. Hsu, T. Hsu, C. Li, and Y. Chen, “CONVERSER: few-shot conversational dense retrieval with synthetic data generation,” CoRR, vol. abs/2309.06748, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309.06748
[131] K. Mao, H. Qian, F. Mo, Z. Dou, B. Liu, X. Cheng, and Z. Cao, “Learning denoised and interpretable session representation for conversational search,” in Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April 2023 4 May 2023, Y. Ding, J. Tang, J. F. Sequeda, L. Aroyo, C. Castillo, and G. Houben, Eds. ACM, 2023, pp. 3193–3202. [Online]. Available: https://doi.org/10.1145/3543507.3583265
[132] P. Christmann, R. S. Roy, and G. Weikum, “Explainable conversational question answering over heterogeneous sources via iterative graph neural networks,” CoRR, vol. abs/2305.01548, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2305.01548
[133] Y. Cheng, K. Mao, and Z. Dou, “Interpreting conversational dense retrieval by rewritingenhanced inversion of session embedding,” CoRR, vol. abs/2402.12774, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.12774
[134] S. Kongyoung, C. Macdonald, and I. Ounis, “monoqa: Multi-task learning of reranking and answer extraction for open-retrieval conversational question answering,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Association for Computational Linguistics, 2022, pp. 7207–7218. [Online]. Available: https://doi.org/10.18653/v1/2022.emnlp-main.485
[135] P. Owoicho, I. Sekulic, M. Aliannejadi, J. Dalton, and F. Crestani, “Exploiting simulated user feedback for conversational search: Ranking, rewriting, and beyond,” CoRR, vol. abs/2304.13874, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2304.13874
[136] L. Ye, Z. Lei, J. Yin, Q. Chen, J. Zhou, and L. He, “Boosting conversational question answering with fine-grained retrieval-augmentation and selfcheck,” in Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024, G. H. Yang, H. Wang, S. Han, C. Hauff, G. Zuccon, and Y. Zhang, Eds. ACM, 2024, pp. 2301–2305. [Online]. Available: https://doi.org/10.1145/3626772.3657980
[137] F. Mo, J. Nie, K. Huang, K. Mao, Y. Zhu, P. Li, and Y. Liu, “Learning to relate to previous turns in conversational search,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2023, Long Beach, CA, USA, August 6-10, 2023, A. K. Singh, Y. Sun, L. Akoglu, D. Gunopulos, X. Yan, R. Kumar, F. Ozcan, and J. Ye, Eds. ACM, 2023, pp. 1722–1732. [Online]. Available: https://doi.org/10.1145/3580305.3599411
[138] K. Mao, H. Qian, F. Mo, Z. Dou, B. Liu, X. Cheng, and Z. Cao, “Learning denoised and interpretable session representation for conversational search,” in Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April 2023 4 May 2023, Y. Ding, J. Tang, J. F. Sequeda, L. Aroyo, C. Castillo, and G. Houben, Eds. ACM, 2023, pp. 3193–3202. [Online]. Available: https://doi.org/10.1145/3543507.3583265
[139] F. Mo, C. Qu, K. Mao, T. Zhu, Z. Su, K. Huang, and J. Nie, “History-aware conversational dense retrieval,” CoRR, vol. abs/2401.16659, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.16659
[140] R. Nakano, J. Hilton, S. Balaji, J. Wu, L. Ouyang, C. Kim, C. Hesse, S. Jain, V. Kosaraju, W. Saunders, X. Jiang, K. Cobbe, T. Eloundou, G. Krueger, K. Button, M. Knight, B. Chess, and J. Schulman, “Webgpt: Browser-assisted question-answering with human feedback,” CoRR, vol. abs/2112.09332, 2021. [Online]. Available: https://arxiv.org/abs/2112.09332
[141] R. Thoppilan, D. D. Freitas, J. Hall, N. Shazeer, A. Kulshreshtha, H.-T. Cheng, A. Jin, T. Bos, L. Baker, Y. Du, Y. Li, H. Lee, H. S. Zheng, A. Ghafouri, M. Menegali, Y. Huang, M. Krikun, D. Lepikhin, J. Qin, D. Chen, Y. Xu, Z. Chen, A. Roberts, M. Bosma, Y. Zhou, C.-C. Chang, I. Krivokon, W. Rusch, M. Pickett, K. S. Meier-Hellstern, M. R. Morris, T. Doshi, R. D. Santos, T. Duke, J. Soraker, B. Zevenbergen, V. Prabhakaran, M. Diaz, B. Hutchinson, K. Olson, A. Molina, E. Hoffman-John, J. Lee, L. Aroyo, R. Rajakumar, A. Butryna, M. Lamm, V. Kuzmina, J. Fenton, A. Cohen, R. Bernstein, R. Kurzweil, B. A. y Arcas, C. Cui, M. Croak, E. H. Chi, and Q. Le, “Lamda: Language models for dialog applications,” CoRR, vol. abs/2201.08239, 2022.
[142] H. Qian, Y. Zhu, Z. Dou, H. Gu, X. Zhang, Z. Liu, R. Lai, Z. Cao, J.-Y. Nie, and J.-R. Wen, “Webbrain: Learning to generate factually correct articles for queries by grounding on large web corpus,” CoRR, vol. abs/2304.04358, 2023.
