论文重点与难点
重点
1. Shape Tokens 的提出
Shape Tokens 是一种新型的3D形状表示方法,它将形状表示为连续、紧凑的向量集合。这些向量作为条件向量,用于表示3D流匹配模型中的形状信息。Shape Tokens 的设计目标是易于集成到各种机器学习模型中,用于生成新形状、将图像转换为3D、对齐3D形状与文本和图像,以及以用户指定的分辨率直接渲染形状。
2. 基于流匹配的生成模型
论文提出了一种基于流匹配的生成模型,用于学习3D形状的概率密度函数。通过将形状视为3D空间中的概率密度函数,并使用流匹配模型来近似这些密度函数,Shape Tokens 能够高效地表示形状,同时支持多种下游任务,如3D生成、零样本分类和神经渲染。
3. 高效且紧凑的表示
Shape Tokens 使用1024个16维的连续向量来表示形状,相比传统的点云表示方法(需要数万个点)或网格表示方法,Shape Tokens 更加高效和紧凑,适合大规模机器学习任务。
4. 多任务适用性
Shape Tokens 在多种任务中表现出色,包括:
-
3D形状生成:通过训练无条件和条件流匹配模型,生成高质量的3D形状。
-
零样本分类:通过将Shape Tokens与CLIP嵌入对齐,实现3D形状的零样本分类。
-
神经渲染:通过估计射线与形状的交点和法线,实现高质量的神经渲染。
5. 代码和模型开源
为了推动研究进展,作者计划公开发布预训练的Shape Tokens模型、图像条件的潜在流匹配模型、3D-CLIP模型以及完整的训练代码。
难点
1. 流匹配模型的训练
流匹配模型需要通过复杂的优化过程来学习形状的概率密度函数。这涉及到对概率流常微分方程(ODE)的求解,以及对模型参数的精细调整。训练过程中需要处理大量的点云数据,并确保模型能够准确地拟合形状的表面分布。
2. Shape Tokens 的生成效率
由于Shape Tokens的生成依赖于ODE的数值积分,这导致生成点云的速度相对较慢。论文中提到,生成一个包含16384个点的点云需要数秒时间。如何提高生成效率是一个亟待解决的问题,可能需要借助模型蒸馏或扩散模型的加速技术。
3. 多任务适应性与泛化能力
虽然Shape Tokens在多种任务中表现出色,但其在不同任务中的泛化能力仍需进一步验证。例如,在零样本分类任务中,Shape Tokens需要与预训练的CLIP模型对齐,这可能受到数据分布差异的影响。此外,在神经渲染任务中,Shape Tokens需要与射线交点估计模型协同工作,这增加了模型的复杂性。
4. 颜色信息的扩展
当前的Shape Tokens仅考虑了几何信息,尚未支持颜色信息。将颜色信息融入Shape Tokens表示中,可能会进一步提升其在图形渲染和3D重建任务中的表现,但这也增加了模型的复杂性和训练难度。
5. 大规模数据集的处理
论文在Objaverse数据集上展示了Shape Tokens的强大能力,但该数据集的规模和多样性对训练流程提出了挑战。例如,Objaverse中的许多网格模型是非封闭的,这使得传统的基于网格的3D表示方法(如SDF)难以应用。Shape Tokens通过仅使用点云进行训练,简化了这一问题,但如何高效地处理大规模点云数据仍然是一个难点。
论文详细解读
1 研究背景与动机
3D形状在计算机视觉和图形学中具有重要应用,但如何高效地表示3D形状一直是研究的热点问题。常见的3D表示方法包括体素(voxels)、网格(meshes)、点云(point clouds)、距离场(distance fields)等,但这些方法各有优缺点。例如,网格表示虽然精确,但难以处理拓扑变化;点云表示虽然灵活,但需要大量点来表示复杂形状。因此,作者提出了一种新的3D表示方法——Shape Tokens,旨在提供一种连续、紧凑且易于集成到机器学习模型中的3D形状表示。
2 Shape Tokens 的核心思想
Shape Tokens 将3D形状表示为一组连续的向量,这些向量作为条件向量(conditioning vectors)输入到流匹配模型(flow-matching model)中。流匹配模型通过学习形状表面的概率密度函数来近似形状,具体来说,它将形状表面的点视为概率密度函数的样本,并通过训练来拟合这些样本。Shape Tokens 的主要特点包括:
-
连续性和紧凑性:Shape Tokens 使用1024个16维的向量来表示形状,相比传统的点云或网格表示,更加高效。
-
对形状结构的假设少:Shape Tokens 只假设可以从形状表面采样点云,不依赖于形状的拓扑结构(如水密性)。
-
训练简单:训练时只需要点云数据,不需要复杂的预处理(如网格修复)。
3 方法细节
3.1 流匹配模型
流匹配模型是一种生成模型,通过学习一个时间依赖的过程,将数据样本\(x \sim p(x)\)逐渐转化为噪声\(\epsilon \sim e(\epsilon)\):
\[x_t = \alpha_t x + \sigma_t \epsilon,\]其中\(t \in [0, 1]\),\(\alpha_t\)是关于\(t\)的增函数,\(\sigma_t\)是关于\(t\)的减函数。流匹配模型通过学习一个速度场\(v_\theta(x; t)\)来近似这个过程:
\[\dot{x}_t = \frac{dx_t}{dt} = v_\theta(x; t).\]通过最小化以下损失函数来训练模型:
\[L(\theta) = \int_0^1 \mathbb{E} \left[ \|v_\theta(x_t; t) - \dot{\alpha}_t x - \dot{\sigma}_t \epsilon\|^2 \right] dt.\]3.2 Shape Tokens 的学习
Shape Tokens 的学习过程可以分为两部分:
1. 形状编码器(Shape Tokenizer):将输入的点云编码为一组Shape Tokens。形状编码器的架构类似于PerceiverIO,通过交叉注意力机制(cross-attention)和自注意力机制(self-attention)来提取点云的特征。
2. 流匹配模型:使用Shape Tokens作为条件,学习形状的概率密度函数。流匹配模型通过最小化以下变分下界来训练:
其中\(S\)是形状,\(x\)是形状上的点,\(Y\)和\(Z\)是独立采样的点云,\(\lambda\)是正则化项的权重。
4 实验与结果
4.1 3D形状生成
作者在ShapeNet数据集上训练了一个无条件的流匹配模型,在Objaverse数据集上训练了一个基于图像条件的流匹配模型。实验结果表明,Shape Tokens在3D形状生成任务中表现出色,与现有的生成模型(如LION和DPF)相比,具有更紧凑的表示和更好的生成质量。
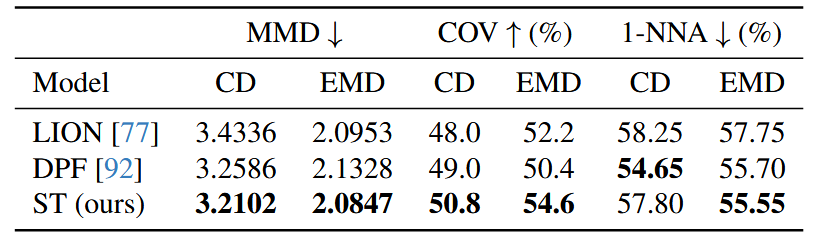
表3。ShapeNet上的无条件生成。对于MMD-CD,单位为\(10^{-3}\),对于MMD-EMD,单位为\(10^{-2}\)。
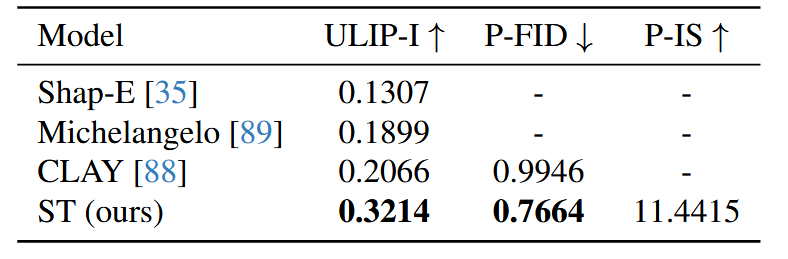
表4。Objaverse上的单图像条件生成。
参见表3、表4。
4.2 零样本分类
作者将Shape Tokens与CLIP模型对齐,用于3D形状的零样本分类。实验结果表明,Shape Tokens在零样本分类任务中表现出色,与专门训练的PointBert编码器相比,具有可比的性能。
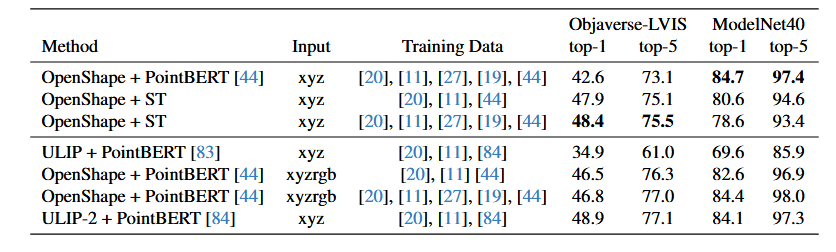
表5。零样本文本分类。第一行块展示了使用联合训练的PointBERT编码器的OpenShape与使用ST + MLP编码器的OpenShape之间的比较。第二行块包括其他当前方法作为参考。
参见表5。
4.3 神经渲染