[143] S. Yang, H. Zhao, S. Zhu, G. Zhou, H. Xu, Y. Jia, and H. Zan, “Zhongjing: Enhancing the chinese medical capabilities of large language model through expert feedback and real-world multi-turn dialogue,” CoRR, vol. abs/2308.03549, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2308.03549
[144] B. Liu, Y. Wu, F. Zhang, Y. Liu, Z. Wang, C. Li, M. Zhang, and S. Ma, “Query generation and buffer mechanism: Towards a better conversational agent for legal case retrieval,” Inf. Process. Manag., vol. 59, no. 5, p. 103051, 2022. [Online]. Available: https://doi.org/10.1016/j.ipm.2022.103051
[145] N. Bernard and K. Balog, “Mg-shopdial: A multigoal conversational dataset for e-commerce,” CoRR, vol. abs/2304.12636, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2304.12636
[146] M. Zamiri, Y. Qiang, F. Nikolaev, D. Zhu, and A. Kotov, “Benchmark and neural architecture for conversational entity retrieval from a knowledge graph,” in Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, May 13-17, 2024, T. Chua, C. Ngo, R. Kumar, H. W. Lauw, and R. K. Lee, Eds. ACM, 2024, pp. 1519–1528. [Online]. Available: https://doi.org/10.1145/3589334.3645676
[147] L. Liao, L. H. Long, Z. Zhang, M. Huang, and T. Chua, “Mmconv: An environment for multimodal conversational search across multiple domains,” in SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, F. Diaz, C. Shah, T. Suel, P. Castells, R. Jones, and T. Sakai, Eds. ACM, 2021, pp. 675–684. [Online]. Available: https://doi.org/10.1145/3404835.3462970
[148] Y. Li, W. Li, and L. Nie, “Mmcoqa: Conversational question answering over text, tables, and images,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, S. Muresan, P. Nakov, and A. Villavicencio, Eds. Association for Computational Linguistics, 2022, pp. 4220–4231. [Online]. Available: https: //doi.org/10.18653/v1/2022.acl-long.290
[149] L. Zhang, Y. Wu, F. Mo, J. Nie, and A. Agrawal, “Moqagpt : Zero-shot multi-modal open-domain question answering with large language model,” CoRR, vol. abs/2310.13265, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.13265
[150] Z. Chu, Z. Wang, Y. Liu, Y. Huang, M. Zhang, and S. Ma, “Convsearch: A open-domain conversational search behavior dataset,” CoRR, vol. abs/2204.02659, 2022. [Online]. Available: https://doi.org/10.48550/ arXiv.2204.02659
[151] P. Erbacher, J. Nie, P. Preux, and L. Soulier, “PAQA: toward proactive open-retrieval question answering,” CoRR, vol. abs/2402.16608, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.16608
[152] Y. Deng, L. Liao, Z. Zheng, G. H. Yang, and T. Chua, “Towards human-centered proactive conversational agents,” CoRR, vol. abs/2404.12670, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2404.12670
[153] S. Yan, S. Song, J. Li, S. Meng, and G. Hu, “TITAN : Task-oriented dialogues with mixedinitiative interactions,” in Proceedings of the ThirtySecond International Joint Conference on Artificial Intelligence, IJCAI 2023, 19th-25th August 2023, Macao, SAR, China. ijcai.org, 2023, pp. 5251–5259. [Online]. Available: https://doi.org/10.24963/ijcai.2023/583
[154] H. Joko, S. Chatterjee, A. Ramsay, A. P. de Vries, J. Dalton, and F. Hasibi, “Doing personal LAPS: llmaugmented dialogue construction for personalized multi-session conversational search,” CoRR, vol. abs/2405.03480, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2405.03480
[155] F. Mo, L. Zhao, K. Huang, Y. Dong, D. Huang, and J. Nie, “How to leverage personal textual knowledge for personalized conversational information retrieval,” CoRR, vol. abs/2407.16192, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2407.16192
[156] Y. Deng, X. Zhang, W. Zhang, Y. Yuan, S. Ng, and T. Chua, “On the multi-turn instruction following for conversational web agents,” CoRR, vol. abs/2402.15057, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2402.15057
[157] X. Fu, E. Yilmaz, and A. Lipani, “Evaluating the cranfield paradigm for conversational search systems,” in ICTIR ’22: The 2022 ACM SIGIR International Conference on the Theory of Information Retrieval, Madrid, Spain, July 11 - 12, 2022, F. Crestani, G. Pasi, and ́E. Gaussier, Eds. ACM, 2022, pp. 275280. [Online]. Available: https://doi.org/10.1145/ 3539813.3545126
[158] H. Li, T. Gao, M. Goenka, and D. Chen, “Ditch the gold standard: Re-evaluating conversational question answering,” CoRR, vol. abs/2112.08812, 2021. [Online]. Available: https://arxiv.org/abs/ 2112.08812
[159] W. Siblini, B. Sayil, and Y. Kessaci, “Towards a more robust evaluation for conversational question answering,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 2: Short Papers), Virtual Event, August 1-6, 2021, C. Zong, F. Xia, W. Li, and R. Navigli, Eds. Association for Computational Linguistics, 2021, pp. 1028–1034. [Online]. Available: https://doi.org/10.18653/v1/2021.acl-short.130
[160] A. Salle, S. Malmasi, O. Rokhlenko, and E. Agichtein, “Studying the effectiveness of conversational search refinement through user simulation,” in Advances in Information Retrieval - 43rd European Conference on IR Research, ECIR 2021, Virtual Event, March 28 - April 1, 2021, Proceedings, Part I, ser. Lecture Notes in Computer Science, D. Hiemstra, M. Moens, J. Mothe, R. Perego, M. Potthast, and F. Sebastiani, Eds., vol. 12656. Springer, 2021, pp. 587–602. [Online]. Available: https://doi.org/10.1007/978-3-030-72113-8 39
[161] A. Lipani, B. Carterette, and E. Yilmaz, “How am I doing?: Evaluating conversational search systems offline,” ACM Trans. Inf. Syst., vol. 39, no. 4, pp. 51:1–51:22, 2021. [Online]. Available: https://doi.org/10.1145/3451160
[162] Z. Wang and Q. Ai, “Simulating and modeling the risk of conversational search,” ACM Trans. Inf. Syst., vol. 40, no. 4, pp. 85:1–85:33, 2022. [Online]. Available: https://doi.org/10.1145/3507357
[163] Z. Wang, Z. Xu, Q. Ai, and V. Srikumar, “An in-depth investigation of user response simulation for conversational search,” CoRR, vol. abs/2304.07944, 2023. [Online]. Available: https://doi.org/10.48550/ arXiv.2304.07944
[164] P. Owoicho, I. Sekulic, M. Aliannejadi, J. Dalton, and F. Crestani, “Exploiting simulated user feedback for conversational search: Ranking, rewriting, and beyond,” CoRR, vol. abs/2304.13874, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2304.13874
[165] K. Balog and C. Zhai, “User simulation for evaluating information access systems,” CoRR, vol. abs/2306.08550, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2306.08550
[166] N. Bernard, “Leveraging user simulation to develop and evaluate conversational information access agents,” CoRR, vol. abs/2312.08041, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2312.08041
[167] I. Sekulic, M. Aliannejadi, and F. Crestani, “Evaluating mixed-initiative conversational search systems via user simulation,” CoRR, vol. abs/2204.08046, 2022. [Online]. Available: https://doi.org/10.48550/arXiv. 2204.08046
[168] C. Meng, M. Aliannejadi, and M. de Rijke, “System initiative prediction for multi-turn conversational information seeking,” in Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, CIKM 2023, Birmingham, United Kingdom, October 21-25, 2023, I. Frommholz, F. Hopfgartner, M. Lee, M. Oakes, M. Lalmas, M. Zhang, and R. L. T. Santos, Eds. ACM, 2023, pp. 1807–1817. [Online]. Available: https://doi.org/10.1145/3583780.3615070
[169] X. Fu and A. Lipani, “Priming and actions: An analysis in conversational search systems,” in Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2023, Taipei, Taiwan, July 2327, 2023, H. Chen, W. E. Duh, H. Huang, M. P. Kato, J. Mothe, and B. Poblete, Eds. ACM, 2023, pp. 2277–2281. [Online]. Available: https://doi.org/10.1145/3539618.3592041
[170] A. Salemi and H. Zamani, “Evaluating retrieval quality in retrieval-augmented generation,” CoRR, vol. abs/2404.13781, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2404.13781
[171] W. Lajewska and K. Balog, “Towards filling the gap in conversational search: From passage retrieval to conversational response generation,” CoRR, vol. abs/2308.08911, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2308.08911
[172] A. Alinejad, K. Kumar, and A. Vahdat, “Evaluating the retrieval component in llm-based question answering systems,” CoRR, vol. abs/2406.06458, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2406.06458
[173] C. Qu, L. Yang, W. B. Croft, J. R. Trippas, Y. Zhang, and M. Qiu, “Analyzing and characterizing user intent in information-seeking conversations,” CoRR, vol. abs/1804.08759, 2018. [Online]. Available: http://arxiv.org/abs/1804.08759
[174] G. Penha, A. Balan, and C. Hauff, “Introducing mantis: a novel multi-domain information seeking dialogues dataset,” CoRR, vol. abs/1912.04639, 2019. [Online]. Available: http://arxiv.org/abs/1912.04639
[175] E. Dinan, S. Roller, K. Shuster, A. Fan, M. Auli, and J. Weston, “Wizard of wikipedia: Knowledge-powered conversational agents,” CoRR, vol. abs/1811.01241, 2018. [Online]. Available: http://arxiv.org/abs/1811. 01241
[176] C. Qu, L. Yang, C. Chen, M. Qiu, W. B. Croft, and M. Iyyer, “Open-retrieval conversational question answering,” CoRR, vol. abs/2005.11364, 2020. [Online]. Available: https://arxiv.org/abs/ 2005.11364
[177] H. Zamani, G. Lueck, E. Chen, R. Quispe, F. Luu, and N. Craswell, “MIMICS: A large-scale data collection for search clarification,” CoRR, vol. abs/2006.10174, 2020. [Online]. Available: https://arxiv.org/abs/2006. 10174
[178] V. Kumar and A. W. Black, “Clarq: A large-scale and diverse dataset for clarification question generation,” CoRR, vol. abs/2006.05986, 2020. [Online]. Available: https://arxiv.org/abs/2006.05986
[179] M. Aliannejadi, J. Kiseleva, A. Chuklin, J. Dalton, and M. Burtsev, “Convai3: Generating clarifying questions for open-domain dialogue systems (clariq),” CoRR, vol. abs/2009.11352, 2020. [Online]. Available: https://arxiv.org/abs/2009.11352
[180] V. Adlakha, S. Dhuliawala, K. Suleman, H. de Vries, and S. Reddy, “Topiocqa: Opendomain conversational question answering with topic switching,” Trans. Assoc. Comput. Linguistics, vol. 10, pp. 468–483, 2022. [Online]. Available: https://doi.org/10.1162/tacl a 00471