作者展示了Shape Tokens在神经渲染中的应用,通过估计射线与形状的交点和法线,实现了高质量的渲染效果。实验结果表明,Shape Tokens在神经渲染任务中表现出色,能够生成平滑的法线图,并且对输入点云的局部变化具有鲁棒性。

表6。Objaverse未见形状上的射线形状相交结果。
参见表6。
5 分析与讨论
5.1 Shape Tokens 的几何属性
Shape Tokens不仅是一种高效的3D表示方法,还具有与3D几何紧密相关的属性。例如,通过流匹配模型的速度场,可以估计形状表面的法线:
\[\hat{n}(x) = \frac{\nabla_x \log p_1(x\vert s)}{\|\nabla_x \log p_1(x\vert s)\|} = \text{normalize}(\alpha_1 v(x; t \to 1) - \dot{\alpha}_1 x).\]此外,Shape Tokens还支持UVW映射,将3D空间中的点映射到初始噪声空间,类似于纹理映射中的UV映射。
5.2 限制与未来工作
尽管Shape Tokens在多个任务中表现出色,但仍存在一些限制:
-
颜色信息的缺失:当前的Shape Tokens仅考虑了几何信息,尚未支持颜色信息。
-
生成效率:由于需要进行ODE的数值积分,Shape Tokens的生成速度相对较慢。
-
大规模数据集的处理:虽然Shape Tokens简化了训练流程,但在处理大规模数据集时,仍需要高效的采样和优化策略。
未来的工作方向包括:
-
扩展到颜色信息:将颜色信息融入Shape Tokens表示中,以支持更丰富的3D表示。
-
提高生成效率:通过模型蒸馏或扩散模型的加速技术,提高Shape Tokens的生成速度。
-
进一步优化训练流程:探索更高效的训练策略,以应对大规模数据集的挑战。
6 总结
Shape Tokens 提供了一种新型的3D形状表示方法,具有连续、紧凑、易于集成的特点。通过流匹配模型,Shape Tokens能够高效地表示3D形状,并在多种下游任务中表现出色。尽管存在一些限制,但Shape Tokens的提出为3D形状表示和生成模型的研究提供了新的视角和方法。
论文方法部分详细讲解
1 流匹配模型(Flow Matching Model)
流匹配模型是一种生成模型,用于学习数据样本的概率分布。其核心思想是通过一个时间依赖的过程,将数据样本 \(x \sim p(x)\) 逐渐转化为噪声 \(\epsilon \sim e(\epsilon)\)。具体过程如下:
\[x_t = \alpha_t x + \sigma_t \epsilon,\]其中 \(t \in [0, 1]\),\(x\) 和 \(\epsilon\) 是 \(d\) 维向量,\(\alpha_t\) 是关于 \(t\) 的增函数,\(\sigma_t\) 是关于 \(t\) 的减函数,且 \(p_0(x) \equiv e(x)\) 是噪声的分布,\(p_1(x) \approx p(x)\) 是数据分布。
流匹配模型通过学习一个速度场 \(v_\theta(x; t)\) 来近似这个过程:
\[\dot{x}_t = \frac{dx_t}{dt} = v_\theta(x; t).\]模型通过最小化以下损失函数来训练:
\[L(\theta) = \int_0^1 \mathbb{E} \left[ \|v_\theta(x_t; t) - \dot{\alpha}_t x - \dot{\sigma}_t \epsilon\|^2 \right] dt.\]在实际实现中,时间积分和期望通过蒙特卡洛方法近似,使得实现简单高效。
2 Shape Tokens 的学习
2.1 Shape Tokens 的定义
Shape Tokens 是一种用于表示3D形状的连续向量集合。每个3D形状 \(S\) 被表示为一个概率密度函数 \(p_S(x) : \mathbb{R}^3 \rightarrow [0, \infty)\),其中 \(x \in \mathbb{R}^3\) 是3D位置。给定一个形状 \(S\) 的点云样本 \(X = \{x_1, \dots, x_n\}\),Shape Tokens 的目标是通过一个条件流匹配模型 \(v_\theta(x; s, t)\) 来拟合 \(p_S(x)\),其中 \(s \in \mathbb{R}^{k \times d}\) 是 \(k\) 个Shape Tokens,\(t \in [0, 1]\) 是流匹配时间,\(\theta\) 是神经网络的参数。
Shape Tokens \(s\) 是通过一个编码器(tokenizer) \(\mu_\theta(S)\) 生成的,该编码器与流匹配模型联合训练,将形状 \(S\) 的所有必要信息嵌入到 \(s\) 中。
2.2 训练目标
给定一个包含 \(N\) 个点云的数据集 \(X_1, \dots, X_N\),其中每个点云 \(X_i\) 包含 \(n\) 个独立同分布的样本 \(x_i^1, \dots, x_i^n \sim p_{S_i}(x)\),Shape Tokens 的训练目标是最大化以下变分下界:
\[\max_\theta \mathbb{E}_S \mathbb{E}_{x \sim p_S(x)} \log p_\theta(x\vert S).\]通过重参数化技巧,该目标可以进一步展开为:
\[\mathbb{E}_S \mathbb{E}_{x \sim p_S(x)} \log \int p_\theta(x, s\vert Z) \, ds,\]其中 \(Z\) 是从 \(p_S(x)\) 中独立采样的点云。通过Jensen不等式,可以得到以下下界:
\[\mathbb{E}_S \mathbb{E}_{x \sim p_S(x)} \mathbb{E}_{s \sim q(s\vert Y)} \log p_\theta(x\vert s) - \text{KL}(q_\theta(s\vert Y) \vert \vert p_\theta(s\vert Z)),\]其中 \(Y\) 和 \(Z\) 是从 \(p_S(x)\) 中独立采样的点云。为了正则化Shape Tokens空间,还添加了一个KL散度项:
\[\text{KL}(q_\theta(s\vert Y) \vert \vert p(s)),\]其中 \(p(s)\) 是Shape Tokens的先验分布,假设为各向同性的高斯分布。
最终的训练目标为:
\[\mathcal{L}(\theta) = \mathbb{E}_S \mathbb{E}_{x \sim p_S(x)} \mathbb{E}_{s \sim q(s\vert Y)} \log p_\theta(x\vert s) - \lambda_1 \text{KL}(q_\theta(s\vert Y) \vert \vert p_\theta(s\vert Z)) - \lambda_2 \text{KL}(q_\theta(s\vert Y) \vert \vert p(s)),\]其中 \(\lambda_1\) 和 \(\lambda_2\) 是正则化项的权重。
2.3 网络架构
Shape Tokens 的网络架构包括两个主要部分:形状编码器(tokenizer)和流匹配速度估计器(velocity estimator)。
-
形状编码器(Shape Tokenizer)
形状编码器的架构类似于PerceiverIO,通过交叉注意力机制(cross-attention)和自注意力机制(self-attention)从输入点云中提取特征。具体来说,编码器包含以下部分:
-
一组初始查询向量(queries),用于从输入点云中检索信息。
-