[181] S. Feng, S. S. Patel, H. Wan, and S. Joshi, “Multidoc2dial: Modeling dialogues grounded in multiple documents,” CoRR, vol. abs/2109.12595, 2021. [Online]. Available: https://arxiv.org/abs/ 2109.12595
[182] M. Guo, M. Zhang, S. Reddy, and M. Alikhani, “Abg-coqa: Clarifying ambiguity in conversational question answering,” in 3rd Conference on Automated Knowledge Base Construction, AKBC 2021, Virtual, October 4-8, 2021, D. Chen, J. Berant, A. McCallum, and S. Singh, Eds., 2021. [Online]. Available: https://doi.org/10.24432/C5F30Z
[183] P. Ren, Z. Chen, Z. Ren, E. Kanoulas, C. Monz, and M. de Rijke, “Conversations with search engines: Serp-based conversational response generation,” ACM Trans. Inf. Syst., vol. 39, no. 4, pp. 47:1–47:29, 2021. [Online]. Available: https://doi.org/10.1145/ 3432726
[184] L. Tavakoli, J. R. Trippas, H. Zamani, F. Scholer, and M. Sanderson, “Mimics-duo: Offline & online evaluation of search clarification,” CoRR, vol. abs/2206.04417, 2022. [Online]. Available: https: //doi.org/10.48550/arXiv.2206.04417
[185] H. Fu, Y. Zhang, H. Yu, J. Sun, F. Huang, L. Si, Y. Li, and C. Nguyen, “Doc2bot: Accessing heterogeneous documents via conversational bots,” CoRR, vol. abs/2210.11060, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2210.11060
[186] G. Barlacchi, I. Lauriola, A. Moschitti, M. D. Tredici, X. Shen, T. Vu, B. Byrne, and A. de Gispert, “Focusqa: Open-domain question answering with a context in focus,” in Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Association for Computational Linguistics, 2022, pp. 5195–5208. [Online]. Available: https://doi.org/10. 18653/v1/2022.findings-emnlp.381
[187] X. H. Lu, S. Reddy, and H. de Vries, “The statcan dialogue dataset: Retrieving data tables through conversations with genuine intents,” CoRR, vol. abs/2304.01412, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2304.01412
[188] S. Wang, X. Yu, M. Wang, W. Chen, Y. Zhu, and Z. Dou, “Richrag: Crafting rich responses for multifaceted queries in retrieval-augmented generation,” CoRR, vol. abs/2406.12566, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2406.12566
[189] C. Samarinas and H. Zamani, “Procis: A benchmark for proactive retrieval in conversations,” CoRR, vol. abs/2405.06460, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2405.06460
[190] K. S. Jones, S. Walker, and S. E. Robertson, “A probabilistic model of information retrieval: development and comparative experiments - part 1,” Inf. Process. Manag., vol. 36, no. 6, pp. 779–808, 2000. [Online]. Available: https://doi.org/10.1016/ S0306-4573(00)00015-7
[191] V. Gupta and A. Dixit, “Recent query reformulation approaches for information retrieval system-a survey,” Recent Advances in Computer Science and Communications (Formerly: Recent Patents on Computer Science), vol. 16, no. 1, pp. 94–107, 2023.
[192] C. Carpineto, R. de Mori, G. Romano, and B. Bigi, “An information-theoretic approach to automatic query expansion,” ACM Trans. Inf. Syst., vol. 19, no. 1, pp. 1–27, 2001. [Online]. Available: https://doi.org/10.1145/366836.366860
[193] R. F. Nogueira and K. Cho, “Task-oriented query reformulation with reinforcement learning,” CoRR, vol. abs/1704.04572, 2017. [Online]. Available: http: //arxiv.org/abs/1704.04572
[194] W. Tannebaum and A. Rauber, “Acquiring lexical knowledge from query logs for query expansion in patent searching,” in Sixth IEEE International Conference on Semantic Computing, ICSC 2012, Palermo, Italy, September 19-21, 2012. IEEE Computer Society, 2012, pp. 336–338. [Online]. Available: https://doi. org/10.1109/ICSC.2012.15
[195] S. Lin, J. Yang, R. F. Nogueira, M. Tsai, C. Wang, and J. Lin, “Multi-stage conversational passage retrieval: An approach to fusing term importance estimation and neural query rewriting,” ACM Trans. Inf. Syst., vol. 39, no. 4, pp. 48:1–48:29, 2021. [Online]. Available: https://doi.org/10.1145/3446426
[196] G. Cao, J. Nie, J. Gao, and S. Robertson, “Selecting good expansion terms for pseudorelevance feedback,” in Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2008, Singapore, July 20-24, 2008, S. Myaeng, D. W. Oard, F. Sebastiani, T. Chua, and M. Leong, Eds. ACM, 2008, pp. 243–250. [Online]. Available: https://doi.org/10.1145/1390334.1390377
[197] B. He and I. Ounis, “Finding good feedback documents,” in Proceedings of the 18th ACM Conference on Information and Knowledge Management, CIKM 2009, Hong Kong, China, November 2-6, 2009, D. W. Cheung, I. Song, W. W. Chu, X. Hu, and J. Lin, Eds. ACM, 2009, pp. 2011–2014. [Online]. Available: https://doi.org/10.1145/1645953.1646289
[198] P. Gong, J. Li, and J. Mao, “Cosearchagent: A lightweight collaborative search agent with large language models,” CoRR, vol. abs/2402.06360, 2024. [Online]. Available: https://doi.org/10.48550/arXiv. 2402.06360
[199] S. Avula, B. Choi, and J. Arguello, “Why and when: Understanding system initiative during conversational collaborative search,” arXiv preprint arXiv:2303.13484, 2023.