多个交叉注意力块(cross-attention blocks),用于将点云信息聚合到Shape Tokens中。
-
每个交叉注意力块后接两个自注意力块(self-attention blocks),用于进一步处理特征。
-
一个线性层,将最后一个自注意力块的输出投影到Shape Tokens空间。
-
-
流匹配速度估计器(Velocity Estimator)
流匹配速度估计器的输入是Shape Tokens \(s\) 和一个3D位置 \(x\),输出是该位置的速度估计值。其架构包括:
-
一个交叉注意力块(cross-attention block),将3D位置 \(x\) 作为查询向量(query),Shape Tokens \(s\) 作为键(key)和值(value)。
-
多个线性层(MLP),用于进一步处理特征并输出速度估计值。
-
流匹配时间 \(t\) 通过自适应层归一化(adaptive layer normalization)输入到速度估计器中。
-
3 Shape Tokens 的性质分析
3.1 表面法线估计
由于形状的概率密度函数 \(p(x\vert S)\) 是一个3D delta函数,其梯度方向与表面法线对齐。通过以下公式可以将流匹配速度转换为梯度:
\[\hat{n}(x) = \frac{\nabla_x \log p_1(x\vert s)}{\|\nabla_x \log p_1(x\vert s)\|} = \text{normalize}(\alpha_1 v(x; t \to 1) - \dot{\alpha}_1 x).\]通过选择合适的路径(如广义方差保持路径),可以在 \(t=1\) 时直接估计法线方向。
3.2 对数似然估计
流匹配模型允许通过瞬时变量变换(instantaneous change of variable)计算任意位置的精确对数似然:
\[\log p(x\vert s) = \log p_0(x_0) + \int_0^1 \text{div} \, v_\theta(x_t; t) \, dt.\]这使得可以估计点 \(x\) 属于形状 \(S\) 的概率,并通过积分ODE来过滤噪声点。
3.3 UVW 映射
由于流匹配模型的速度估计器是一个神经网络,因此其轨迹是非相交的,并且在初始噪声空间和3D形状空间之间存在双射映射。这意味着可以将任意3D位置 \(x\) 映射回初始噪声空间中的一个唯一位置 \(uvw\)。这种映射类似于纹理映射中的UV映射,可以用于颜色插值等任务。
4 实验与应用
Shape Tokens 在多个下游任务中表现出色,包括3D形状生成、零样本分类和神经渲染。这些任务展示了Shape Tokens的多样性和有效性,同时也验证了其作为一种通用3D表示方法的潜力。
原文翻译
3D形状标记化
Jen-Hao Rick Chang, Yuyang Wang, Miguel Angel Bautista Martin Jiatao Gu, Josh Susskind, Oncel Tuzel
Apple
https://machinelearning.apple.com/research/3d-shape-tokenization
摘要
我们引入了Shape Tokens(形状标记),这是一种连续、紧凑且易于集成到机器学习模型中的3D表示。Shape Tokens作为条件向量,在3D流匹配模型中表示形状信息。该流匹配模型被训练为近似对应于3D形状表面上集中分布的delta函数的概率密度函数。通过将Shape Tokens附加到各种机器学习模型中,我们可以生成新形状、将图像转换为3D、将3D形状与文本和图像对齐,并以用户指定的可变分辨率直接渲染形状。此外,Shape Tokens能够系统分析几何属性,如法线、密度和变形场。在所有任务和实验中,使用Shape Tokens均表现出优于现有基线的性能。
1 引言
在学习系统中,3D形状应如何表示?有许多可用的选项:体素[21, 39, 47]、网格[57, 70]、点云[41, 64, 73, 85]、(无)符号距离场[18, 46, 56]、辐射/占据场[54, 55, 61, 80]、3D高斯溅射[38, 40]等。在典型设置中,表示的选择取决于下游任务。例如,在图形或渲染场景中,可能会选择网格或3D高斯表示[38]。对于科学或物理模拟设置,连续表示(如场)可能能够编码细粒度信息[9, 30]。然而,对于训练机器学习模型时,什么是好的3D形状表示似乎没有明确的共识。大多数机器学习模型需要连续且紧凑的表示,以满足计算和内存约束。点状表示由于其连续性和与最新架构(如transformer[50, 85, 87])的兼容性,通常被选择。然而,通常需要数十到数千个点来表示高保真度的3D形状,这使得点云在大型系统中难以使用。我们的假设是,可以学习一种连续且紧凑的3D形状表示,该表示能够编码许多不同机器学习下游任务的有用信息。具体来说,我们将形状视为3D空间中的概率密度函数,并使用流匹配生成模型通过训练每个密度函数的样本来学习这些密度的表示(即从形状表面采样的点)。我们将我们的表示称为Shape Tokens(ST),它具有以下几个理想特性:
1. ST是连续且紧凑的。与用离散网格或数万个点表示场景不同,它们用1,024个16维的连续向量表示多样化的形状,使其成为下游机器学习任务的高效表示。
2. 我们的方法对3D形状的底层结构做出了最小假设。我们只假设可以从3D形状的表面采样独立同分布(i.i.d.)的点(即从3D对象获取点云)。这与大多数3D表示(如符号距离函数(假设水密形状)和3D高斯(假设体积渲染))不同。
3. 在训练时,我们的方法只需要点云。这与现有的神经3D表示不同,后者通常需要在训练时使用网格或符号距离函数(例如[88, 89])。这一要求显著简化了我们的训练流程,并使我们能够轻松扩展训练集,因为像Objaverse[20]这样的大规模数据集中的大多数网格不是水密的,难以处理。
4. 值得注意的是,ST能够系统分析形状,包括表面法线估计、去噪和形状之间的变形(见第4.2节)。我们通过一系列下游任务实证证明了我们表示的有效性。首先,我们通过在ShapeNet[12]上学习无条件流匹配模型和在Objaverse上学习图像条件流匹配模型来解决3D生成问题(见第5.1节)。其次,我们通过训练一个多层感知器(MLP)将ST与图像和文本CLIP嵌入[44]对齐,展示了3D形状的零样本文本分类(见第5.2节)。第三,我们展示了一个图形用例(射线表面交互估计),通过训练一个神经网络,该网络以射线和ST作为输入,输出交点及其法线(见第5.3节)。在这些任务中,我们都取得了与为特定任务设计的基线相竞争的性能。最后,我们发现,阻碍进展的一个重大挑战是缺乏现成的代码和预训练模型,这些模型是在像Objaverse这样的大规模数据集上训练的现有神经3D表示方法(例如[88])。为了解决这一问题并促进未来工作的进展,我们将公开预训练的形状标记器、图像条件潜在流匹配模型、3D-CLIP模型、数据渲染管道以及我们的完整训练代码。
注:在语言模型中,“token”通常表示一组离散符号。Shape Tokens指的是一组实值向量。
2 相关工作
3D表示、生成和分类领域非常广泛。我们重点讨论与我们的工作最相关的文献——3D表示的生成模型。关于3D表示的整体概述,我们推荐读者参考[76]。有几种方法学习3D形状的潜在表示和生成模型。MeshGPT[70]和MeshXL[17]学习三角形的自编码器和自回归模型以生成三角形序列。XCube[65]学习单个分辨率的占据网格的潜在表示。3DShape2VecSet[86]、Michelangelo[90]、Direct3D[79]和Clay[88]通过学习估计xyz位置的占据来编码表面。在训练过程中,这些方法需要网格以及大量的预处理和过滤,以确保网格是水密的、良好离散的(三角形数量不多)或经过UV映射。在点云领域,PointE[58]和LION[77]都学习固定基数的点集的生成模型,即它们学习固定数量点的联合分布\(p(x_1, \ldots, x_k)\)。尽管它具有置换不变性,但与我们的三维分布相比,它是一个更高维的函数,这使我们能够使用紧凑的潜在表示实现类似的重建质量。与我们的方法密切相关的是Luo和Hu[51]以及PointFlow[85],它们也将3D形状视为3D概率密度函数,并使用生成模型(分别是扩散模型和连续归一化流)来建模这些分布。相比之下,我们利用流匹配并将训练规模从ShapeNet扩展到Objaverse。此外,我们展示了流匹配中预测的速度场与几何属性(如表面法线和变形场)之间的联系,并表明所学的3D表示在生成建模之外也很有用(例如零样本分类和神经渲染)。另一项有趣的工作利用图像和可微分渲染来监督3D表示的估计[28, 31, 42, 45, 63, 75, 81, 82]。这些工作的重点是渲染图像的真实感——3D表示及其分布并未直接监督或建模,因此不在本文的讨论范围内。
3 预备知识
我们对流匹配(Flow Matching)进行初步概述。流匹配生成模型[43, 52]学习反转一个随时间变化的过程,该过程将数据样本\(x \sim p(x)\)转换为噪声\(\epsilon \sim e(\epsilon)\):
\[x_t = \alpha_t x + \sigma_t\epsilon, \tag{1}\]其中\(t \in [0, 1]\),\(x\)和\(\epsilon \in \mathbb{R}^d\),\(\alpha_t\)是关于\(t\)的增函数,\(\sigma_t\)是关于\(t\)的减函数,\(p_0(x) \equiv e(x)\)是噪声的分布,\(p_1(x) \approx p(x)\)是数据分布。边际概率分布\(p_t(x)\)等价于以下速度场的概率流常微分方程(ODE)的分布[52]:
\[\dot{x}_t = \frac{\mathrm{d}x_t}{\mathrm{d}t} = v_{\theta}(x; t), \tag{2}\]其中\(v_{\theta}(x; t)\)可以通过最小化损失函数来学习:
\[\mathcal{L}(\theta) = \int_{0}^{1} \mathbb{E} \left[\left\|v_{\theta}(x_t; t) - \dot{\alpha}_t x_1 - \dot{\sigma}_t\epsilon\right\|^2\right] \mathrm{d}t. \tag{3}\]在实际应用中,时间积分和期望通过蒙特卡罗方法进行近似,这使得实现过程较为简单。在这种公式化表述下,通过对常微分方程(公式(2))从\(t = 0\)到\(t = 1\)进行积分来生成\(p_1(x)\)的样本。请注意,这种公式化表述允许对\(e(\epsilon)\)、\(\alpha_t\)和\(\sigma_t\)进行灵活选择,我们在本文中会用到这些选择,更多细节请读者参考文献[43, 52]。
4 方法
我们将三维形状\(\mathcal{S}\)视为一个概率密度函数\(p_{\mathcal{S}}(x): \mathbb{R}^3 \to [0, \infty)\),其中\(x \in \mathbb{R}^3\)是一个三维位置(即\(xyz\)坐标)。\(p_{\mathcal{S}}(x)\)的一组独立同分布样本构成一个点云\(\mathcal{X} = \{x_1, \ldots, x_n\}\)。我们的目标是使用条件流匹配模型\(v_{\theta}(x; s, t): \mathbb{R}^3 \to \mathbb{R}^3\)来拟合\(p_{\mathcal{S}}(x)\),其中\(t \in [0, 1]\)是流匹配时间,\(s \in \mathbb{R}^{k \times d}\)是\(k\)个形状标记(Shape Token,ST),用于表示形状\(\mathcal{S}\),\(\theta\)是神经网络\(v\)的参数。形状标记\(s\)是标记化器\(\mu_{\theta}(\mathcal{S})\)的输出,标记化器与流匹配模型联合学习,以便将关于\(\mathcal{S}\)的所有必要信息嵌入到\(s\)中,从而拟合\(p_{\mathcal{S}}(x)\)。
为了将信息\(\mathcal{S}\)输入到\(\mu\)中,我们在\(\mathcal{S}\)上采样一个包含\(m\)个点的点云,这使我们能够仅使用点云来训练\(\mu\)和\(v\)。具体来说,给定一个包含\(N\)个点云的数据集\(\mathcal{X}^1, \ldots, \mathcal{X}^N\),其中\(\mathcal{X}^i\)包含\(n\)个独立同分布样本\(x_1^i, \ldots x_n^i \sim p_{\mathcal{S}^i}(x)\),对应形状为\(\mathcal{S}^i\),我们最大化经验分布的对数似然的变分下界:
\[\begin{align} &\max_{\theta} \mathbb{E}_{\mathcal{S}} \mathbb{E}_{x \sim p_{\mathcal{S}}(x)} \log p_{\theta}(x\vert \mathcal{S}) \tag{4}\\ &\approx \mathbb{E}_{\mathcal{S}} \mathbb{E}_{x \sim p_{\mathcal{S}}(x)} \log \int_{s} p_{\theta}(x, s\vert \mathcal{Z}) \mathrm{d}s \tag{5}\\ &= \mathbb{E}_{\mathcal{S}} \mathbb{E}_{x \sim p_{\mathcal{S}}(x)} \log \int_{s} p_{\theta}(x\vert s)p_{\theta}(s\vert \mathcal{Z}) \mathrm{d}s \tag{6}\\ &= \mathbb{E}_{\mathcal{S}} \mathbb{E}_{x \sim p_{\mathcal{S}}(x)} \log \int_{s} p_{\theta}(x\vert s)p_{\theta}(s\vert \mathcal{Z}) \frac{q_{\theta}(s\vert \mathcal{Y})}{q_{\theta}(s\vert \mathcal{Y})} \mathrm{d}s \tag{7}\\ &\geq \mathbb{E}_{\mathcal{S}} \mathbb{E}_{x \sim p_{\mathcal{S}}(x)} \mathbb{E}_{s \sim q(s\vert \mathcal{Y})} \log p_{\theta}(x\vert s) - KL(q_{\theta}(s\vert \mathcal{Y})\vert \vert p_{\theta}(s\vert \mathcal{Z})) \tag{8} \end{align}\]其中\(\mathcal{Y}\)和\(\mathcal{Z}\)是从\(p_{\mathcal{S}}(x)\)中独立采样的点云。公式(5)中的近似是通过使用\(\mathcal{Z}\)代替\(\mathcal{S}\)得到的,并且由\(\mathcal{Z}\)的密度控制。我们在公式(8)中应用了詹森不等式。由于所有模型都是联合训练的,我们用\(\theta\)表示所有可学习的参数。我们使用流匹配(公式(3))来学习\(p_{\theta}(x\vert s)\),将\(q_{\theta}(s\vert \mathcal{Y})\)参数化为高斯分布\(\mathcal{N}(s; \mu_{\theta}(\mathcal{Y}), \sigma^2 I)\),将\(p_{\theta}(s\vert \mathcal{Z})\)参数化为\(\mathcal{N}(s; \mu_{\theta}(\mathcal{Z}), \sigma^2 I)\)。在这种参数化下,公式(8)中的KL散度简化为\(\frac{1}{\sigma^2} \|\mu_{\theta}(\mathcal{Y}) - \mu_{\theta}(\mathcal{Z})\|^2\)。这是合理的,因为从相同形状采样的两个点云应该产生相似的形状标记。为了对形状标记空间进行正则化,我们还添加一个KL散度\(KL(q_{\theta}(s\vert \mathcal{Y}) \vert \vert p(s))\),其中\(p(s)\)是\(s\)的先验分布,即一个等距高斯分布。