[200] X. Wang, S. MacAvaney, C. Macdonald, and I. Ounis, “Generative query reformulation for effective adhoc search,” arXiv preprint arXiv:2308.00415, 2023.
[201] E. Zhang, X. Wang, P. Gong, Y. Lin, and J. Mao, “Usimagent: Large language models for simulating search users,” in Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 2687–2692.
[202] B. Engelmann, T. Breuer, J. I. Friese, P. Schaer, and N. Fuhr, “Context-driven interactive query simulations based on generative large language models,” in European Conference on Information Retrieval. Springer, 2024, pp. 173–188.
[203] A. M. Krasakis, M. Aliannejadi, N. Voskarides, and E. Kanoulas, “Analysing the effect of clarifying questions on document ranking in conversational search,” CoRR, vol. abs/2008.03717, 2020. [Online]. Available: https://arxiv.org/abs/2008.03717
[204] C. L. A. Clarke, N. Craswell, and E. M. Voorhees, “Overview of the TREC 2012 web track,” in Proceedings of The Twenty-First Text REtrieval Conference, TREC 2012, Gaithersburg, Maryland, USA, November 6-9, 2012, ser. NIST Special Publication, E. M. Voorhees and L. P. Buckland, Eds., vol. 500-298. National Institute of Standards and Technology (NIST), 2012. [Online]. Available: http://trec.nist. gov/pubs/trec21/papers/WEB12.overview.pdf
[205] M. Aliannejadi, J. Kiseleva, A. Chuklin, J. Dalton, and M. Burtsev, “Building and evaluating opendomain dialogue corpora with clarifying questions,” CoRR, vol. abs/2109.05794, 2021. [Online]. Available: https://arxiv.org/abs/2109.05794
[206] M. Aliannejadi, L. Azzopardi, H. Zamani, E. Kanoulas, P. Thomas, and N. Craswell, “Analysing mixed initiatives and search strategies during conversational search,” CoRR, vol. abs/2109.05955, 2021. [Online]. Available: https://arxiv.org/abs/2109.05955
[207] I. Sekulic, W. Lajewska, K. Balog, and F. Crestani, “Estimating the usefulness of clarifying questions and answers for conversational search,” CoRR, vol. abs/2401.11463, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2401.11463
[208] P. Braslavski, D. Savenkov, E. Agichtein, and A. Dubatovka, “What do you mean exactly?: Analyzing clarification questions in CQA,” in Proceedings of the 2017 Conference on Conference Human Information Interaction and Retrieval, CHIIR 2017, Oslo, Norway, March 7-11, 2017, R. Nordlie, N. Pharo, L. Freund, B. Larsen, and D. Russel, Eds. ACM, 2017, pp. 345–348. [Online]. Available: https://doi.org/10.1145/3020165.3022149
[209] L. Tavakoli, “Generating clarifying questions in conversational search systems,” in CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Virtual Event, Ireland, October 19-23, 2020, M. d’Aquin, S. Dietze, C. Hauff, E. Curry, and P. Cudr ́e-Mauroux, Eds. ACM, 2020, pp. 3253–3256. [Online]. Available: https: //doi.org/10.1145/3340531.3418513
[210] L. Tavakoli, H. Zamani, F. Scholer, W. B. Croft, and M. Sanderson, “Analyzing clarification in asynchronous information-seeking conversations,” J. Assoc. Inf. Sci. Technol., vol. 73, no. 3, pp. 449–471, 2022. [Online]. Available: https://doi.org/10.1002/ asi.24562
[211] D. G. Bridge, “Towards conversational recommender systems: A dialogue grammar approach,” in 6th European Conference ov Case Based Reasoning, ECCBR 2002, Aberdeen, Scotland, UK, September 4-7, 2002, Workshop Proceedings, 2002, pp. 9–22.