在训练目标中,我们使用KL散度项的加权和(公式(8)的权重为\(10^{-3}\),先验项的权重为\(10^{-4}\)),并根据经验将\(\sigma = 10^{-3}\) 。
架构
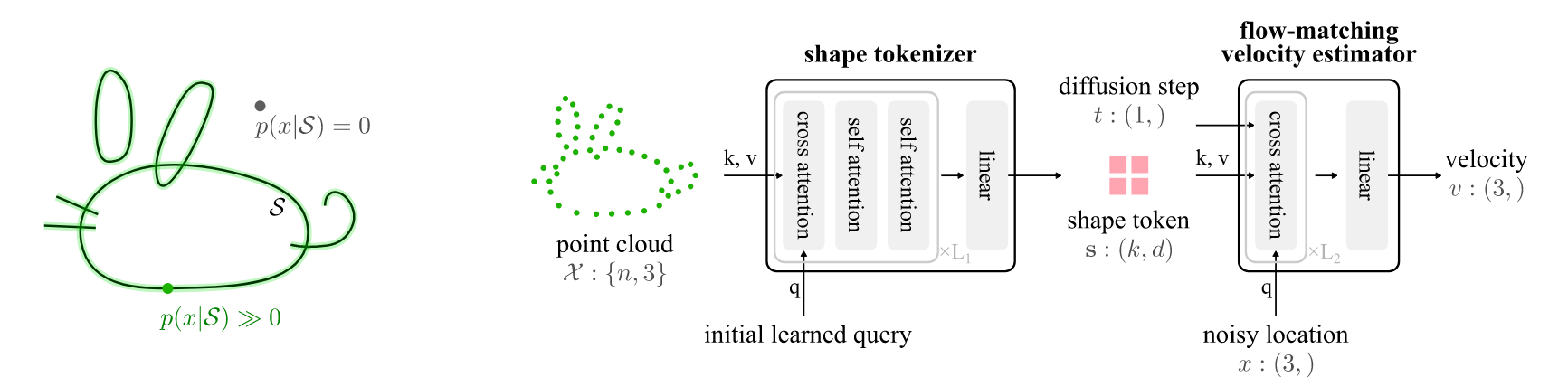
图2。我们的架构概述。(左)我们将3D形状建模为集中在表面上的概率密度函数,形成3D中的delta函数。(右)我们的标记器使用交叉注意力将形状上采样的点云信息聚合到ST中。速度估计器仅使用交叉注意力和MLP以保持点之间的独立性。
形状标记化器\(\mu(\cdot) \to s\)和流匹配速度估计器\(f\)的架构如图2所示。形状标记化器的架构与PerceiverIO架构[34]相似。我们学习一组初始查询,这些查询通过交叉注意力模块从表示形状的输入点云中检索信息。在每个交叉注意力模块之后添加两个自注意力模块。一个线性层将最后一个自注意力模块的输出映射为形状标记(ST)。
速度估计器\(v\)将形状标记\(s\)和三维位置\(x\)作为输入,并输出在\(x\)处的估计三维速度。我们将\(x\)用作交叉注意力模块的查询(将\(s\)用作键和值)。请注意,速度解码器中没有自注意力机制,以保持每个三维位置的速度估计相互独立,从而使\(p(x\vert s)\)成为一个三维分布(而不是\(n\)个位置的联合分布)。流匹配时间\(t\)通过自适应层归一化提供给速度估计器。
4.1 形状标记化器的评估
我们首先在ShapeNet数据集[122]上训练一个形状标记化器,该数据集包含55类物体。为了进行公平比较,我们使用与LION[77]相同的训练数据,包括点云归一化以及训练 - 评估划分。训练集包含35,708个点云,测试集包含10,261个点云。所有点云都包含15,000个点。我们从这15,000个点中无放回地随机采样4,096个点,在计算对称倒角距离(CD)时,使用前2048个点作为标记化器的输入,其余点作为参考。我们使用不同的总潜在维度(形状标记数量乘以其维度)来训练标记化器。我们使用Heun二阶方法[36]的500个均匀步骤来采样\(p(x\vert s)\)。

表1。ShapeNet上的重建误差。
我们将我们的方法与Pointflow[85]进行比较,因为它与我们的方法最为接近,还与对2048个点的联合分布进行建模的LION[77]比较。这两种方法都以2048个点作为输入,并在相同的训练数据(归一化和划分)上进行训练。PointFlow将形状表示为512维的潜在向量,LION将形状表示为128维的全局潜在向量和总维度为8192的局部潜在向量。我们对所有方法都使用后验分布(\(p(s\vert \mathcal{Z})\))的均值。如表1所示,形状标记化在实现相似的倒角距离的同时,比LION紧凑16倍。随着我们增加形状标记的总维度,倒角距离会有所改善。我们还报告了来自3DShape2VecSet[86]的倒角距离。请注意,我们的方法与他们的方法不能直接比较,他们的方法预测占据情况(即,在一个封闭形状的内部/外部),并使用移动立方体算法来寻找表面。这个操作导致了他们较大的倒角距离。
然后,我们在Objverse数据集[20]上训练形状标记化器,该数据集包含80万个具有各种三维形状的网格。与现有的需要封闭网格进行训练的方法(例如,计算有向距离函数或占据情况[79, 88, 89])不同,我们的方法只需要点云。这极大地简化了形状标记化的训练过程——我们能够利用Objverse训练划分中的所有网格,并且除了将其归一化到[-1, 1]的边界框归一化之外,不进行任何预处理(例如,平滑网格、使网格封闭等)。我们在网格表面均匀地独立同分布采样20万个点,以创建一个点云数据集。我们随机选择64万个网格用于训练。我们训练了两种形状标记化器变体,它们都以16,384个点作为输入,并输出1024个标记。较小的标记化器输出8维标记,另一个输出16维标记。
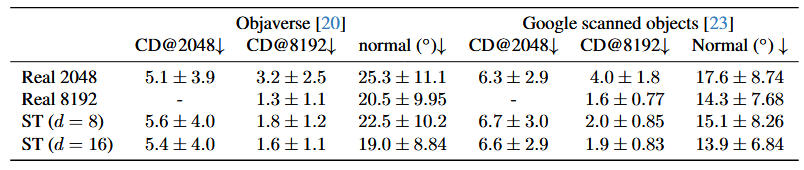
表2。Objaverse和GSO数据集上的重建误差。Chamfer距离单位为\(10^{-4}\),参考点云被归一化到[-1, 1]。
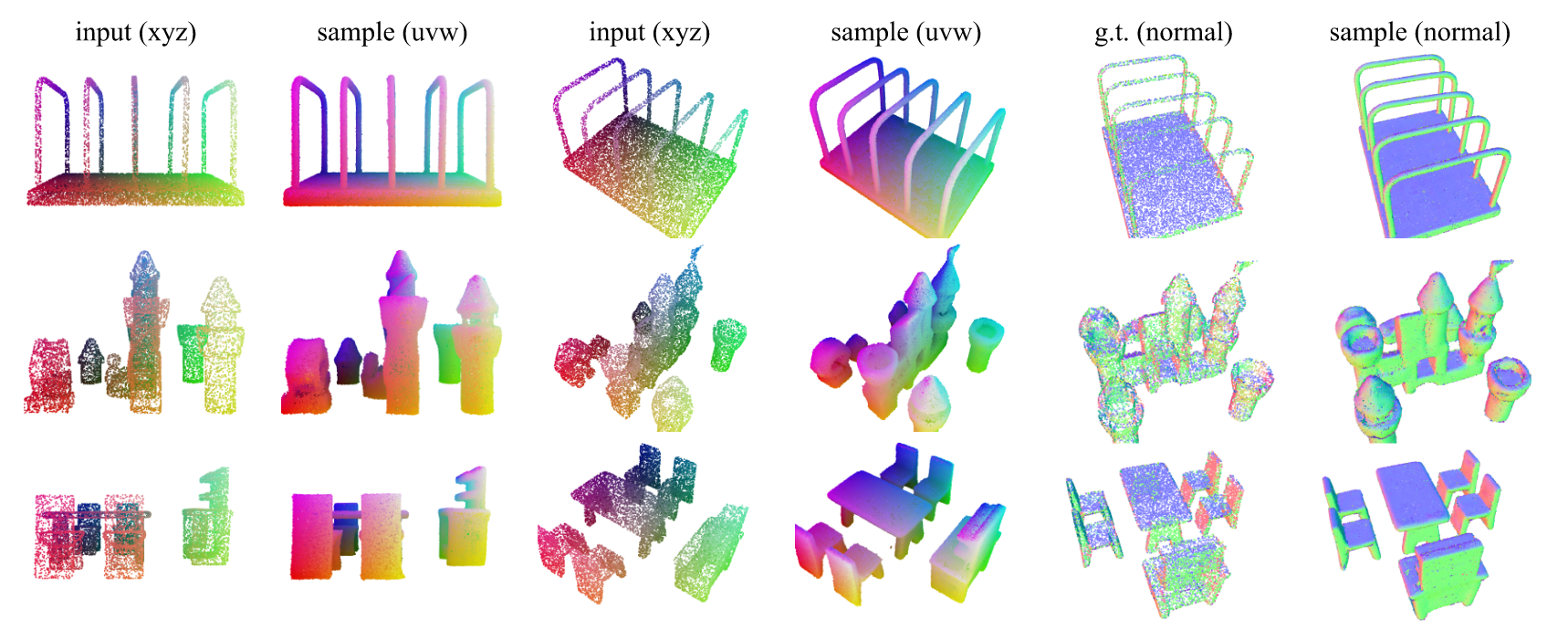
图3。GSO数据集中未见点云的重建、增密和法线估计。对于每一行,给定包含16,384个点(仅xyz)的点云,我们计算ST并从结果\(p(x\vert s)\)中独立同分布采样262,144个点。不同列从不同视角渲染输入和采样的点云。根据括号中的标签,我们根据其xyz坐标为输入点着色,并根据其初始噪声的uvw坐标和估计法线为采样点着色(最后两列)。请注意,我们没有向形状标记器提供法线作为输入。网格来源[23]。
我们在Objverse数据集中预留的600个网格以及整个谷歌扫描物体(GSO)数据集[23](包含1032个网格)上评估形状标记化器。我们从每个点云中无放回地采样\(16384 + n\)个点,其中16384个点用作标记化器的输入,\(n\)个点在计算倒角距离时用作参考。由于没有在Objverse上训练的公开可用基线,我们通过与从特定大小表面采样得到的真实点云进行比较来获得基线(在表2中显示为“Real”)。当点的数量与参考点云相同时,它提供了性能的上限;当点的数量比参考点云少时,我们有放回地随机采样以匹配参考点云中的点数量。这提供了一个强大的基线,因为所有点都是真实的且位于表面上。从表2和图3可以看出,形状标记化能够很好地重建三维形状,我们观察到与上限接近的倒角距离,并且增加形状标记(ST)的维度可以改善倒角距离。
4.2 分析
我们分析形状标记化的特性——使用流匹配将三维形状建模为概率密度函数。
表面法向量
首先,我们说明流匹配速度与表面法向量之间的联系。具体而言,由于\(p(x\vert \mathcal{S})\)是一个三维狄拉克函数,得分函数\(\nabla_x \log p(x\vert \mathcal{S})\)的方向与表面法向量一致。我们使用Ma等人[52]推导的公式将速度转换为得分函数,得到:
\[\hat{n}(x)=\frac{\nabla_x \log p_1(x\vert s)}{\|\nabla_x \log p_1(x\vert s)\|}=\text{normalize}(\alpha_1 v(x; t \to 1)-\dot{\alpha}_1 x) \tag{9}\]该表达式促使我们选择广义方差保持路径(\(\alpha_t = \sin(\frac{\pi}{2}t)\)且\(\sigma_t = \cos(\frac{\pi}{2}t)\))[2, 52],这样\(\dot{\alpha}_1 = 0\),并且当\(t = 1\)时,解码器可直接估计法向量方向。
表2。Objaverse和GSO数据集上的重建误差。Chamfer距离单位为\(10^{-4}\),参考点云被归一化到[-1, 1]。
我们利用这一特性来估计采样点处的表面法向量。表2展示了采样点处估计的法向量与真实法向量(真实点云中最近点的法向量)之间的夹角。请注意,采样点可能并不完全位于表面上。我们的基线方法是使用Open3D[91]通过局部拟合平面,从真实点云中计算顶点法向量。在获取没有顶点法向量的点云时,这是一种标准方法,也是一个强大的基线。从表中可以看出,对整个三维形状进行建模使得形状标记(ST)在点数量较少时,性能优于强大的真实基线。
对数似然
我们使用流匹配的公式能够利用变量的瞬时变化[15],来计算在任意三维位置处的精确对数似然\(\log p(x\vert s)\),这使我们能够通过对常微分方程(ODE)进行积分,来估计\(x \in \mathcal{S}\)的概率。由于我们的分布是三维的,我们可以通过自动微分以较低的计算成本来计算精确的散度,而无需像Song等人[72]那样使用迹估计器。
在任意位置评估对数似然的能力,对于去除噪声点很有用,例如,由于常微分方程积分使用的步数有限而产生的噪声点。我们还注意到,在实际应用中,通过使用少得多的步数(例如25步)对用于对数似然估计的常微分方程进行积分,我们就能得到对数似然的良好估计。在本文中,我们使用该技术来过滤从\(p(x\vert s)\)采样得到的点云,以去除在对\(p(x\vert s)\)进行采样时,由于常微分方程的数值积分而产生的离群点/噪声点。关于过滤前的点云,请查看补充材料。
UVW映射
由于我们的速度估计器是一个神经网络,因此在\(x\)上一致满足利普希茨连续,在\(t\)上连续,常微分方程(ODE)具有不相交的积分轨迹,并且在初始噪声空间和三维形状空间之间存在双射映射[15]。这意味着,对于三维空间中的任意三维位置(即\(xyz\)坐标),我们可以沿着常微分方程轨迹(2)回溯到初始噪声三维空间中的唯一位置(我们称之为\(uvw\),以区别于\(xyz\))。
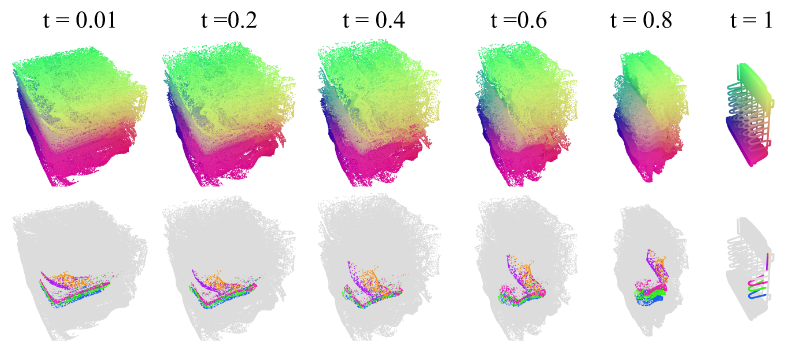
图4。ODE积分轨迹定义了从xyz(数据)到uvw(噪声)的映射。网格来源[23]。
此外,由于轨迹不相交,映射变化平滑。受此特性启发,我们选择在\([-1, 1]\)内的均匀分布作为初始噪声分布\(e(\epsilon)\)。这使我们能够将每个\(xyz\)坐标映射到\(uvw\)立方体中的一个位置。图4展示了一个示例。我们还利用这一特性,根据采样点云的初始\(uvw\)位置对其进行着色(\(rgb = (uvw + 1)/2\))。从图中可以看出,\(uvw\)映射在\(xyz\)空间中变化平滑。我们认为\(uvw\)映射是一个有趣的特性,值得在本文中提及,因为它是通过形状标记化自动发现的,并且类似于用于纹理插值的UV映射技术。
5 实验
我们将ST应用于三个任务中表示3D:3D形状生成(单图像到3D或无条件生成)(第5.1节)、3D CLIP(第5.2节)和神经渲染(第5.3节)。我们的目标是展示ST带来的多种能力,并进一步激发未来的工作。在所有任务中,ST与为每个任务专门设计的模型相比,均表现出竞争力。
5.1 基于潜在流匹配的标记生成
表3。ShapeNet上的无条件生成。对于MMD-CD,单位为\(10^{-3}\),对于MMD-EMD,单位为\(10^{-2}\)。
表4。Objaverse上的单图像条件生成。
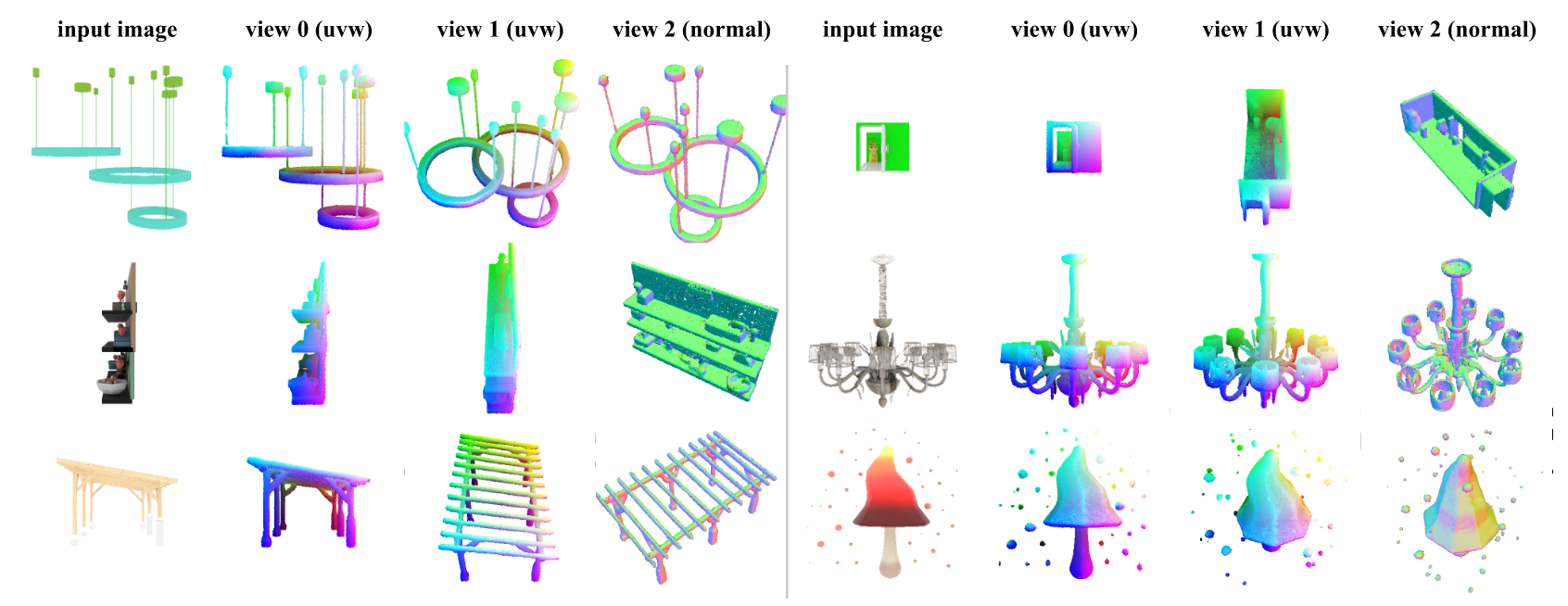
图5。Objaverse中未见网格的单图像到3D点云结果。我们使用RGB颜色为点着色,表示点在初始噪声空间中的原始位置。网格来源[4, 8, 25, 26, 29, 71]。
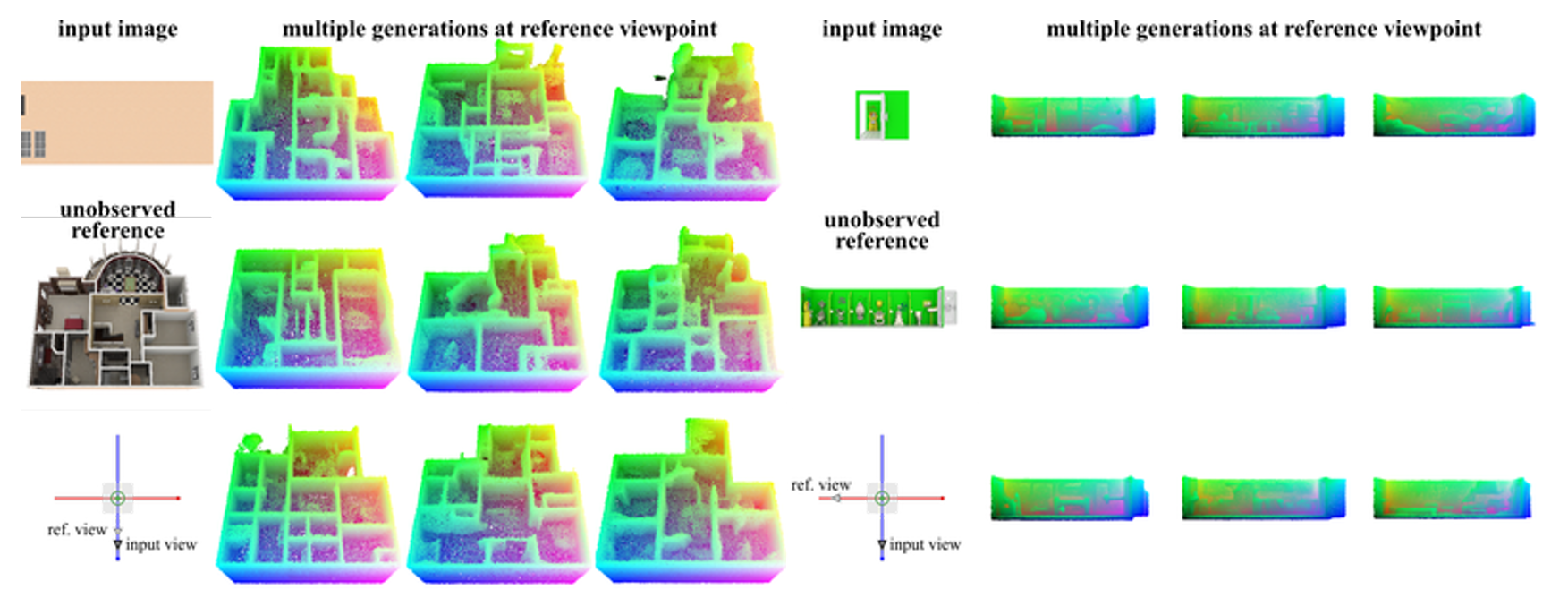
图14。我们从同一图像独立生成9个点云。我们提供网格在相同视角下的渲染图像作为参考。请注意,模型未观察到参考图像。网格来源[1, 7]。
为了证明ST与生成模型的兼容性,我们训练了生成ST的潜在流匹配(LFM)模型。我们在ShapeNet数据集(55类)[12]上训练了一个无条件LFM,并在Objaverse数据集[20]上训练了一个图像条件LFM。我们使用与第4节中训练相应形状标记器时相同的训练分割。我们基于Diffusion Transformer架构(DiT)[60]构建了速度估计器,使用AdaLN-single[14]和SwiGLU[69]。对于图像条件模型,我们使用DINOv2[59]提取每个非重叠块的图像特征,并使用傅里叶位置嵌入和Plucker射线嵌入[62]分别编码块中心射线的原点和方向。我们还学习了一个线性层以从图像块中提取额外信息。DINO特征、线性层的输出以及每个块的射线嵌入沿特征维度连接形成向量\(c\)。在每个块中,交叉注意力层关注所有块的\(c\)以收集图像信息。对于Objaverse中的每个网格,我们渲染四张图像,每张图像的视场角为40度,分辨率为448×448,位于x和z轴相反两侧的3.5个单位处,朝向原点。我们使用AdamW优化器[48]训练模型,学习率为\(10^{-4}\),权重衰减为0.01。模型在ShapeNet上以批量大小128训练200k次,在Objaverse上以批量大小1024训练1.2M次。在采样过程中,我们应用Heun的二阶方法[36]对标记(250步)和点云(100步)进行采样。表3展示了ShapeNet上的无条件生成结果。我们与LION[77]和DPF[92]进行了比较。具体来说,LION是一个潜在扩散模型,它建模固定大小点集的联合分布,DPF是我们对[92]的实现,直接建模3D点的坐标。我们的模型采用维度为64的32个ST;它约有110M参数,与LION和DPF的规模相似。我们使用与Vahdat等人[77]相同的参考集测量最小匹配距离(MMD)、覆盖率(COV)和1-最近邻准确率(1-NNA)[85]。对于每种方法,我们在测试集中采样包含2048个点的点云,共1000个样本。可以看出,尽管我们的模型具有更紧凑的潜在空间,但其性能优于LION。我们的模型还与设计用于学习点分布而不需要单独学习编码器的环境空间模型DPF具有竞争力。表4展示了Objaverse上单图像条件生成的定量结果。由于Objaverse中对象的广泛多样性,我们使用ULIP-I[84]、P-FID[58]和P-IS[58]测量生成点云的质量。我们使用Nichol等人[58]提供的PointNet++测量P-FID和P-IS,这些指标用于评估点云的质量。我们使用ULIP-2[84]提取点云嵌入,并测量与条件图像的CLIP嵌入的余弦相似度。这评估了生成的点云与输入图像之间的相似性。我们的LFM模型生成维度为1024×16的ST。从表中可以看出,我们的模型与现有基线相比表现强劲。图5展示了我们单图像到点云结果的示例。我们的模型生成的点云与条件图像高度相似,并具有合理的3D形状。此外,如图14所示,当条件模糊时(例如,条件图像中不可见的表面),我们的模型生成多样化的样本。例如,模型生成不同布置的房间和不同姿态的佛像。更多生成点云的视频请参见补充材料。
5.2 3D CLIP
表5。零样本文本分类。第一行块展示了使用联合训练的PointBERT编码器的OpenShape与使用ST + MLP编码器的OpenShape之间的比较。第二行块包括其他当前方法作为参考。