[212] R. Li, S. E. Kahou, H. Schulz, V. Michalski, L. Charlin, and C. Pal, “Towards deep conversational recommendations,” CoRR, vol. abs/1812.07617, 2018. [Online]. Available: http://arxiv.org/abs/1812.07617
[213] C. Yan, J. Bai, Y. Wang, W. Rong, Y. Ouyang, and Z. Xiong, “Goal-oriented conditional variational autoencoders for proactive and knowledge-aware conversational recommender system,” Comput. Speech Lang., vol. 79, p. 101468, 2023. [Online]. Available: https://doi.org/10.1016/j.csl.2022.101468
[214] Q. Chen, J. Lin, Y. Zhang, M. Ding, Y. Cen, H. Yang, and J. Tang, “Towards knowledgebased recommender dialog system,” CoRR, vol. abs/1908.05391, 2019. [Online]. Available: http: //arxiv.org/abs/1908.05391
[215] K. Zhou, Y. Zhou, W. X. Zhao, X. Wang, and J. Wen, “Towards topic-guided conversational recommender system,” CoRR, vol. abs/2010.04125, 2020. [Online]. Available: https://arxiv.org/abs/2010.04125
[216] K. Zhou, W. X. Zhao, S. Bian, Y. Zhou, J. Wen, and J. Yu, “Improving conversational recommender systems via knowledge graph based semantic fusion,” CoRR, vol. abs/2007.04032, 2020. [Online]. Available: https://arxiv.org/abs/2007.04032
[217] W. Lei, G. Zhang, X. He, Y. Miao, X. Wang, L. Chen, and T. Chua, “Interactive path reasoning on graph for conversational recommendation,” CoRR, vol. abs/2007.00194, 2020. [Online]. Available: https://arxiv.org/abs/2007.00194
[218] W. Lei, X. He, Y. Miao, Q. Wu, R. Hong, M. Kan, and T. Chua, “Estimation-action-reflection: Towards deep interaction between conversational and recommender systems,” CoRR, vol. abs/2002.09102, 2020. [Online]. Available: https://arxiv.org/abs/2002.09102
[219] Y. Deng, Y. Li, F. Sun, B. Ding, and W. Lam, “Unified conversational recommendation policy learning via graph-based reinforcement learning,” CoRR, vol. abs/2105.09710, 2021. [Online]. Available: https: //arxiv.org/abs/2105.09710
[220] Y. Zhang, L. Wu, Q. Shen, Y. Pang, Z. Wei, F. Xu, B. Long, and J. Pei, “Multiple choice questions based multi-interest policy learning for conversational recommendation,” in WWW ’22: The ACM Web Conference 2022, Virtual Event, Lyon, France, April 25 - 29, 2022, F. Laforest, R. Troncy, E. Simperl, D. Agarwal, A. Gionis, I. Herman, and L. Me ́dini, Eds. ACM, 2022, pp. 2153–2162. [Online]. Available: https://doi.org/10.1145/3485447.3512088
[221] L. Friedman, S. Ahuja, D. Allen, Z. Tan, H. Sidahmed, C. Long, J. Xie, G. Schubiner, A. Patel, H. Lara, B. Chu, Z. Chen, and M. Tiwari, “Leveraging large language models in conversational recommender systems,” CoRR, vol. abs/2305.07961, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2305.07961
[222] X. Wang, X. Tang, W. X. Zhao, J. Wang, and J. Wen, “Rethinking the evaluation for conversational recommendation in the era of large language models,” CoRR, vol. abs/2305.13112, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2305.13112
[223] D. Jannach, A. Manzoor, W. Cai, and L. Chen, “A survey on conversational recommender systems,” CoRR, vol. abs/2004.00646, 2020. [Online]. Available: https://arxiv.org/abs/2004.00646
[224] C. Gao, W. Lei, X. He, M. de Rijke, and T. Chua, “Advances and challenges in conversational recommender systems: A survey,” AI Open, vol. 2, pp. 100–126, 2021. [Online]. Available: https://doi.org/ 10.1016/j.aiopen.2021.06.002
[225] W. Lei, X. He, M. de Rijke, and T. Chua, “Conversational recommendation: Formulation, methods, and evaluation,” in Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, J. X. Huang, Y. Chang, X. Cheng, J. Kamps, V. Murdock, J. Wen, and Y. Liu, Eds. ACM, 2020, pp. 2425–2428. [Online]. Available: https://doi.org/10.1145/3397271.3401419
[226] B. Liu, Y. Hu, Q. Ai, Y. Liu, Y. Wu, C. Li, and W. Shen, “Leveraging event schema to ask clarifying questions for conversational legal case retrieval,” in Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, CIKM 2023, Birmingham, United Kingdom, October 21-25, 2023, I. Frommholz, F. Hopfgartner, M. Lee, M. Oakes, M. Lalmas, M. Zhang, and R. L. T. Santos, Eds. ACM, 2023, pp. 1513–1522. [Online]. Available: https://doi.org/10.1145/3583780.3614953
[227] J. White, G. Poesia, R. X. D. Hawkins, D. Sadigh, and N. D. Goodman, “Open-domain clarification question generation without question examples,” CoRR, vol. abs/2110.09779, 2021. [Online]. Available: https://arxiv.org/abs/2110.09779
[228] B. P. Majumder, S. Rao, M. Galley, and J. J. McAuley, “Ask what’s missing and what’s useful: Improving clarification question generation using global knowledge,” CoRR, vol. abs/2104.06828, 2021. [Online]. Available: https://arxiv.org/abs/2104.06828
[229] Z. Zhang and K. Q. Zhu, “Diverse and specific clarification question generation with keywords,” CoRR, vol. abs/2104.10317, 2021. [Online]. Available: https://arxiv.org/abs/2104.10317
[230] Z. Shi, Y. Feng, and A. Lipani, “Learning to execute actions or ask clarification questions,” CoRR, vol. abs/2204.08373, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2204.08373
[231] Z. Eberhart and C. McMillan, “Generating clarifying questions for query refinement in source code search,” CoRR, vol. abs/2201.09974, 2022. [Online]. Available: https://arxiv.org/abs/2201.09974
[232] H. Li, M. Mesgar, A. F. T. Martins, and I. Gurevych, “Python code generation by asking clarification questions,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Association for Computational Linguistics, 2023, pp. 14 287–14 306. [Online]. Available: https: //doi.org/10.18653/v1/2023.acl-long.799
[233] P. Erbacher, L. Denoyer, and L. Soulier, “Interactive query clarification and refinement via user simulation,” CoRR, vol. abs/2205.15918, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2205.15918