3D-CLIP旨在将形状嵌入与预训练CLIP模型[33]的图像和文本嵌入对齐。形状编码器以点云作为输入并输出嵌入。我们将现有3D-CLIP管道OpenShape[44]的形状编码器替换为我们的形状标记器(1024×16)和一个MLP。该MLP将拼接后的ST作为输入向量,具有4层特征维度为4096的隐藏层,最后一层线性层输出维度为1280的嵌入。需要注意的是,我们只训练MLP,因此能够使用较大的批量大小(每个GPU 600个)。我们使用与OpenShape相同的训练配方和数据集。我们训练了两个模型,一个在Objaverse和ShapeNet数据集上训练,另一个额外在3DFUTURE[27]和ABO[19]上训练。我们使用与OpenShape相同的文本描述。模型使用8个A100 GPU训练了2周。表5展示了使用学习到的形状嵌入进行零样本文本分类的结果。可以看出,使用ST作为3D表示的模型与使用专门训练的PointBert编码器的OpenShape性能相当。我们注意到,在训练2天后,ModelNet-40上的准确率达到了83.3%,之后开始下降,而Objaverse-LVIS上的准确率在整个训练期间持续增加。由于ModelNet40不是训练集的一部分,这表明Objaverse-LVIS和ModelNet40之间存在分布不匹配,我们认为对这一观察的深入分析超出了本文的范围。
5.3 神经渲染
表6。Objaverse未见形状上的射线形状相交结果。
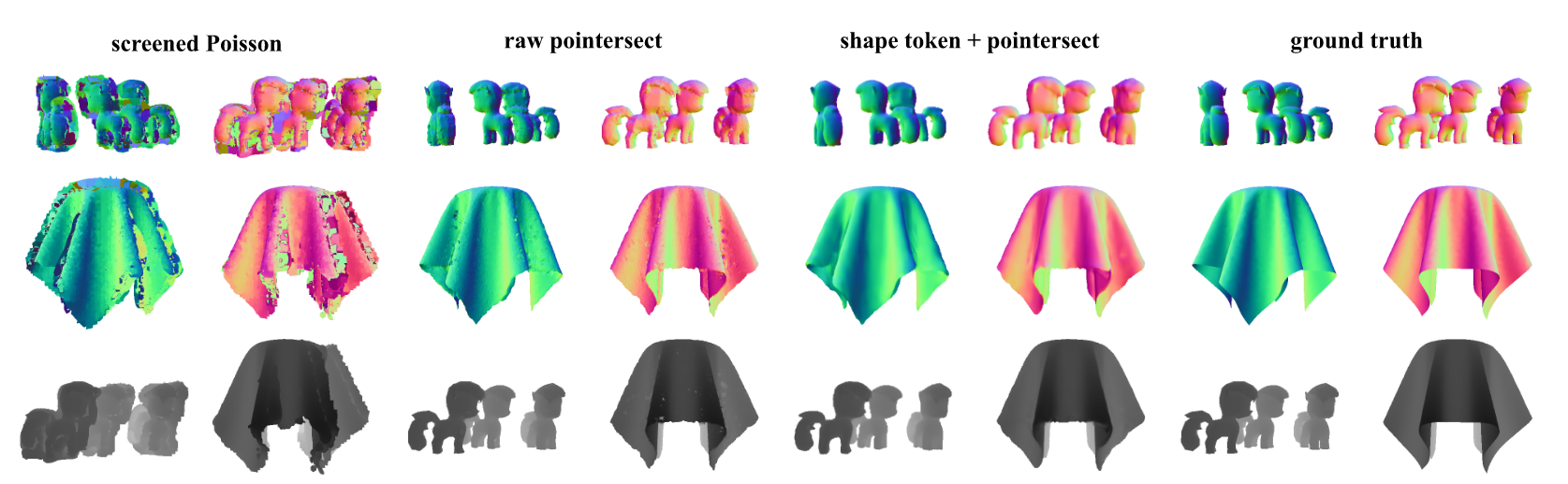
图7。给定包含16,384个点(仅xyz)的点云、相机姿态和内参,我们独立处理与每个像素对应的射线,并栅格化深度(底行)和法线(顶两行)图图像。网格来源[10, 68]。
射线与形状的相交是图形学中的重要操作。我们展示了估计射线与由ST表示的底层3D几何体之间交点的能力。我们采用现有方法Pointersect[13],该方法使用输入点云和射线作为transformer的输入来估计交点,并使用ST表示输入点云。具体来说,我们训练了一个由4个交叉注意力层块组成的transformer,每个块与一个2层MLP配对。交叉注意力将单条射线的Plucker嵌入作为查询,并关注ST。换句话说,每条射线被独立处理。最后一层线性层输出射线是否击中任何表面的估计、射线到第一个交点的传播距离以及表面法线。给定相机姿态和内参,我们独立处理与每个像素对应的射线,并栅格化深度和法线图图像。结果如表6和图7所示。使用ST作为其3D表示,模型能够估计更平滑的法线图,对点云的局部变化具有鲁棒性。
6 讨论
形状标记化是一种新颖的数据驱动的3D形状表示方法。它与大多数现有的3D表示方法(如显式建模几何的网格、SDFs或渲染公式的3D高斯、NeRF)处于光谱的相反端。尽管其动机源于机器学习,但我们展示了Shape Tokens具有与3D几何紧密相关的属性,如表面法线和UVW映射。形状标记化以及流匹配与3D几何之间的联系为3D表示提供了一个有趣且新颖的视角。在多个下游任务中,Shape Tokens展示了与特定任务表示相竞争的性能。
局限性。当前的Shape Tokens仅考虑几何;扩展到颜色是未来的工作。在采样点云、形状标记或计算对数似然时,我们需要集成ODE,这意味着生成点云的时间比前馈方法更长。利用蒸馏方法或扩散模型的改进来提高采样效率也是未来的工作。
附录
A. 附录总结
在补充材料中,我们展示了以下详细内容:
-
Objverse测试集上的单图像到三维结果视频(见index.html)。
-
谷歌扫描物体上的单图像到三维结果视频(见index.html)。我们还与近期的单图像到三维方法进行了比较,包括Point-e[58]、Splatter-image[74]和Make-a-Shape[32]。
-
谷歌扫描物体中点云的重建、 densification(加密,这里可能是专业术语,按原文保留)和uvw-xyz变形视频(见index.html)。
-
来自同一输入图像的多个独立样本视频(见index.html)。
-
从线性插值形状标记采样得到的点云视频(见index.html)。
-
神经渲染结果视频(见index.html)。
-
点云过滤结果。
-
单图像到三维的缩放实验。
-
形状标记化器的架构和训练细节。
-
运行时间分析。
B. Objverse数据集上的单图像到三维转换
在随附的离线网站中,我们展示了超过100个Objverse测试集上的单图像到三维转换结果视频。在这些视频中,我们首先展示输入图像,然后是从输入视角下采样的形状标记中采样得到的点云。最后,我们旋转视角。从视频中可以看出,我们的结果在输入视角下与输入图像紧密匹配,并且从其他视角看时具有合理的三维结构。在这些结果中,使用Heun方法分250步对形状标记进行采样,使用Heun方法分100步对点云进行采样。我们使用无分类器引导,引导尺度为5。
C. 谷歌扫描物体(GSO)数据集上的单图像到三维转换

图8。Google Scanned Objects上的单图像到3D结果(1/3)。每行块展示了从同一输入图像生成的相同3D表示的不同视角。

图9。Google Scanned Objects上的单图像到3D结果(2/3)。每行块展示了从同一输入图像生成的相同3D表示的不同视角。

图10。Google Scanned Objects上的单图像到3D结果(3/3)。每行块展示了从同一输入图像生成的相同3D表示的不同视角。
在随附的离线网站,以及图8、图9和图10中,我们展示了20多个谷歌扫描物体(GSO)数据集上的单图像到三维转换结果。我们还展示了使用相同输入图像的近期单图像到三维转换方法的结果:
-
Point-e[58],在一个包含数百万个网格的专有数据集上进行训练。它首先生成1024个点,然后使用另一个模型上采样到4096个点。它对固定数量点的点集联合分布进行建模,无法采样任意数量的点。
-
Splatter-image[74],这是一种近期的方法,将图像作为输入并预测表示场景的三维高斯散点。它还对RGB颜色进行建模。该模型在Objverse数据集上进行训练。与Splatter-image同一研究路线的近期方法[42, 81]通常使用额外的多视图图像扩散模型从单张图像生成多视图图像,然后将多视图图像应用于一个类似于Splatter-image的模型来构建三维高斯散点。我们认为Splatter-image在不使用额外图像扩散模型的情况下,合理地展示了这种方法的性能。
-
Make-a-Shape[32],这是一种近期的方法,使用打包和修剪后的小波系数来表示带符号距离函数的体素网格。通过学习一个扩散模型,根据单张图像生成这种表示。该模型在来自18个数据集(包括Objverse)的超过1000万个网格上进行训练。
我们展示这些结果供读者参考,并且想要强调的是,这些结果并非用于直接比较。这些模型的训练数据不同(例如,Point-e在专有数据集上训练),底层机制也不同(例如,Splatter-image不是生成模型,而我们的模型假设输入相机参数已知)。总的来说,我们发现很难对图像到三维的方法进行完全公平的比较。我们希望我们发布的代码和模型能够有助于改善这种情况。
在这些结果中,使用Heun方法分250步对形状标记进行采样,使用Heun方法分100步对点云进行采样。我们使用无分类器引导,引导尺度为5。
D. 谷歌扫描物体(GSO)数据集上的重建和加密
在随附的离线网站中,我们展示了超过20个从谷歌扫描物体(GSO)的输入点云计算得到的形状标记中采样的点云视频。输入点云包含16,384个点,我们采样262,144个点(16倍)以展示加密能力。我们还根据点云在噪声空间(uvw)中的初始坐标对其进行着色,以展示从噪声空间(uvw)到环境空间(xyz)的变形轨迹。可以看出,这些轨迹在三维空间中平滑变化。
E. 同一图像的多个样本
在随附的离线网站中,我们展示了从同一输入图像独立采样的形状标记中采样得到的点云结果。输入图像来自Objverse测试集。可以看出,当输入图像不明确时,该模型能够生成多样化的样本,同时与输入图像匹配。在这些结果中,使用Heun方法分250步对形状标记进行采样,使用Heun方法分100步对点云进行采样。在这些示例中,我们未使用无分类器引导。
F. 形状标记的线性插值
出于好奇,我们对由两个不同形状计算得到的形状标记进行线性插值。具体来说,给定两个形状标记\(s_1\)和\(s_2\),我们计算一系列形状标记:
\[s(w) = (1 - w)s_1 + ws_2, \tag{10}\]其中\(w\)的取值范围是从0到1。我们从得到的形状标记中,使用相同的初始噪声(根据其uvw坐标着色)采样点云,并制作了视频,可在随附的离线网站查看。
G. Objverse数据集上的神经渲染结果
在随附的离线网站中,我们展示了对Objverse测试集的输入点云进行神经渲染得到的法向量图结果。我们还展示了筛选泊松重建方法[37]和Pointersect方法[13]的结果。筛选泊松重建首先从输入点云中重建一个网格,然后渲染法向量图。由于输入点云不包含顶点法向量,我们使用Open3D通过计算局部点云的主成分来估计顶点法向量。筛选泊松重建对顶点法向量的质量很敏感。我们使用Open3D中深度为7的筛选泊松重建实现,并去除密度处于最后5%分位数的顶点。根据经验,我们发现在我们的实验中这些设置能产生稍好的结果。
Pointersect是一种神经渲染方法,它以目标光线和一个输入点作为输入,估计光线与点云所表示的底层形状之间的交点。我们发现它在渲染的法向量图中保留了高频细节,但它对输入点云也很敏感,因此其结果通常包含高频噪声。我们的神经渲染模型以目标光线和从输入点云计算得到的形状标记作为输入,并估计光线与点云所表示的底层形状之间的交点。法向量估计对输入点的配置更具鲁棒性,然而,我们也观察到渲染的法向量图存在平滑现象 。
H. 点云过滤结果
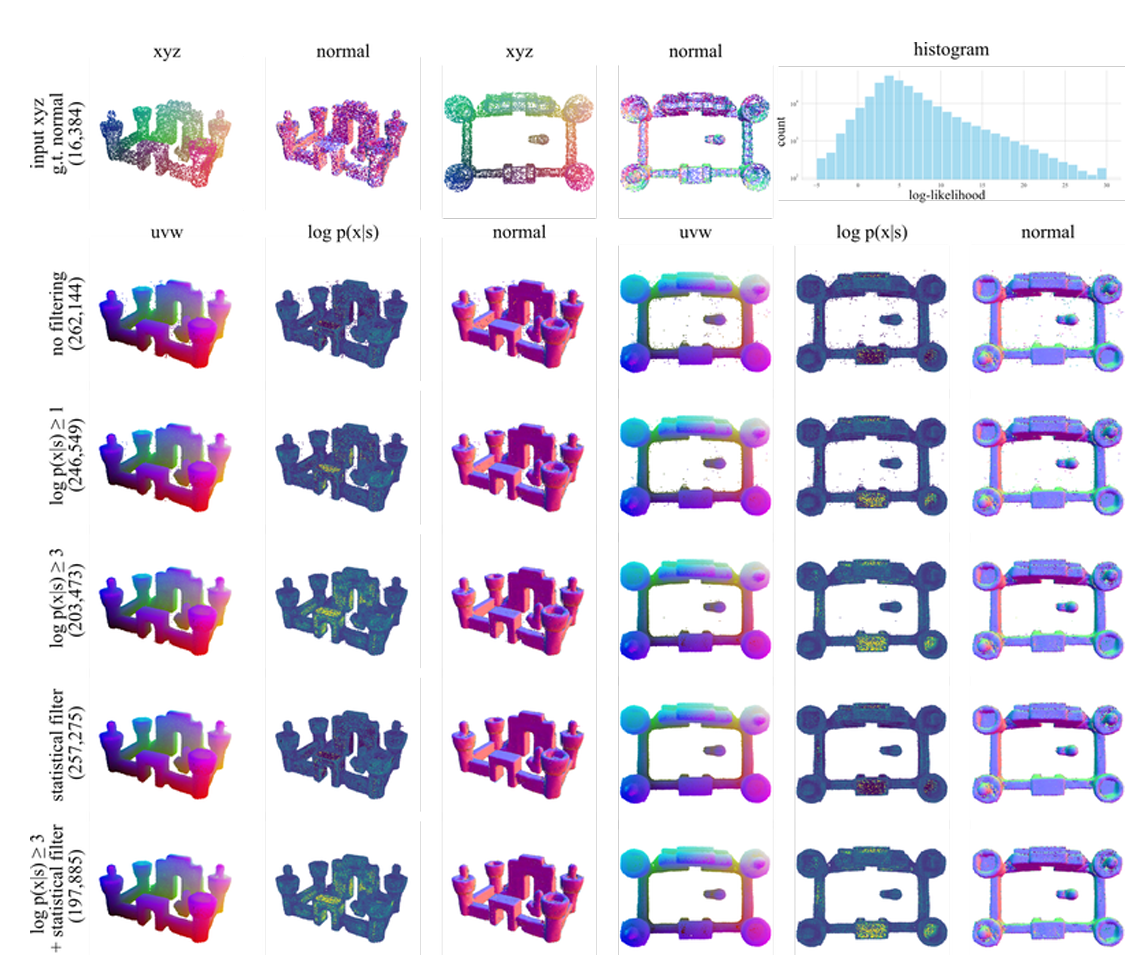
图11。使用对数似然去噪。我们从\(p(x\vert s)\)中采样262k个点。由于数值积分的误差,少量点包含噪声。我们为每个点计算精确的对数似然\(\log p(x\vert s)\),并使用这些值进行过滤。对数似然过滤是标准统计离群值过滤的补充,后者也能有效过滤噪声点。
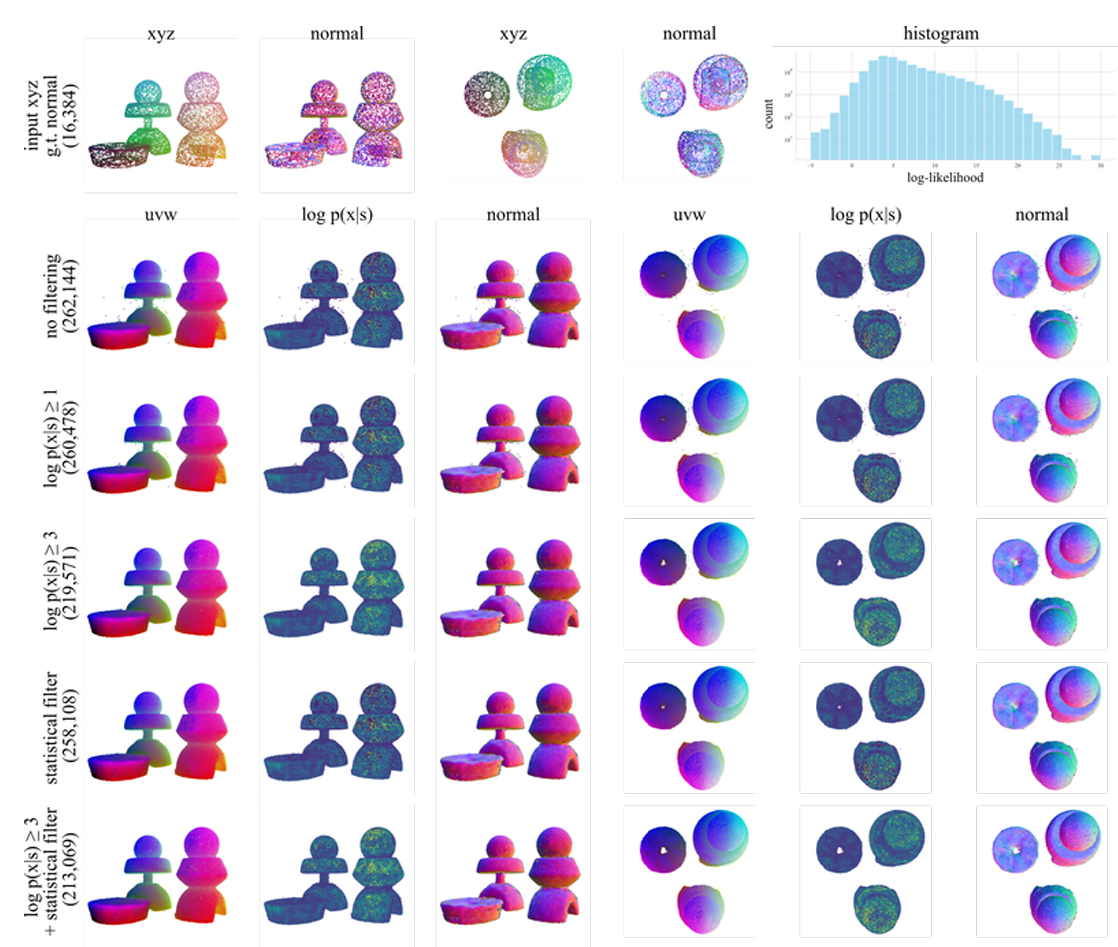
图12。使用对数似然去噪。我们从\(p(x\vert s)\)中采样262k个点。由于神经网络的有限容量和大量点,少量点包含噪声。我们为每个点计算精确的对数似然\(\log p(x\vert s)\),并使用这些值进行过滤。对数似然过滤是标准统计离群值过滤的补充,后者也能有效过滤噪声点。
在图11和图12中,我们展示了使用变量瞬时变化技术[16]计算的对数似然进行过滤前后的点云。在本文的结果中,我们使用有限步数(例如100步)对流匹配的常微分方程进行数值积分,采样包含超过20万个点的点云。由于我们在大量的点中独立地采样单个点,少数点可能因数值积分而产生误差。因此,积分后一些点可能偏离表面。我们注意到,可以用较少的步数(例如25步)计算采样点的对数似然,并通过对数似然阈值过滤采样点云。从图12的结果中可以看出(例如,俯视图中的中心孔),过滤是有效的,能够去除标准统计离群点去除方法无法去除的点。在本文的所有结果中,我们应用对数似然过滤去除对数似然最低的10%的点,然后使用邻域大小为3、标准差为2的统计离群点去除方法[91]。我们强调,过滤仅为了可视化,所有定量评估都是在未过滤的点云上进行的。
I. 单图像到三维的缩放实验

图13。ULIP-I余弦相似度:(a) 不同模型大小,(b) 不同潜在维度,(c) 不同CFG尺度。
在图13中,我们展示了在形状标记上训练的潜在流匹配模型(LFM)从缩放中受益,这与图像标记化器(例如,SD - VAE[67])类似。我们训练了不同规模的LFM:小(S)、基础(B)、大(L)和超大(XL)。如图13(a)和(b)所示,ULIP - I分数随着模型规模和形状标记维度的增加而提高。我们的模型也支持无分类器引导(CFG)。图13(c)展示了CFG缩放如何影响ULIP - I分数。
J. 形状标记化器的架构
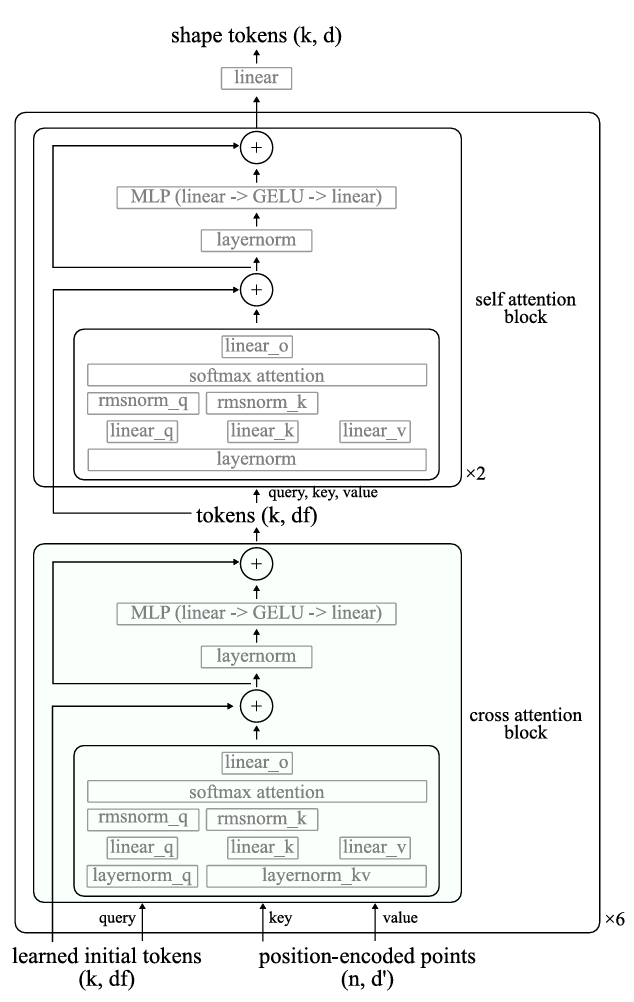
图15。形状标记器的架构。我们在Objaverse上的主模型使用\(n=16,384\),\(k=1024\),\(df=512\),\(d=16\),这导致5540万个可训练参数。对于在ShapeNet上训练的形状标记器,我们使用\(n=2048\),\(k=32\),\(df=512\),\(d=64\),导致5490万个可训练参数。所有多头注意力使用8个头。MLP中的线性层将特征维度扩展和收缩4倍。
形状标记化器的详细架构见图15。在Objverse数据集上训练的主要形状标记化器有5540万个可训练参数。我们使用傅里叶位置嵌入[78],其包含从\(2^0\)到\(2^{12}\)的32个对数间隔频率。我们通过改变最后一个线性层的维度来控制点云标记的维度。
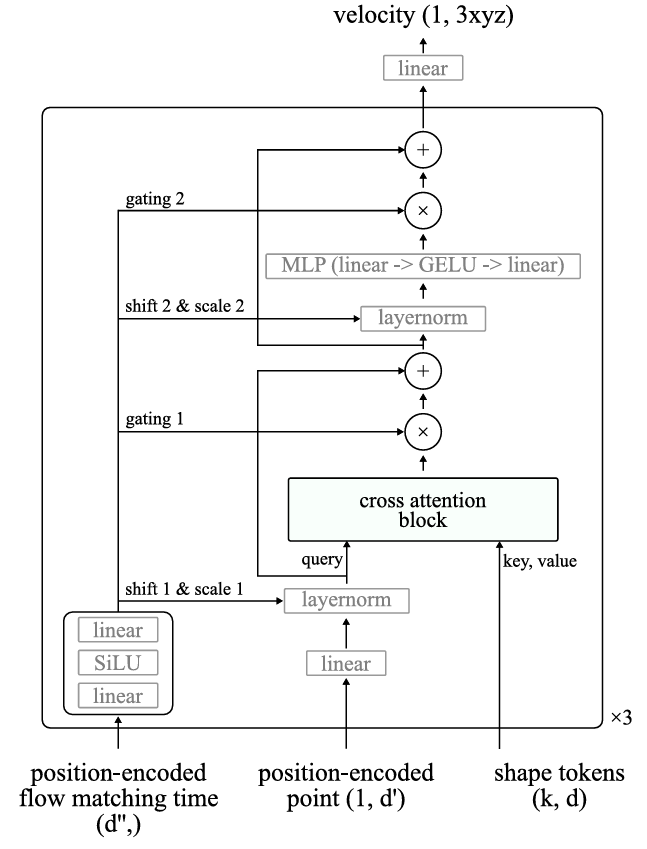
图16。形状标记化的流匹配速度估计器架构。模型使用特征维度512,多头注意力数量为8。MLP中的线性层将特征维度扩展和收缩4倍。Objaverse和ShapeNet模型的可训练参数总数分别为872万和887万。神经渲染模型使用相同的架构,但没有流匹配时间的自适应层归一化(即使用标准层归一化层)。它以编码射线作为输入,并重复块4次。
与形状标记化器配对的速度估计器的详细架构见图16。我们使用与形状标记化器中相同的傅里叶位置嵌入来编码输入的xyz坐标。我们先使用傅里叶位置嵌入,然后通过一个多层感知器(MLP)来编码流匹配时间。傅里叶位置嵌入使用从\(2\pi\)到\(2^{16}\pi\)的16个对数间隔频率,MLP有2个线性层(64维),并使用SiLU激活函数。
我们使用AdamW优化器[49]训练形状标记化器,其中\(\beta_1 = 0.9\),\(\beta_2 = 0.98\),不使用权重衰减。我们采用Vaswani等人[78]使用的学习率调度,预热期为4000次迭代。在预热迭代期间,学习率增加到\(2.8\times10^{-4}\),之后逐渐减小。我们在32个H100 GPU上训练形状标记化器200小时(120万次迭代)。由于每个点云包含大量\(p_{\mathcal{S}}(x)\)的独立同分布样本,我们未观察到过拟合现象。
神经渲染模型使用与上述流匹配速度估计器相同的架构。该模型没有自注意力模块,它独立处理每条光线。我们去掉了结合流匹配时间的自适应层归一化(即,使用标准层归一化层)。它以编码后的光线作为输入,并重复模块4次。光线被编码为光线起点和方向。光线起点的坐标使用与上述相同的傅里叶位置嵌入进行编码。方向使用普吕克光线表示法[62]进行编码。此外,我们在\([-1, 1]\)的立方体区域内的光线上均匀采样32个点(若光线起点在立方体内,则仅在起点之后采样)。根据经验,我们发现这能稍微提高光线命中的估计效果。我们在32个A100 GPU上训练该模型250小时(88万次迭代)。
K. 运行时间分析

表7。运行时间(以秒为单位)。
在表7中,我们报告了以下操作的运行时间:(a) 从16384个输入点计算形状标记;(b) 用100步欧拉法从形状标记中采样16384个点;(c) 用100步欧拉法对图像条件下的潜在流匹配模型进行采样;(d) 从单张图像生成包含16384个点的点云的总时间。我们在不同的硬件组合(H100、A100)和浮点精度(bfloat16、float32)下测量运行时间。将点云编码为形状标记的速度很快(例如,在A100上使用bfloat16时为25毫秒),因为这是一个前馈模型。采样点云或形状标记需要进行数值积分,并且要多次调用流匹配模型。在这些设置下,使用H100和bfloat16从单张图像生成一个点云需要超过7.5秒。通常,在减少步数、数值积分方法(如一阶、二阶等)、运行时间和生成质量之间存在权衡。利用扩散模型加速方面的进展是未来的工作。
评论