[234] B. Mansouri and Z. Jahedibashiz, “Clarifying questions in math information retrieval,” in Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval, ICTIR 2023, Taipei, Taiwan, 23 July 2023, M. Yoshioka, J. Kiseleva, and M. Aliannejadi, Eds. ACM, 2023, pp. 149–158. [Online]. Available: https://doi.org/10.1145/3578337.3605123
[235] Y. Deng, S. Li, and W. Lam, “Learning to ask clarification questions with spatial reasoning,” in Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2023, Taipei, Taiwan, July 2327, 2023, H. Chen, W. E. Duh, H. Huang, M. P. Kato, J. Mothe, and B. Poblete, Eds. ACM, 2023, pp. 2113–2117. [Online]. Available: https://doi.org/10.1145/3539618.3592009
[236] A. Testoni and R. Ferna ́ndez, “Asking the right question at the right time: Human and model uncertainty guidance to ask clarification questions,” CoRR, vol. abs/2402.06509, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.06509
[237] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” CoRR, vol. abs/1810.04805, 2018. [Online]. Available: http://arxiv.org/abs/1810. 04805
[238] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-totext transformer,” CoRR, vol. abs/1910.10683, 2019. [Online]. Available: http://arxiv.org/abs/1910.10683
[239] OpenAI, “GPT-4 technical report,” CoRR, vol. abs/2303.08774, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2303.08774
[240] T. Formal, B. Piwowarski, and S. Clinchant, “SPLADE: sparse lexical and expansion model for first stage ranking,” CoRR, vol. abs/2107.05720, 2021. [Online]. Available: https://arxiv.org/abs/2107.05720
[241] Y. Qu, Y. Ding, J. Liu, K. Liu, R. Ren, X. Zhao, D. Dong, H. Wu, and H. Wang, “Rocketqa: An optimized training approach to dense passage retrieval for open-domain question answering,” CoRR, vol. abs/2010.08191, 2020. [Online]. Available: https://arxiv.org/abs/2010.08191
[242] J. Robinson, C. Chuang, S. Sra, and S. Jegelka, “Contrastive learning with hard negative samples,” CoRR, vol. abs/2010.04592, 2020. [Online]. Available: https://arxiv.org/abs/2010.04592
[243] F. Radlinski and N. Craswell, “A theoretical framework for conversational search,” in Proceedings of the 2017 Conference on Conference Human Information Interaction and Retrieval, CHIIR 2017, Oslo, Norway, March 7-11, 2017, R. Nordlie, N. Pharo, L. Freund, B. Larsen, and D. Russel, Eds. ACM, 2017, pp. 117126. [Online]. Available: https://doi.org/10.1145/ 3020165.3020183
[244] C. Meng, N. Arabzadeh, M. Aliannejadi, and M. de Rijke, “Query performance prediction: From ad-hoc to conversational search,” in Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2023, Taipei, Taiwan, July 23-27, 2023, H. Chen, W. E. Duh, H. Huang, M. P. Kato, J. Mothe, and B. Poblete, Eds. ACM, 2023, pp. 2583–2593. [Online]. Available: https://doi.org/10.1145/3539618.3591919
[245] Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, Q. Guo, M. Wang, and H. Wang, “Retrievalaugmented generation for large language models: A survey,” CoRR, vol. abs/2312.10997, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2312.10997
[246] S. Zhuang, B. Liu, B. Koopman, and G. Zuccon, “Open-source large language models are strong zeroshot query likelihood models for document ranking,” in Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 610, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023, pp. 8807–8817. [Online]. Available: https: //doi.org/10.18653/v1/2023.findings-emnlp.590
[247] H. Yang, Z. Li, Y. Zhang, J. Wang, N. Cheng, M. Li, and J. Xiao, “PRCA: fitting black-box large language models for retrieval question answering via pluggable reward-driven contextual adapter,” CoRR, vol. abs/2310.18347, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.18347
[248] F. Xu, W. Shi, and E. Choi, “RECOMP: improving retrieval-augmented lms with compression and selective augmentation,” CoRR, vol. abs/2310.04408, 2023. [Online]. Available: https://doi.org/10.48550/ arXiv.2310.04408
[249] Y. Ma, Y. Cao, Y. Hong, and A. Sun, “Large language model is not a good few-shot information extractor, but a good reranker for hard samples!” in Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 610, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023, pp. 10 572–10 601. [Online]. Available: https: //doi.org/10.18653/v1/2023.findings-emnlp.710
[250] X. Du and H. Ji, “Retrieval-augmented generative question answering for event argument extraction,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Association for Computational Linguistics, 2022, pp. 4649–4666. [Online]. Available: https: //doi.org/10.18653/v1/2022.emnlp-main.307
[251] X. V. Lin, X. Chen, M. Chen, W. Shi, M. Lomeli, R. James, P. Rodriguez, J. Kahn, G. Szilvasy, M. Lewis, L. Zettlemoyer, and S. Yih, “RADIT: retrieval-augmented dual instruction tuning,” CoRR, vol. abs/2310.01352, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.01352
[252] F. Cuconasu, G. Trappolini, F. Siciliano, S. Filice, C. Campagnano, Y. Maarek, N. Tonellotto, and F. Silvestri, “The power of noise: Redefining retrieval for RAG systems,” CoRR, vol. abs/2401.14887, 2024. [Online]. Available: https://doi.org/10.48550/arXiv. 2401.14887
[253] S. Wu, J. Xie, J. Chen, T. Zhu, K. Zhang, and Y. Xiao, “How easily do irrelevant inputs skew the responses of large language models?” CoRR, vol. abs/2404.03302, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2404.03302
[254] D. Li, Z. Sun, X. Hu, Z. Liu, Z. Chen, B. Hu, A. Wu, and M. Zhang, “A survey of large language models attribution,” CoRR, vol. abs/2311.03731, 2023.
[255] X. Li, J. Jin, Y. Zhou, Y. Zhang, P. Zhang, Y. Zhu, and Z. Dou, “From matching to generation: A survey on generative information retrieval,” CoRR, vol. abs/2404.14851, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2404.14851
[256] S. Xu, L. Pang, H. Shen, X. Cheng, and T.S. Chua, “Search-in-the-chain: Towards the accurate, credible and traceable content generation for complex knowledge-intensive tasks,” CoRR, vol. abs/2304.14732, 2023.
[257] H. Sun, H. Cai, B. Wang, Y. Hou, X. Wei, S. Wang, Y. Zhang, and D. Yin, “Towards verifiable text generation with evolving memory and self-reflection,” CoRR, vol. abs/2312.09075, 2023.
[258] L. Gao, Z. Dai, P. Pasupat, A. Chen, A. T. Chaganty, Y. Fan, V. Y. Zhao, N. Lao, H. Lee, D.-C. Juan, and K. Guu, “RARR: researching and revising what language models say, using language models,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023. Association for Computational Linguistics, 2023, pp. 16 477–16 508.
[259] A. Chen, P. Pasupat, S. Singh, H. Lee, and K. Guu, “PURR: efficiently editing language model hallucinations by denoising language model corruptions,” CoRR, vol. abs/2305.14908, 2023.
[260] W. Li, J. Li, W. Ma, and Y. Liu, “Citationenhanced generation for llm-based chatbots,” CoRR, vol. abs/2402.16063, 2024.
[261] S. Tian, Q. Jin, L. Yeganova, P. Lai, Q. Zhu, X. Chen, Y. Yang, Q. Chen, W. Kim, D. C. Comeau, R. Islamaj, A. Kapoor, X. Gao, and Z. Lu, “Opportunities and challenges for chatgpt and large language models in biomedicine and health,” CoRR, vol. abs/2306.10070, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2306.10070
[262] J. Lee, N. Stevens, S. C. Han, and M. Song, “A survey of large language models in finance (finllms),” CoRR, vol. abs/2402.02315, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.02315
[263] J. Wang, F. Mo, W. Ma, P. Sun, M. Zhang, and J. Nie, “A user-centric benchmark for evaluating large language models,” CoRR, vol. abs/2404.13940, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2404.13940
[264] H. Le, D. Sahoo, C. Liu, N. F. Chen, and S. C. H. Hoi, “Uniconv: A unified conversational neural architecture for multi-domain task-oriented dialogues,” CoRR, vol. abs/2004.14307, 2020. [Online]. Available: https://arxiv.org/abs/2004.14307
[265] H. Jeon and G. G. Lee, “Domain state tracking for a simplified dialogue system,” CoRR, vol. abs/2103.06648, 2021. [Online]. Available: https: //arxiv.org/abs/2103.06648
[266] M. Zhao, L. Wang, Z. Jiang, R. Li, X. Lu, and Z. Hu, “Multi-task learning with graph attention networks for multi-domain task-oriented dialogue systems,” Knowl. Based Syst., vol. 259, p. 110069, 2023. [Online]. Available: https://doi.org/10.1016/j. knosys.2022.110069
[267] H. Zhou, B. Gu, X. Zou, Y. Li, S. S. Chen, P. Zhou, J. Liu, Y. Hua, C. Mao, X. Wu, Z. Li, and F. Liu, “A survey of large language models in medicine: Progress, application, and challenge,” CoRR, vol. abs/2311.05112, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2311.05112
[268] T. Talvensaari, M. Juhola, J. Laurikkala, and K. J ̈arvelin, “Corpus-based cross-language information retrieval in retrieval of highly relevant documents,” J. Assoc. Inf. Sci. Technol., vol. 58, no. 3, pp. 322–334, 2007. [Online]. Available: https://doi.org/10.1002/asi.20495
[269] K. Huang, F. Mo, H. Li, Y. Li, Y. Zhang, W. Yi, Y. Mao, J. Liu, Y. Xu, J. Xu, J. Nie, and Y. Liu, “A survey on large language models with multilingualism: Recent advances and new frontiers,” CoRR, vol. abs/2405.10936, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2405.10936
[270] Y. Cai, L. Wang, Y. Wang, G. de Melo, Y. Zhang, Y. Wang, and L. He, “Medbench: A large-scale chinese benchmark for evaluating medical large language models,” CoRR, vol. abs/2312.12806, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2312.12806
[271] Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhou, R. Zheng, X. Fan, X. Wang, L. Xiong, Y. Zhou, W. Wang, C. Jiang, Y. Zou, X. Liu, Z. Yin, S. Dou, R. Weng, W. Cheng, Q. Zhang, W. Qin, Y. Zheng, X. Qiu, X. Huang, and T. Gui, “The rise and potential of large language model based agents: A survey,” CoRR, vol. abs/2309.07864, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309.07864
[272] T. Schick, J. Dwivedi-Yu, R. Dessı`, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” in Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., 2023. [Online]. Available: http: //papers.nips.cc/paper files/paper/2023/hash/ d842425e4bf79ba039352da0f658a906-Abstract-Conference. html
[273] Q. Wu, G. Bansal, J. Zhang, Y. Wu, S. Zhang, E. Zhu, B. Li, L. Jiang, X. Zhang, and C. Wang, “Autogen: Enabling next-gen LLM applications via multi-agent conversation framework,” CoRR, vol. abs/2308.08155, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2308.08155
[274] W. Zhang, J. Liao, N. Li, and K. Du, “Agentic information retrieval,” arXiv preprint arXiv:2410.09713, 2024
评论